Redis笔记,涵盖了 Redis 所有知识点,拿走不谢

一、redis为什么那么快
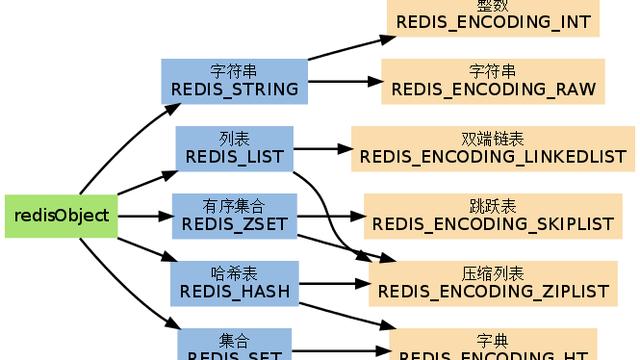
二、redis数据类型- String,常见的缓存,存储登录session等
- hash,存储对象,单独修改对象属性
- List,有序列表,可实现简单的消息队列,阻塞队列
- Set,分布式去重
- Zset,也叫做sorted set,有序集合,关联一个double类型的分数,根据分数排序,可实现排行榜、延时队列
- Stream,redis 5.0后的新数据类型,消费者可分组,一条消息只能被同组的一个消费者消费,但可以被不同组的多个消费者重复消费,借此实现可持久化的发布&订阅功能
- Cache Aside Pattern
- 应用程序同时对接缓存、数据库
- 查询时先查询缓存,缓存未命中则查询数据库,同时更新数据库
- 更新时先更新数据库,在删除缓存缓存
- 最常用的模式
- 会有数据不一致性问题
- 适用读多写少的场景
- 两种加载缓存的方式,读到再加载,或者启动时就加载
- 为什么是先更新数据库再删除缓存,而不是先删除缓存再更新数据库?
- 为什么是更新数据库后删除缓存,而不是更新缓存?
- Read/Write Through Pattern
- 应用程序只对接缓存,由缓存对接数据库,相当于Cache Provider中封装了数据库
- 查询时若缓存未命中则,则Cache Provider去查询数据库,设置到缓存后再返回
- 更新时,由Cache Provider同时更新缓存和数据库,这里有事务保证
- 此模式很耗时,但能保证数据一致性
- 少见的模式
- Write Behind
- 应用程序只更新缓存,不直接更新数据库
- 在一定时间触发异步的方式写入数据库
- 类似于MySQL InnoDB 缓冲池的模式
- 在写入数据库前断电挂机会有丢失数据可能
- 放大了数据不一致性,但速度很快
- 适用于高并发写,但对数据一致性要求不高且允许丢失的场景
电商首页热点数据会做缓存,定时任务刷新,所有key失效时间一样。
热点key大面积集中失效,大量请求一下子打到数据库,导致数据库挂掉。
- 失效时间加随机值,不让它们集中失效
- 设置热点key永不过期,有更新时就更新缓存
- 如果Redis是集群部署,可让热点key分布在不同的Redis库中
缓存和数据库中都不存在的数据,被攻击者利用,如id = -1,发起攻击的时候会绕过换过,不断查询数据库。
- 对参数合法性进行检验
- 使用布隆过滤器,会有一定误判
- 数据库查询为null时,可以缓存约定的数据,如“请稍后重试”,缓存时间设置短点,如30秒(防止正常了这个id下有数据了也无法正常使用)
- 限流
一个热点key,在失效的瞬间,遭遇高并发,大量请求在缓存中查不到,会直接去查数据库
- 设置热点key永不过期
- 使用分布式互斥锁,保证在缓存失效时,只有一个请求能查到数据库
数据一致性就是指数据库和缓存的数据一致的问题。
根据三种缓存模式可知,在数据一致性和效率是两个极端,只能取一个中间平衡点。
一般是采用旁路缓存模式,且采用先更新数据库,后删除缓存的方式。
但就这时候还是会有少量请求因为删除缓存不及时而读到旧数据,不过一般都能顺利删除缓存,这已经是对业务影响最轻的做法。
这时候如果允许短期的数据不?致不会影响业务,那么只要下次更新时可以成功,能保证最终?致性就可以,那么可以不用再做处理。
如果还要再完美,可以捕捉删除缓存异常增加重试,对耗时敏感的可以进行异步补偿重试,即放到mq里面监听,但是这样对业务侵入性比较大,也可以采用监听MySQL binlog日志的方式进行重试。
十、布隆过滤器

原理:
一个元素被加入到集合时,通过k个哈希函数将这个元素映射成一个位数组中的k个点,把它们设置为1。
检索时,看这些位置是不是为1就知道这个元素在不在集合中了,如果都是1则可能存在,如果有一个是0则一定不存在。
缺点:
- 存在误判的肯定,可通过建立白名单来存储误判的元素
- 删除困难,初始化要把所有合法元素加到过滤器中,删除时设置为0可能会影响其他元素的判断,可通过Count Bloom Filter
- 使用zookeeper分布式锁保证线程安全
- 如果也要更新数据库,涉及到双写,就会出现数据一致性问题,可以参考上面的删除key
- 如果不能删除key,则在更新缓存时比较数据的更新时间
- 记录内存快照的方式
- 使用bgsave,fork一个子进程进行,不会阻塞set操作,类似于GC的守护进行
- Copy On Write,写时复制机制,备份的时候发生写入操作,则备份的是写入之前的数据,所以会有数据丢失
- 定期进行,一般是5分钟一次,断电可能会丢失较多数据
- 恢复块、备份久
- 可能把RDB快照文件定期放到远程存储,一般做冷备
- RDB备份的文件体积小,恢复很快
- 日志追加的方式,类似于MySQL innoDB引擎中redo.log,备份当前操作命令
- 恢复慢、备份块
- 会不会丢失数据取决于Appendfsync配置,配置为实时备份则每次写操作都会备份,性能低,一般是配置为每秒一次,这样最多是丢失一秒的数据
- 适合做灾备
- 随着时间增长,AOF文件会越来越大,Redis提供了日志重写功能,可以压缩命令,重写后新的AOF文件仅包含旧AOF文件命令的最小集合
- AOF备份的文件体积大,即使经过重写,仍然很大,恢复很慢
Redis 4.0后使用了RDB+AOF混合持久化模式,生成RDB文件重新记录,这时AOF日志不再是全量的,而是增量的日志记录,体积很小。
十四、Redis过期策略
Redis需要删除失效的数据以清空内存,过期策略就是怎么删除过期数据。
- 定期删除:默认每隔100ms随机抽取部门设置了过期时间的key,检查key是否失效,失效了就删除。(不全部检查是因为效率低,类似于MySQL全表扫描)
- 惰性删除:当应用程序来查key的时候,检查到key失效就会删除,未失效就返回。
Redis使用定期删除+惰性删除,能保证最终一定会删除过期的key,但是定期删除会有漏网之鱼,而应用程序又很久没来查询就会导致长时间滞留在内存之中,这时需要用到内存淘汰机制。
十五、Redis内存淘汰机制
FIFO:First In First Out,先进先出
LRU:Least Recently Used,最近最少使用,从时间上看很久没有使用的被淘汰
LFU:Least Frequently Used,最不经常使用,从次数上看使用得最少的被淘汰
- volatile-lru:将设定了超时时间的数据,采用LRU算法将数据提前删除
- allkeys-lru:对所有的数据采用LRU算法进行删除
- volatile-lfu:设定超时时间的数据采用LFU算法删除
- allkeys-lfu:对所有数据采用LFU算法删除
- volatile-random:设定了超时时间的数据随机删除
- allkeys-random:所有数据随机删除
- volatile-ttl:设定了超时时间的数据根据剩余时间少的删除数据
- noeviction:不删除内存数据,如果内存溢出报错返回(默认策略)
全量同步主要发生在Slave初始化阶段,当启动一台Slave时,它需要连接到Master,把Master数据都复制一份。
- Slave连接上Master,发送sync命令给到Master。
- Master执行bgsave,按照全量备份方式生成一份RDB快照,并用内存缓冲区记录此后执行的所有写命令。
- Master向Slave发送RDB快照。
- Slave收到RDB文件后,丢弃所有旧数据,并载入收到的快照文件。
- Master发送完RDB快照就接着发缓冲区中的写命令。
- Slave载入完RDB快照,就开始接收&执行Master发送过来的写命令。
Master每执行一个写命令就会向Slave发送相同的写命令,Slave接收&执行收到的写命令。
十八、Redis主从复制

主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis策略是,无论如何,首先会尝试进行增量同步,如不成功,再要求从机进行全量同步。
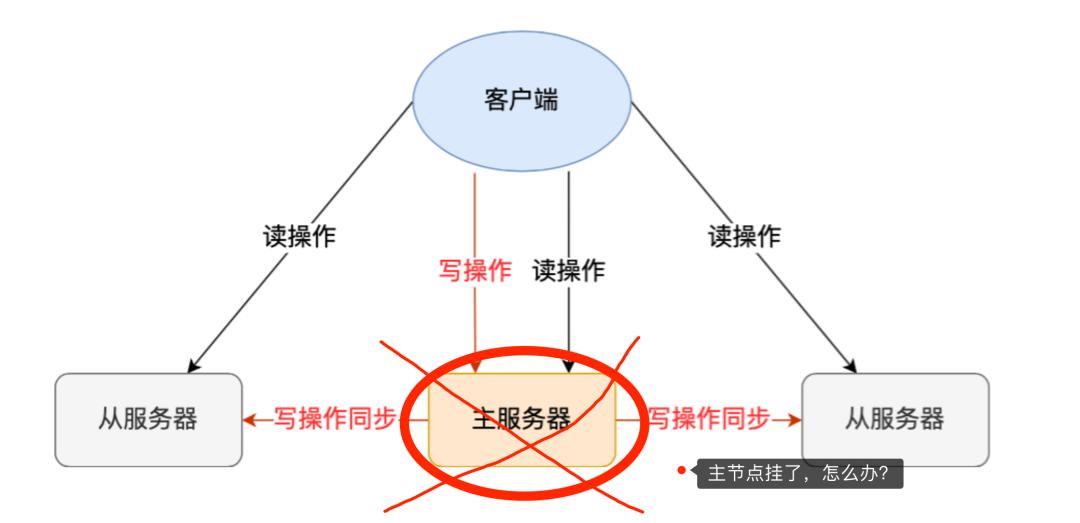
主从复制,只是实现了容灾备份,不能故障转移,不是实现高可用。
十九、Redis高可用方案A:哨兵模式+主动复制

哨兵是什么?
- 哨兵是一个独立的进程。
- 哨兵的作用主要有两个,A:通过心跳机制监控Redis服务器运行状态,包括Master和Slave。B:当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的哨兵、slave,修改配置文件,让它们切换主机。
- 当一个哨兵监测到Master宕机,系统并不会马上进行故障切换,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为“主观下线”。
- 当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行故障切换。
- 切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为“客观下线”。
- 优点:实现了容灾备份和自动故障切换,是高可用方案。
- 缺点:不好在线扩容(Slave可以随时配置多个,提高读并发,但Master只有一个,提高不了写并发),配置麻烦,只有一个主节点对外提供服务,没法支持很高的并发量。

Redis集群是一个由多个主从节点群组组成的分布式服务集群,他具有复制、高可用、分片特性,Redis集群不需要sentinel哨兵,也能完成节点移除和故障转移的功能,需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展;Redis集群的性能和高可用均优于之前版本的哨兵模式,且集群配置非常简单。
故障切换过程是怎么样的?
- Redis的所有节点都会保存当前redis集群中的全部主从状态信息,并且每个节点都能够相互通信。
- 当一个节点发生宕机,则集群中的其他节点通过心跳机制检查Redis节点是否宕机。
- 当有半数以上的节点认为宕机,则认为主节点宕机,同时由Redis剩余的主节点进入选举机制,投票选举链接宕机的主节点的从机,实现故障迁移。
- 集群中如果主机宕机,那么从机可以继续提供服务,当主机中没有从机时,则向其它主机借用多余的从机,继续提供服务,如果主机宕机时没有从机可用,则集群崩溃。即:每个节点都至少保持是“一主一从”。

数据存储原理是什么?
- hash槽存储原理,所有的键根据哈希函数(CRC16[key]&16383)映射到0-16384槽内。
- 当向redis集群中插入数据时,首先将key进行计算.之后将计算结果匹配到具体的某一个槽的区间内,之后再将数据set到管理该槽的节点中。

二十一、keys命令
- keys命令可以列出所有符合给定模式 pattern的key
- 单因为redis是单线程的,使用keys命令会导致线程阻塞一段时间,线上服务停顿,知道指令执行完毕,服务才能恢复,如列出10亿个相同前缀的key时,影响特别大。
- 可以使用scan指令代替,但会有一定重复,通过代码去重就好。
- 使用String类型缓存用户登录状态
- 使用Hash类型缓存一张配置表、字典表
- 使用setnx+expire+Lua实现分布式锁
- 使用List类型实现高性能的分页(如文章的评论列表)、简单的消息队列功能
- 使用Set类型实现分布式全局去重
- 使用Zset类型实现热榜、排行榜、延时队列功能
- 使用pub/sub实现简单的发布&订阅功能(不可持久化)
- 使用Stream类型实现有消费组的发布&订阅功能(可持久化)
- 使用Bitmap(位图)实现签到、布隆过滤器功能
- 使用HyperLogLog实现的不精确的去重统计,如PV(页面访问)、UV(用户访问)
- 使用Geospatial保存地理位置,计算位置距离,实现附近的人功能
- 使用Pipeline(管道)把一批命令打包好发送到redis一次性执行,减少客户端与 redis 的通信次数来实现降低往返延时时间
- 使用Lua脚本保证原子性,实现秒杀场景扣除商品库存
- 使用Set类型实现标签系统