使用Redis时要避免的5个错误
我不知道为什么你会选择对特定数量的“错误”(或警告)如此具体。听起来您正在寻找将要发布到 Yahoo! 的某些文章的内容。 Insider (N Foos to Blah for the BlahBlah)。
那说:
当您考虑使用 redis 时,我建议您考虑以下几点:
选择一致的方式来命名您的密钥并为其添加前缀。管理您的命名空间。
创建一个关键前缀或模式的“注册表”,将每个前缀或模式映射到“拥有”它们的内部应用程序(并在维基中记录这些,perhaos)
对于您放入 Redis 基础设施的每一类数据:设计、实施和测试垃圾收集和/或数据迁移到存档存储的机制。
在对应用程序部署进行大量投资之前,设计、实施和测试分片(一致散列)库,并确保在每个服务器上保留复制的“分片”注册表。
将您所有的 K/V 存储和相关操作隔离到您自己的库/API 或服务中,并以无情和无情的铁手绝对强制使用该 API/服务
让我依次解释这些要点:
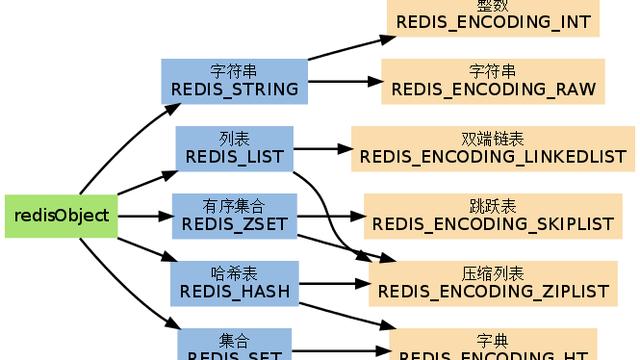
您应该从一开始就假设您的 Redis 基础设施将是许多应用程序或单独模块使用的公共资源。每个服务器上可以有多个数据库(默认编号为 0 到 31,但您可以增加这些数据库的数量)。但是,最好假设您需要使用键前缀来避免各种不同应用程序/模块之间的冲突。
一致的键前缀:管理您的命名空间:
您的应用程序/模块应该提供动态更改这些键前缀的灵活性。确保所有键都是从应用程序/模块前缀与您正在操作的键连接起来合成的;禁止对关键字符串进行硬编码。
注册表:记录和跟踪您的命名空间:
我建议您在 Redis 服务器上“保留”某些关键模式(前缀或全局模式)。例如,您可以将 __key_registry__(类似于 Python/ target=_blank class=infotextkey>Python 保留方法/属性名称)作为 URL 的关键前缀的哈希,进入您的 wiki 或 Trac 或您使用的任何内部文档站点。因此,您可以对数据库内容进行管理,并追踪谁/什么对您在任何数据库中找到的每个键负责。 (制定一项政策,即任何与您的注册表中的任何模式不匹配的密钥都可以/将被您的自动内务管理立即删除)。
垃圾收集:
在持久的、共享的、键/值存储中,特别是在 Redis 的情况下(其中完整的键/值存储必须始终适合 RAM ---不推荐使用 VM/交换存储)垃圾收集是可能是单一的主要维护问题。
因此,您需要考虑如何选择需要从 Redis 迁移出的数据(可能会迁移到 SQL/RDBMS 或其他形式的存档存储中),以及您将如何跟踪和清除数据这是过时的或无用的。
显而易见的方法涉及使用 EXPIRE 或 EXPIREAT 功能/命令。这允许 Redis 为您管理垃圾收集,无论是相对于您对任何给定键的操作(创建或更新),还是根据绝对(自纪元以来的秒数)时间规范。关于 Redis 过期的唯一技巧是每次更新密钥时都必须重新设置它。
这种方法适用于它自然适用的情况。但是,如果您想无限期地缓存数据/键并且只清理条目,则它没有用。为此,我建议您使用“ZSET”——一个带有值和“分数”的集合,可以通过这些分数的范围来查询……通常用于有序/排序的集合。在我的模型中,您将向集合、键及其关联的时间戳添加项目(当您将相应的键/值添加或更新到数据库本身时。然后您可以使用以下内容查询该 ZSET:ZRANGEBYSCORE __EXPIRY__ 0 $SOME_EPOCH_TIME 获取在特定时间之前添加/更新的这些子集。您可以迭代此结果,删除相应的键/值对,直到您在服务器上释放了足够的空间来满足您的需求(或完成了您为自己设置的其他垃圾收集要求)。
另一种有用的方法是维护一个或多个队列(Redis 列表,由 RPUSH/LPUSH 和 RPOP/LPOP 命令、它们的 B* 阻塞表兄弟或相当棘手的 BRPOPLPUSH/RPOPLPUSH 命令操作),用于将事物持久化以使其更持久大容量存储(例如您的 SQL RDBMS)。基本上,这用作一个工作队列,列出在 Redis 中已更改的键(可能还有某种形式的关于规范数据存储的标识符),因此需要将其复制到您的大容量存储中。您可以监控此类队列的长度为 e确保您没有遇到不断增长的积压。
分片:
Redis 不提供分片。您可能应该假设您将增长超出单个人 Redis 服务器的容量(从属服务器用于冗余,而不是用于扩展,但如果您有某种方法来管理数据一致性,您可以将一些只读操作卸载到从属服务器—— - 例如,未到期描述的密钥/时间戳值的 ZSET 也可用于一些离线批量处理操作;发布/订阅功能也可用于主机提供有关所选密钥/数据静止的提示。
所以你应该考虑编写自己的抽象层来提供分片。基本上想象一下,你已经实现了一个一致的散列方法……在使用它之前,你通过它运行每个合成的密钥。虽然您只有一个 Redis 服务器,但哈希到服务器的映射最终总是指向您唯一的服务器。稍后,如果您需要添加更多服务器,则可以调整映射,以便将一半或三分之一的密钥解析到其他服务器。当然,您会希望实现这一点,以便主服务器上的故障导致您的库/服务模块在辅助服务器和可能的任何第三级服务器上自动重试。根据您的应用程序,您甚至可能会尝试从另一个数据源(例如您的 SQL RDBMS)完全获取某些类型的数据。
这是一个领域,特别是,我希望看到一个强大的第三方(或 antirez 创建)库编写来处理所有繁琐地位置。一致的散列并不难……但它确实需要相当多的精心编写的代码来实现——而且它应该远离大多数应用程序编码人员。您想要一些可以正常工作并继续工作的东西,即使您添加了额外的服务器容量(需要为所有受影响的密钥迁移实用程序)和故障(要求您已经处理了将数据复制到二级和/或三级服务器) .
将您的 Redis 操作与您的应用程序分离:
我希望你已经看到了这个建议对我提出的所有其他建议的重要性的预示。如果有人只是将 Redis 基础设施用作临时的、无底的资源,那么这些都将不起作用。
不要将您的应用程序视为使用 Redis!
您正在编写一个使用一组服务的应用程序。碰巧的是,(部分)这些服务是由 Redis 服务器提供的。但是,您应该将其视为实现细节,并专注于您需要哪些服务以及您向应用程序开发人员提供哪些 API 来提供这些服务。
Redis 提供的任何东西都不是您通过众多替代方案无法完成的。如果您编写正确类型的代码(可能包括存储过程、触发器等和/或单独的守护程序)并实现正确的模式,则可以在某种程度上使用 SQL/RDBMS 后端来近似或提供 Redis 的每个功能它。
如果您专注于需要提供给应用程序开发人员的 API,那么您就有希望更换那些不可避免地需要在以后更换(无论出于何种原因)的部分。您还可以在开发需要与现有数据库交互的其他应用程序和模块时提供更大的灵活性。