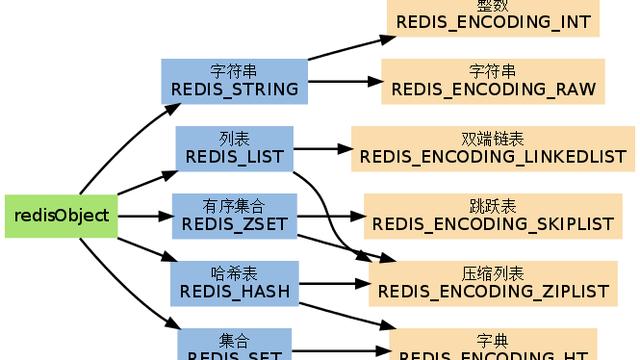
Redis底层字符串编码设计思想简介
本地调试redis源码
启动redis源码
mac下载C语言编译器CLion,拉取redis源码并导入CLion
编译redis源码并启动
编译成功之后,在src目录中就会出现可执行文件
启动redis-server
启动成功
在set方法中打个断点
redis的所有命令都在redisCommand里面定义,找到set命令,并找到对应的触点函数setCommand
在setCommand函数中打个端点
通过redis-cli执行set命令,就可以断点跟踪了
看下编码的过程
tryObjectEncoding
len是value的长度,长度小于等于20的话,才可以被转换成整数。
为什么整数范围最大是十进制数20?
在64位系统下C语言中的int还是占4字节,32位,与32位系统中没有区别!
64位操作系统下,采用64位编译器进行编译处理时,发生变化的变量类型是long。
32位系统下,long占4字节,32位,与int相同。
64位系统下,long占8字节,64位,有符号数取值范围是-9223372036854775808至9223372036854775807。
JAVA的long型整数最大值:9223372036854775807,即19位十进制数,64位二进制数,16位16进制数。
long占8个字节,64位二进制数,19位十进制数,算上符号的话就是20位十进制数。
如果value string可以转换成long,然后将value值赋值给redisObject的ptr指针,强制把整型值转换成指针类型,而不让ptr存内存地址,这样即节省了内存,还减少了一次内存io。
字符串编码
短字符串编码
短字符串(长度小于等于44)编码是embstr
长字符串(长度大于44)编码是raw
为什么是44?
要充分理解这个问题,需要先科普下cpu、地址总线、内存之间的关系:
- • 64位处理器比32位处理器速度更快
32位处理器一次性只能处理32位,也就是4个字节的数据,而64位处理器一次性能处理64位即8个字节的数据,64位处理器的处理速度比32位更快。
- • 64位处理器比32位能处理的地址范围更大
除了运算能力之外,与32位处理器相比,64位处理器的优势还体现在系统对内存的控制上。由于地址使用的是特殊的整数,而64位处理器的一个ALU(算术逻辑运行器)和寄存器可以处理更大的整数,也就是更大的地址。传统的32位处理器的寻址空间最大为4GB,而64位处理器在理论上则可以达到1800万个TB。
- • 地址总线
要存取数据或指令就要知道数据或指令存放的位置,地址寄存器存储的就是cpu当前要存取的数据或指令的地址,该地址是由地址总线传输到地址寄存器上的
假设地址总线有n位,即共有n位二进制位来表示地址,那么最多可以表示2^n个地址,另外计算机以一个字节为寻址单位,所以cpu的寻址能力或者最大的寻址范围是2^n个字节。综上,地址总线的位数决定了cpu的寻址能力。
- • 数据总线的宽度与字长及cpu位数
字长指cpu同一时间内可以处理的二进制数的位数,数据总线传输的数据或指令的位数要与字长一致。否则,如果数据总线长度大于字长则一条数据或指令要分多次传输,则分开传输几组数据也就没有意义;如果数据总线宽度小于字长,则cpu的利用率降低,对资源是种浪费。另外如果字长是n位,一般称cpu是n位的,所以说数据总线的宽度和字长及cpu的位数是一致的。
结合上面的问题,继续分析:
64位系统缓存行(字长)大小是64字节即64位处理器一次性读取64字节的缓存数据。基于缓存局部性原理,一次性要读取的数据不足64字节,也会顺便获取相邻的其他数据共64字节。
从内存中获取到redisObject对象之后,根据ptr指向的内存空间获取数据。
分析下这个redisObject对象占多少个字节:
type 4bit,encoding4bit,LRU_BITS占24bit即3字节,int类型的refcount占4字节,ptr指针类型占8字节,共16个字节,那么64字节的缓存行还剩48个字节的剩余空间,那么这48字节的缓存行空间存放什么呢?
存放redisObject ptr指针指向的内存空间的数据,即cpu一次性读取的64字节的缓存行中包含redisObject对象以及该对象ptr指针所指向的内存空间的数据,以免再根据redisObject的ptr指针再去内存中获取对应的数据,减少了一次内存io。
那48字节在哪个字符串类型的范围内呢?
sdshdr8 对应的字符串范围是32-64字节
c语言中的char类型占1个字节,java中的char类型占2个字节。
redis字符串为了兼容c语言函数库在末尾加上�的字符占1个字节。
uint8_t len 占一个字节,uint8_t alloc占一个字节,char flags占一个字节,�占一个字节
所以sdshdr8数据结构需要4个字节的元数据
除去这4个字节,缓存行还有48-4=44个字节的剩余空间,如果字符串数据范围小于等于44,把redisObject对象ptr指针所指向内存中的这个数据和redisObject对象放在一起即嵌入式字符串,在内存空间分配的时候,这两部分数据是分配在一起的,这样就可以直接适应缓存行的大小,这样就减少了一次内存io。
List数据类型
- • LPUSH
从左边开始往alist中放入元素
- • LPOP
从左边获取元素
依次是c、b、a
list如果没有元素的话,对应的key也会被清除
- • RPUSH
从右边放入元素
从左边放入元素,从左边拿出元素,则是栈的数据结构即a,b,c的数据放入,c、b、a顺序的拿出,a最开始进,最后出,先进后出,
同一端,从这边进,也从这边出,这就是栈的数据结构。
一边进,另外一边出,是队列的数据结构即右边放a,b,c,左边拿a,b,c,这是队列的数据结构。
阻塞api
如果没有元素就一直等待,直到有元素或者设置超时时间
LPOP从list中弹出元素之后就会从list中删除,如果应用程序没有正确处理的话,就会造成元素丢失的情况,BRPOPLPUSH就是为了应对这场场景,弹出元素之后,push到另外一个list中,做一个数据备份,防止数据丢失。
List数据类型底层设计
List是一个有序(按加入的时序排序)的数据结构,Redis采用quicklist(双端链表)和ziplist作为List的底层实现。
可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率。
- • list-max-ziplist-size -2
单个ziplist节点最大能存储8kb,超过则进行分裂,将数据存储在新的ziplist节点中
- • list-compress-depth 1
0代表所有节点,都不进行压缩,1代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4...依次类推
双端链表需要两个指针:pre,next,而指针占8个字节的内存空间,所以存储一个元素就至少占16个字节,如果元素比较多的情况下,内存开销就会非常大,所以redis并没有用quicklist 双端链表,而是用更加紧凑的ziplist。