python + selenium实现gitlab全文搜索
一般来说软件开发相关企业都会有自己内部的源代码管理工具,比如私有部署的gitlab服务器。特别是企业上规模之后会有多个产品线,各个业务产品线各自的项目解决方案会非常多。
以我们公司为例,就招聘事业部来说,内部的大大小小的中台ESB、MRest、各种Consumer消费端、各种工具等等解决方案现在已经上百个了。这个时候你就会遇到如下一些场景:
1.需要修改某个公共接口的参数或者某个基础库项目包中的公共方法,但是不知道到底哪些项目、哪些地方引用了该接口,不好评估影响点?
2.业务代码中已知道某个Kafka Topic,但是当初写代码兄弟没备注消费端的项目,找了很久就是找不到Consumer项目在哪儿?
3.我想通过某一些特定的关键词搜索某一段代码,记不清到底在哪些项目中使用了?
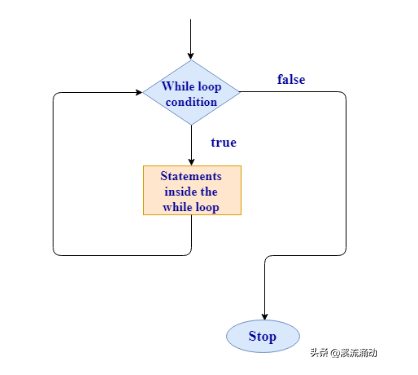
如果你有上述的困惑,那么下面介绍的这个gitlab 全局 Search代码搜索工具能够帮你解决这些问题。工具的实现采用Python/ target=_blank class=infotextkey>Python + selenium + chromedriver实现自动化登录内部gitlab站点,通过勾选默认配置的产品分组,实现对多个分组内的项目代码特定多个关键词查询搜索。工具的运行流程及界面大概如下面几幅截图所示:
step1.读取配置文件信息自动登录:
{
"username": "yourname",
"password": "yourpassword",
"projectGroups": [
"recrxxx",
"platform-uiframework",
"platform-infrastructure",
"ux-share-platform"
]
}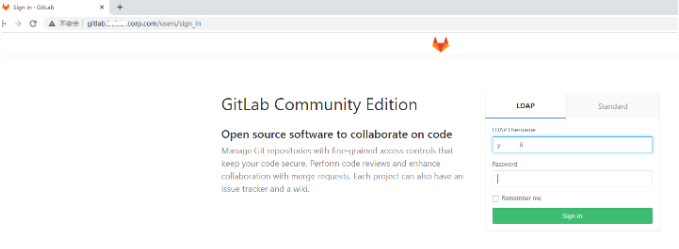
step2: 登陆成功后主页注入搜索填充信息,可选择的搜索项目分组、关键词录入框等

step3:开始遍历项目分组,获取项目id,并执行关键词搜索

step4:获取命中结果展示,小于等于10个结果的会默认打开浏览器tab页全部展开,大于10个结果的需要手动打开单个或全部

step5:因为使用的chromedriver来驱动实现的,需要注意chrome浏览器版本与chromedriver版本的匹配,如不匹配会记录如下日志;

主要利用python 驱动 selenium 实现自动化控制gitlab项目页面,通过注入特定html标签代码,实现自动化搜索gitlab项目代码。下面是python脚本部分主要实现:
class GitLabSearchTool(object):
def __init__(self):
self.__username = ''
self.__password = ''
self.projectGroups = []
self.usedKeywords = []
self.__getConfigInfo()
self.maxPageIndex = 50
self.divId = 'spiderContainer'
self.searchDivId = 'searchContainer'
self.base_url = "http://gitlab.xxxcorp.com"
self.baseLoginUrl = "http://gitlab.xxxcorp.com/users/sign_in"
self.startTime = datetime.now()
self.isSearching = False
self.stopSearch = False
self.isClose = False
self.successUrls = dict()
self.searchGroup = []
self.keywords = []
self.request = None
self.driver = None
def start(self):
user_agent = "Mozilla/5.0 (windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
chrome_options = Options()
chrome_options.add_argument('user-agent={}'.format(user_agent))
chrome_options.add_argument('--disable-plugins') # 禁用插件
chrome_options.add_argument('--start-maximized') # 启动google Chrome就最大化
chrome_options.add_experimental_option("excludeSwitches", ['enable-automation']) # 隐藏"Chrome正在受到自动软件的控制"
pathItem = ['chromedriver.exe']
driverPath = Path.cwd().joinpath(*pathItem)
self.driver = webdriver.Chrome(driverPath, options=chrome_options)
self.driver.get(self.baseLoginUrl)
if self.__username and self.__password:
WebDriverWait(self.driver, 1000).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="new_ldap_user"]')))
time.sleep(0.3)
self.driver.find_element(By.XPATH, '//*[@id="username"]').send_keys(self.__username)
time.sleep(0.3)
self.driver.find_element(By.XPATH, '//*[@id="password"]').send_keys(self.__password)
time.sleep(0.3)
self.driver.find_element(By.XPATH, '//*[@id="remember_me"]').click()
self.driver.find_element(By.XPATH, '//*[@id="new_ldap_user"]/input[3]').click()
threading.Thread(target=self.__checkBrowserIsClose).start()
self.request = requests.session()
try:
while not self.isClose:
try:
homediv = self.driver.find_element(By.ID, "xxxyoucangohomenow")
if homediv is not None:
self.driver.get(self.base_url)
except:
pass
try:
searchDiv = self.driver.find_element(By.ID, "xxxyoucanstartsearchnow")
if searchDiv is None:
time.sleep(1)
else:
self.startTime = datetime.now()
self.successUrls.clear()
self.searchGroup.clear()
self.keywords.clear()
chkList = self.driver.find_elements(By.XPATH,
'//*[@id="searchGroup"]/descendant::input[@type="checkbox"]')
for chk in chkList:
if chk.get_attribute('checked') == 'true':
self.searchGroup.append(chk.get_attribute('attrvalue').strip())
if len(self.searchGroup) <= 0:
return
keywordInput = self.driver.find_element(By.ID, 'searchKeyword')
searchKeyword = keywordInput.get_attribute('value').strip()
keywords = re.split(',|,', searchKeyword)
if len(keywords) > 0:
for kw in keywords:
kw = kw.strip()
if len(kw) > 0:
self.keywords.append(kw)
if len(self.keywords) <= 0:
self.driver.execute_script("arguments[0].focus();", keywordInput)
return
self._search()
except :
time.sleep(1)
print('webdriver is close')
return
except Exception as ex:
print('异常:{}'.format(ex))
return
def _search(self):
self.isSearching = True
self.stopSearch = False
for group in self.searchGroup:
if self.stopSearch:
break
for page in range(1, self.maxPageIndex):
if self.stopSearch:
break
url = "http://gitlab.xxxcorp.com/{}?page={}".format(group, page)
self.driver.get(url)
WebDriverWait(self.driver, 5).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="content-body"]/div[2]/div[1]/ul/li[1]/a')))
projects = self.driver.find_elements(By.XPATH,
'//*[@id="projects"]/div/ul/descendant::a[@class="project"]')
if len(projects) <= 0:
break
for proj in projects:
try:
stopSearch = self.driver.find_element(By.ID, 'xxxyoucanstopsearchnow')
if stopSearch is not None:
self.stopSearch = True
break
except:
pass
projUrl = proj.get_attribute('href')
self.__searchProject(projUrl)
endTime = datetime.now()
delta = (endTime - self.startTime).seconds
successCount = len(self.successUrls)
searchKeyword = ','.join(self.keywords)
if successCount > 0:
searchedPojectUrl = self.__getSearchedProject()
html = '''<div style="text-align:center;margin-top:150px;font-size:20px;font-weight:bold;color:white;">
<span>查询{}</span><br/>
<span>耗时:{} 秒! 命中{}个项目</span>
<button style="width:150px;margin-left:50px;color:red;font-size:16px;font-weight:normal;"
type="button" onclick="gotohome()">跳转搜索主页</button>
<div id="searchresultdiv" style="font-size:18px;font-weight:normal;max-height:400px;
overflow:auto;margin:auto;margin-top:5px;width:50%;text-align:left;
border:1px solid white;border-radius:3px;padding:10px;scroll:auto;
::-webkit-scrollbar {{width:4px;height:4px;}}">
<button style="width:150px;color:black;font-size:16px;font-weight:normal;"
type="button" onclick="openAllUrl()">打开全部链接</button><br/>
{}</div>
</div>'''.format(searchKeyword, delta, successCount, searchedPojectUrl)
else:
html = '''<div style="text-align:center;margin-top:150px;font-size:20px;font-weight:bold;color:white;">
<span>查询{}</span><br/>
<span>耗时:{} 秒! 命中{}个项目</span>
<button type="button" style="width: 150px;margin-left:50px;color:red;font-size:16px;font-weight:normal;"
onclick="gotohome()">跳转搜索主页</button><br/>
</div>'''.format(searchKeyword, delta, successCount)
self.__createDom(html)
self.isSearching = False
if len(self.successUrls) <= 10:
for url, name in self.successUrls.items():
self.driver.execute_script('window.open("{}")'.format(url))
def __searchProject(self, projUrl):
proj = self.__getProjectId(projUrl)
if proj[0] <= 0:
return
for keyword in self.keywords:
if not (keyword and len(keyword.strip()) > 0):
continue
searchUrl = '{}/search?utf8=&snippets=&scope=&search={}&project_id={}'
.format(self.base_url, keyword, proj[0])
data = self.request.get(searchUrl).text
html = etree.HTML(data)
topResults = html.xpath('//*[@id="content-body"]/div[contains(@class,"prepend-top-10")]')
if len(topResults) > 0:
self.successUrls[searchUrl] = proj[1]
# js = 'window.open("{}")'.format(searchUrl)
# self.driver.execute_script(js)
# self.driver.switch_to.window(self.driver.window_handles[0])
successCount = len(self.successUrls)
if successCount > 0:
searchedPojectUrl = self.__getSearchedProject()
html = '''<div style="text-align:center;margin-top:150px;font-size:22px;font-weight:bold;color:white;">
<button style="width:150px;color:red;font-size:16px;font-weight:normal;"
type="button" onclick="stopSearch()">停止搜索</button><br/>
<span>正在查询"{}"</span><br/>
<span>{}</span><br/>
<span>查询命中{}个项目</span><br/>
<div style="font-size:16px;max-height:400px;width:50%;scroll:auto;
overflow:auto;margin:auto;margin-top:5px;text-align:left;
border:1px solid white;border-radius:3px;padding:10px;
::-webkit-scrollbar {{width:4px;height:4px;}}"">{}</div>
</div>'''.format(keyword, projUrl, successCount, searchedPojectUrl)
else:
html = '''<div style="text-align:center;margin-top:150px;font-size:22px;font-weight:bold;color:white;">
<button style="width:150px;color:red;font-size:16px;font-weight:normal;"
type="button" onclick="stopSearch()">停止搜索</button><br/>
<span>正在查询"{}"</span><br/>
<span>{}</span>
</div>'''.format(keyword, projUrl)
self.__createDom(html)
def __getProjectId(self, url):
proj_id = 0
proj_name = ''
data = self.request.get(url).text
html = etree.HTML(data)
values = html.xpath('//*[@id="search_project_id"]/@value')
if len(values) > 0:
proj_id = int(values[0])
names = html.xpath('//*[@id="search_project_id"]/@data-name')
if len(names) > 0:
proj_name = names[0]
return (proj_id, proj_name)
.....