从通用的协议栈层面来优化Redis性能的实践
redis 作为最受欢迎的 NoSQL 数据库之一,具备高性能、高可用性、高扩展性等特点,在各互联网业务中使用广泛。目前业界针对 Redis 的性能优化主要针是配置项优化以及使用方式的优化。本文介绍尝试撇开 Redis 本身,而从通用的协议栈层面来做优化,这种优化方式理论上可推广到其他 Socket 类互联网应用,如 Memcached、Ngnix、Envoy 等。
分 析
Redis-server 作为一个标准的 Socket 类应用,会通过监听地址端口接收来自客户端的连接,连接建立后会读取连接上的客户端请求,处理后再返回响应给客户端,这其中的连接建立、请求读取、响应返回都是通过内核的 TCP/IP 协议栈来处理的。可以通过火焰图先看一下 Redis-server 在性能压测下的 CPU 消耗情况。
图中,是在客户端读请求压测的时候抓取的火焰图信息。可见,内核态协议栈所占用的 CPU 消耗较大,其中以 sys_write 为主,占比 40% 左右。所以,如果能对这部分 CPU 占用进行优化,收益还是非常可观的。
那么这部分 CPU 占比如何进行优化呢?最好还能做到 Redis 应用本身完全无感知。
协议栈的处理完全省掉是不现实的,这样底层 TCP 通信就玩不转了。但是我们可以考虑将这部分处理剥离出去,不占用 Redis 的 CPU。
那剥离出去的协议栈实现放在哪儿呢?
可以放到一个单独的进程中实现。那这样是不是和剥离前没有区别?
No!因为一台机器上一般会启动多个 Redis 实例,多个 Redis 实例在这种情况下就可以共享这个协议栈实现的进程。相当于将 Redis 和协议栈的 1:1 绑定部署关系,变为 N:1 的独立部署关系。
那这个协议栈实现进程的性能就非常重要了,绝对不能成为瓶颈,否则会导致最终的性能没有提升,甚至更糟。具体如何实现呢?
下面该轮到用户态协议栈出场了!
优 化
用户态协议栈介绍
顾名思义,用户态协议栈是将原本在内核态实现的 TCP/IP 协议栈移到用户态实现的技术。放到用户态实现可以带来几大好处:
1. 高性能
Redis 本身是一个用户态的应用程序,调用内核态的 TCP/IP 协议栈实现,不可避免地会带来用户态和内核态的上下文切换开销。另外,最重要的一点,内核协议栈和应用绑定在一起,无法做到和应用在资源占用上剥离,也就是前面所述的独立部署。
2. 易调测
做过内核态开发的同学应该都知道,内核下程序的调测还是比较痛苦的,动不动给你来个 Oops 就会导致内核挂死。放到用户态实现调测起来就会方便很多。
3. 易定制
内核协议栈随着版本的迭代,历史包袱越来越重,导致越来越臃肿。而且新特性的合入时依赖会越来越多,也会越来越谨慎,甚至 bug 的修复周期也越来越长。用户态协议栈则不会有此类问题,可以在内核协议栈的基础上做裁剪和定制,易调测也会让试错成本大大降低。
相关视频推荐
学习地址:C/C++Linux服务器开发/后台架构师【零声教育】-学习视频教程-腾讯课堂
需要C/C++ linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
用户态协议栈具体实现
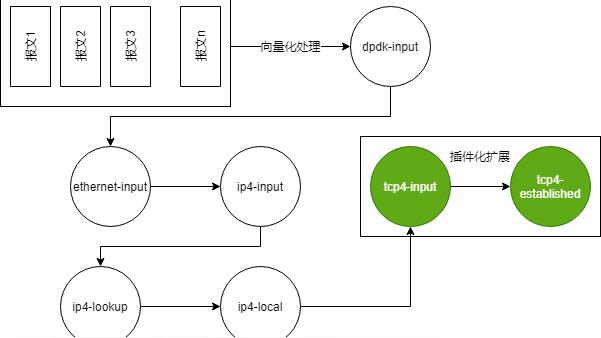
用户态协议栈我们采用开源 VPP+VCL 的方案:VPP 作为独立进程在用户态实现 TCP/IP 协议栈,VCL 作为动态库实现 Socket 类接口劫持并和后端 VPP 完成交互。整个系统的架构如下图所示:
其中:
- VCL - 实现 Socket 类接口劫持并和后端 VPP 完成交互
- FIFO - 是基于共享内存封装的消息队列,用于 VCL 和 VPP 之间通信
- Session - 维持传输层和上层应用会话之间的对应
- TCP/IP - 对应内核的 TCP/IP 协议栈实现
- DPDK - 实现将网卡的报文收发卸载到用户态
可见,VPP+VCL 分离式的部署模式将协议栈从应用端剥离,并通过 LD_PRELOAD 方式加载 VCL 动态库实现对于 Redis 的无侵入加速。
最后,VPP 如何做到本身处理的高效而不会成为瓶颈呢?
VPP 主要基于 DPDK 实现报文的高效收发,再结合自身的向量化处理(减少 CPU Cache missing)来实现报文的高效处理。另外,graph node+ 插件化也让其非常易于扩展和定制。
rdbsave 动态进程问题
使用开源 VPP 加速 Redis 过程中,也遇到和解决了不少社区版本中的问题,比较典型的就是 rdbsave 动态进程引发的问题。
Redis 可以配置周期性的保存快照,实现上会启用一个动态的 rdbsave 进程来完成,rdbsave 进程非常驻进程,在完成工作后就会退出。配置文件中可以指定保存的周期以及触发保存的变化量,如果周期配置的比较短且触发保存的变化量比较小,则可能会导致 rdbsave 进程频繁的创建和退出,实测过程中这也会导致目前社区中对于动态进程支持的一些问题很快速的就能暴露出来。
Session 同步问题
rdbsave 进程创建时会从主线程同步 socket 相关的 session 资源。目前社区中 epoll fd 相关的 session 资源没有同步完全,主要是因为 session handle 中包含了各个进程的 worker_index 信息,而 worker_index 是因进程 / 线程而异的,直接从主线程同步过来的 session handle 需要根据 worker_index 做转换才能使用。相关的 patch 目前已经合入社区。
死锁问题
rdbsave 进程退出时需要释放和进程关联的 session 资源,目前是通过主线程捕获 SIGCHLD 信号,在信号处理函数中来释放相关 session 资源。如果主线程在先获取锁 A 的情况下跳转到信号处理函数释放资源,而释放资源的时候也获取了锁 A,则会导致死锁。当然我们可以针对锁 A 的情况想办法解决此问题,但是这种解决方式不彻底,因为主线程可能获取了锁 B 后再去执行信号处理函数释放资源,然后释放资源的时候也获取了锁 B。根源是在于执行信号处理函数之前的主线程状态未知。
所以,我们可以考虑在信号处理函数中不释放资源,而仅仅将待释放的资源索引进行保存,等到后面合适的时机,如执行 epoll_wait 的时候再进行释放。相关的 patch 目前也已经合入社区。
效 果
通过优化后的火焰图看效果:
可见,内核的 socket 读写已经大大降低,还遗留的是用户态协议栈实现中用来在 VCL 和 VPP 之间通知事件的 eventfd 通知。
基于 redis 4.0.9 以及 memtier_benchmark 1.2.17 测试的结果。
QPS 提升 31%,此时内核态 Redis CPU 占用 99%,用户态 Redis CPU 占用 80% 左右。
延迟降低 23.2%,同样此时内核态 Redis CPU 占用 99%,用户态 Redis CPU 占用 80% 左右。
总 结
用户态协议栈可以轻松做到针对 Redis 的无侵入加速,在占用 CPU 资源更少的情况下,相较内核态协议栈可以取得 31% 的 QPS 加速效果,同时延迟降低 23%。
用户态协议栈作为通用的加速组件,理论上可以支持所有 Socket 类应用的加速。目前基于用户态协议栈对网易数帆轻舟微服务 API 网关中 Envoy 的加速已经产品化并在网易严选环境中落地,针对 Sidecar 的加速也相继在内外部客户完成测试,针对 Redis 的加速也完成了 PoC 测试。整个加速组件的数据面基于 Kube.NETes 的 DaemonSet 部署,而管控面基于 Kubernetes 的 Operator 部署,部署简单、运维方便。我们也会在后续工作中,持续探索基于用户态协议栈的更多应用场景。