如果 Python 4.0 摆脱了 GIL…
作者:orenwang,腾讯IEG应用开发工程师
| 导语 GIL,即全局解释器锁,是阻碍 Python/ target=_blank class=infotextkey>Python 多线程并发计算性能提升的最大原因,也是众多 Python 开发者的心头之痒,而 Sam Gross 大神的新项目 nogil 却在过去几个月的时间里硬生生地撬开了这把锁。
There should be one- and preferably only one -obvious way to do it.
- Zen of Python
1992年的一天,Python 之父 Guido van Rossum 为 Python 引入了一种简单而又优美的机制:让程序运行无需再担心死锁,因为全局只有一把锁;功能实现更加简洁,无需再针对单个对象加锁和解锁,因为全局只有一把锁;甚至大幅提高了计算速度,这来源于程序本身的低 Overhead 和独特的 Garbage Collection 机制,因为全局只有一把锁。这把锁就是 GIL,即全局解释器锁。
我们快进到1998年,硬件行业在这一年发生了一个重要的变化:多核处理器被研制出来了。大家很快意识到 GIL 在单线程领域的强大,却成为了多核计算时代的绊脚石。因此在1999年 Python 1.4 版本期间出现了一个叫 "free-threading" 的包,大刀阔斧地移除了 GIL,然而单线程计算速度却慢了4到7倍。
而我所知道的最近一次移除 GIL 的尝试是 2016 年 Larry Hastings 大神提出的 Gilectomy 项目,其移除了 GIL 之后单线程计算仅慢了 30%,然而该项目的主要问题在于核越多,计算越慢(7核下慢19倍)。
由此可见,Guido 爸爸写的这段代码,尽管每天被全球开发者吐槽,但真搞起来,想比人家做得更好并不容易。
GIL 的问题
举一个简单的例子:给你一张纸,上面有100个格子,让你从数字1写到100,一个格子一个数字,你觉得需要多久?我闲来试了一下,花了我82秒(好像真的很闲)。那好,现在假设你们有五个人,每个人只要写其中20个数字即可,你觉得需要多久?简单地看,82秒除以5,五个人大约16秒即可完成。但如果你们五个人只有一支笔呢?算上你们互相传递笔的时间,恐怕82秒也不够了。

纸上画数字的例子(动画内可以想象成100个人+100支笔同时写字)
上面的例子里,这支笔,在 Python 的世界里就是 GIL:无论你们有多少人,只能有一个人拿着笔,其他人只能等着这个人把笔放下,才能开始写字;无论你的 Python 程序起了多少个线程,真正吃 CPU 干活的只有一个线程。之所以这里强调了一下吃 CPU,是因为 GIL 的设计仅对 CPU-bound 的程序有限制,而在处理 IO-bound 计算时,是不需要 GIL 这支笔的,大家可以同时干 I/O 的活。
这时很多人会好奇,为什么不直接使用 multiprocessing 库进行多进程计算呢?当然可以,但是 multiprcessing 的实现实际上是"fork"了个新的进程,性能牺牲了不说,死锁的问题也将会暴露出来,更不用说如 CUDA 等很多第三方库是不支持“fork”的。
再说一点,实际上,大部分人吐槽 GIL 的点,并非是 Python 程序本身并发效率的问题,而是大多数对于计算速度有要求的库都是 Python 调用 C/C++,而 GIL 限制了你在调用 C/C++ 时也只能真正同时运行一个线程。也难怪 Sam 大神想要移除掉 GIL,他作为 PyTorch 的核心作者,自称因性能问题曾大面积地把 Python 代码完全重写成了 C/C++ ,也因此很多人说 PyTorch 跟 Python 关系已经不大了。相比之下,Swift 团队曾写过一篇 “Why Swift for Tensorflow” 点出了相比 Python 的 GIL 性能瓶颈, Swift 在训练 AI 的性能方面具备优势;而Python 的第一竞品 Julia 开发者和爱好者们更是揪着 GIL 这一点屡屡不放手,“怂恿”大家转向使用 Julia 做数据科学工作。
综上,现今 GIL 怕是过大于功了。
一些不那么基础的基础知识
接下来,本文会讲解一些技术细节,虽然尽可能写得通俗易懂(从而不暴露自己其实也不懂),但如果不够熟悉 Python 的话可能还是会觉得有些不知所云...
- CPython
简单来讲,CPython 就是我们用的 Python。只是为了更容易地与“Python这门语言”进行区分,我们一般把运行 Python 解释器的这个引擎叫做 CPython(我一开始就把 CPython 跟 Cython 项目搞混了,但其实 Cython 和我们本文说的就不是一回事了,它只是个把 Python 变成 C 的工具)。那除了用 C 写的 CPython,其实还有用 JAVA 和 C# 分别写的 Jython 和 IronPython。值得注意的是,后两者并没有 GIL,因此 GIL 并不是 Python 这个语言的特性/问题,而是 CPython 实现中包含的,因此下文与 GIL 相关的都会用 CPython 这个名字进行阐述。
- Reference Counting
当你有了变量的时候,CPython 就已经开始计数(counting)了,而当这个变量出现在任一列表(list)或者字典(dict)或者函数(function)内的时候,计数都会增加。当使用变量的函数执行完毕,或这个变量被 pop 出了某一个列表的时候,CPython就会把这个变量的计数对应减少。而当某个变量计数为零的时候,这个变量所在的内存就可以被释放掉了,可以看CPython 源码这里(https://github.com/python/cpython/blob/main/Include/object.h#L520)就是这么写的。
具体计数方式也可见下面的代码例子,我个人觉得看代码更容易理解:

而这个 Reference Counting 有意思的地方就在于:程序释放变量对应的内存空间无需等待GC工作时再进行操作了!因为只要计数为零,就满足了条件。那为什么 CPython 还是需要 GC 呢?我这里一下子也没想通,查阅了一下资料发现原因其实很简单,因为如果有几个变量没其他地方用到了,但是它们互相之间是有 reference 的,那这个时候仅靠 Reference Counting 去释放内存自然就会发生内存泄漏。
- Atomicity
继续用上面“纸上写数字”的例子,当你在写数字“17”时,你要先写个“1”,再写个“7”吧。可能在你写“7”之前,会有人把你的笔抢走,这个OK。但你起码不能在写“1”写到一半的时候,允许别人打断你。换句话说,你要有一个最“原子”的行为,这个行为无法进一步再拆分,你就Atomic了。
这个概念,有一些数据库知识基础的话,应该不需要解释,跟大部分数据库所保证的 Atomic 是不同场景下的同一个意思。
- Concurrent Collection Protections
列表(list)或者字典(dict)这类对象,我们都可以称之为 Collection,这些对象往往在类似 Python 这种语言内都有各自独特的内存结构,有的结构倾向于计算速度,而有的结果是出于内存占用考虑进行了优化。但无论哪种结构,在出现并发的的情况下,这些 Collection 都存在线程安全问题,因此处理时底层往往有一定的并发锁逻辑进行保护,这个相信不难理解。
改写历史的 nogil 项目的技术细节
Sam 大神的新项目 nogil 之所以获得了如此大的关注度,也首次引起 CPython 核心团队好评的原因不仅是它成功移除掉了 GIL (而非类似 per-interpreter GIL 那种半移不移的设计),同时也克服了绝大多数前人未能解决的问题,而且最终性能分数惊人。通读了 Sam 的原 paper 后,我又翻阅了几篇大神们对该工作的讨论和文章,感觉这个项目成功的核心倒不是设计上有多么巧妙(当然人家非常非常非常巧妙),难得的是 nogil 把 Python 目前版本里几个 “浪费” 掉的地方拎出来逐一进行了深度优化,只不过“深”到已经把 Python 的内存分配器 PyMalloc 都直接换掉了。正像 Larry Hastings 所说,难的不是移除掉 GIL,难的是移除掉了 GIL 还能保证以前的东西就像没移除掉一样好用... 那 Sam 是怎么做到呢?这里讨论下我觉得比较有意思的几点:
Biased Reference Counting
这其实是2018年ACM上的一篇论文 Biased Reference Counting 提出的一种全新 Reference Counting 理论:并发多个线程同时进行 Reference Counting 操作时,我们往往需要把每一次操作 Atomic 化,这样才能保证各个线程之间得到的 count 值保持一致;但我们忽略了一个因素,如果一个对象经常会被某一个线程操作,而被其他线程操作的频次很少,那我们是不是可以给这一个类似 "owner" 的线程一些特殊的优化,即便让其他的线程慢一点也影响不大?
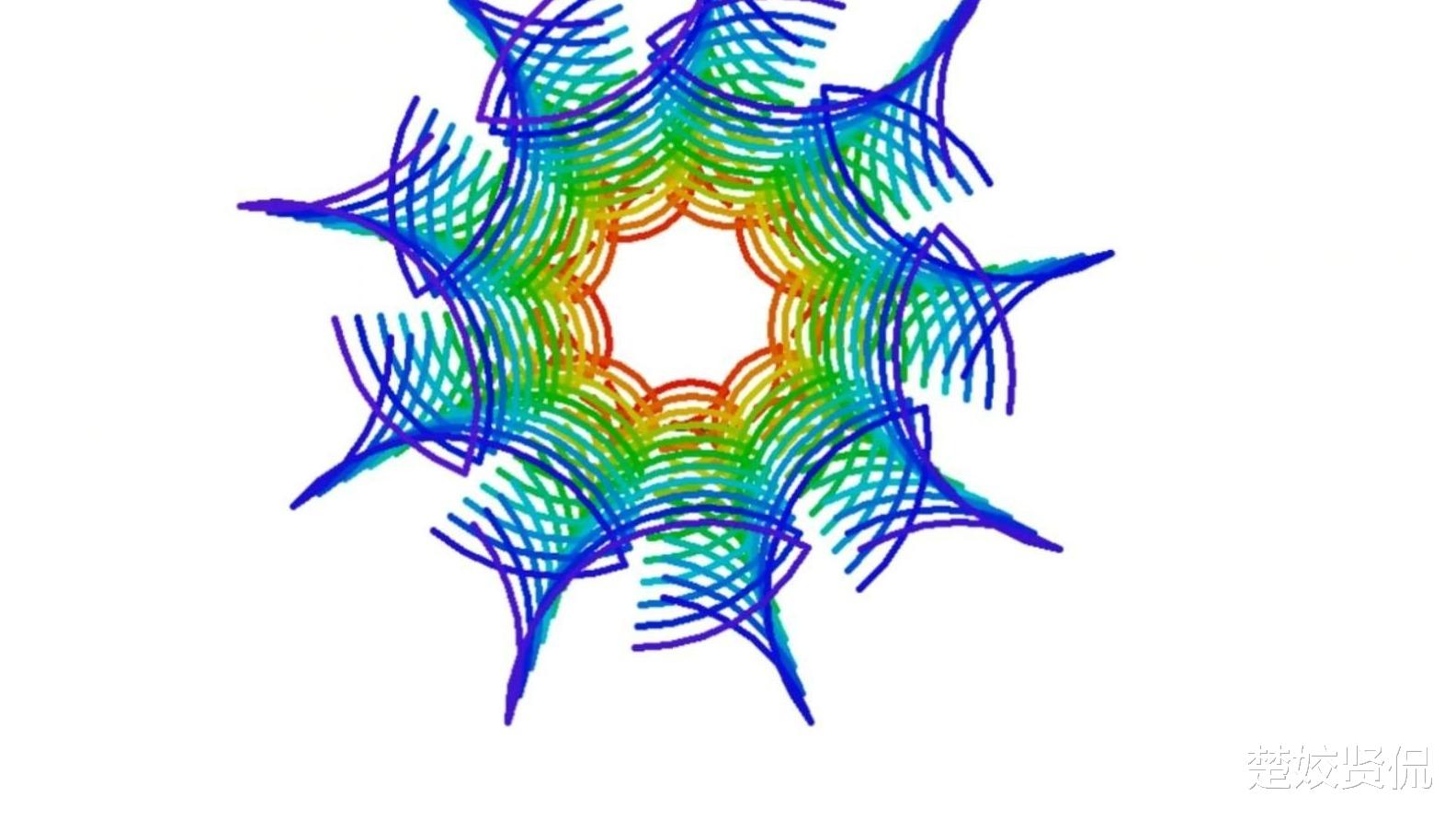
而事实上,绝大多数对象都是面临这样一种情况。所以,这里我们就 “Biased” 了,让 “owner” 线程的 Reference Counting 操作速度达到极致,而不用保证 Atomic ,只需要让其他所有的线程 Atomic 即可(好吧,这里我也不是很懂,为什么 Non-Atomic 就一定比 Atomic 要快,但我知道为了做到 Atomic 显然要做某些牺牲,等有时间我再具体看看为啥,然后补充到这里)。这一点非常关键,是整个 nogil 项目对性能贡献最大的一点,我画了个动画帮助理解:

Immortalization
上面的 Biased Reference Counting 好用的前提是“大多数变量只有一个线程会经常使用”,但对于那些 0、1、True、False、 None之类的变量呢?这些变量可是几乎每一个线程都要频繁使用的。为了提高这类变量的操作速度,Sam 很巧妙地把这些变量 Immortalize(永久化)了,使得这类变量的引用不再需要做计数!我看到了这里,就有种强烈的“md我怎么没想到”的感觉。
不过实现 Immortalization 也不是没有牺牲的:计数值的 LSB(最低有效位,Least Significant Bit)不能再用了,因为 LSB 被用来代表这个变量是不是可以永久化掉了。这里会结合下面的 Deferred Reference Counting 再多讨论一些。
Deferred Reference Counting
继续揪着 Reference Counting 不放:那些既不能被永久化掉的同时又需要频繁使用的对象怎么办(怎么有点谐音梗...)?这个第二低有效位也被拿来征用了,被用来表示某个对象是否需要“Defer”它的引用计数。这个“Defer”的意思我个人感觉有一点误导,因为它其实并非“延后”,根本就是不再计数了,把所有释放相关的工作都交给 GC (Garbage Collector)了,毕竟很多引用的 top-level functions 或者 modules 本来就是只能被 GC 给释放掉。
这里的具体实现我也不是很懂,但知道大概是因为局部变量一般是在内存的 Stack 上,Deferred Reference Counting 是完全不用管 Stack 上的计数变化,但如果一个对象的引用是被放在 Heap 上的,这个时候计数其实是照常的,只不过不会因为 Heap 上的计数为 0 而直接释放掉它,毕竟这个时候有可能有 Stack 内存还在引用它。
Immortalization 和 Deferred Reference Counting 加起来一下就用掉了两个最低位,也就是说以后每次调用 Py_INCREF 和 Py_DECREF,Reference Count每次变化就是 4 了,感觉怪怪的。不过按 Sam 的原话,这里其实变化是 1 还是 4 并不重要,毕竟我们大部分情况下只关心这个计数是不是零就够了。这么说,也确实有些道理。
Mimalloc
Python 的内存分配器 PyMalloc 被换成 mimalloc 了。看 mimalloc 文档看到第二段就感觉好厉害:
mimalloc is a drop-in replacement for malloc and can be used in other programs without code changes
这哪里是换掉 PyMalloc,这原来是可以直接换掉 malloc 了。。。
具体实现细节我就没有看了,因为我知道我肯定看不懂。但是这里使用它的原因就很明显了:因为 PyMalloc 有 GIL 的保护,所以不需要也做不到 thread-safe,而 mimalloc 可以让 Python 做到 thread-safe 同时性能大幅提升。
Collection Read-only Access
写到这里,终于写到了码农们熟悉的 list 和 dict 对象了。
当我们引用或一个 list 或 dict 对象,发生的过程大致可以简单地分成三个步骤:
- 加载这个对象的地址
- 修改对象的 Reference Count
- 返回这个对象的地址
这一切在 GIL 的保护下没什么问题。然鹅现在我们没有 GIL 了,这里会出现一个问题:当有一个线程执行写操作时,在步骤 2 把这个对象释放掉了(Reference Count 减少到 0),而这个时候又有一个线程已经完成了步骤 1,开始直接步骤 2 时,就崩溃了,因为这个对象已经被释放掉了。
Sam 的设计是,既然我们没有 GIL 这把全局锁了,我们就要给单个对象加局部锁,不过我们只对写操作加锁。具体实现简单来说就是增加了 Reference Counting 版本控制和更多的检查判断并重试机制,比如在执行上述的步骤 2 时首先检查对象是否 Reference Count 已经为 0 了,如果是的话,从步骤 1 开始重试(重试之后我理解就可以读到一个新的地址或是可以识别出是空地址从而保证安全性)。
目前对于 list 和 dict 的重新设计,主要是对单线程处理速度进行了优化,对于多线程处理只能保证安全而速度上有一定程度的牺牲。也许以后会出现一些特殊的 collection 类型,以应对那种多线程频繁调用的情况。
Python 4.0 是否真的会移除GIL?
我个人感觉,出现一个没有GIL版本的 Python 4.0 的可能性是比较大的,毕竟 CPython 核心团队其实已经在着手将 Sam 大神的 nogil 项目合入 Python 3.11 了,而且该项目的性能分数已经达到甚至部分超过了 Guido 爸爸之前对于拿掉 GIL 的基本条件,这一次没有“借口”可以拒绝了。当然 Python 3.11 多半不会是一个无 GIL 版本,nogil 项目无论多强大它也还只是个实验项目,其仍存在诸多大小问题,以及很多仍待讨论的架构决策,都不是一个小版本就能够解决掉的。
至于 Python 4.0,它自己本身就是个未知数。核心团队自己已经重申了多次他们想尽量延后 Python 4.0 的时间,因为 Python 2.0 到 3.0 大家已经很伤了,这么快又搞一波怕大家心里承受不了。。。Guido 爸爸很久就曾发推解释过一次:

这里我想吐槽一下,从 Python 3.5 开始,每个版本就已经很伤了好么还不如赶紧上 nogil 也算是个痛并快乐着。
无论结果如何,我作为一个被 Python 领进门的、被 Python 各种骚操作种草的、到现在不管后端服务还是客户端脚本还是各种AI“小研究”都首选 Python的忠实粉丝,衷心祝愿 Python 未来...越来越妖!