相关概念

并发和并行
- 并发:指一个时间段内,在一个CPU(CPU核心)能运行的程序的数量。
- 并行:指在同一时刻,在多个CPU上运行多个程序,跟CPU(CPU核心)数量有关。
因为
计算机CPU(CPU核心)在同一时刻只能运行一个程序。
同步和异步
- 同步是指代码调用的时候必须等待执行完成才能执行剩余的逻辑。
- 异步是指代码在调用的时候,不用等待操作完成,直接执行剩余逻辑。
阻塞和非阻塞
- 阻塞是指调用函数的时候当前线程被挂起。
- 非阻塞是指调用函数时当前线程不会被挂起,而是立即返回。
CPU密集型和I/O密集型
CPU密集型(CPU-bound):
CPU密集型又叫做计算密集型,指I/O在很短时间就能完成,CPU需要大量的计算和处理,特点是CPU占用高。
例如:压缩解压缩、加密解密、正则表达式搜索。
IO密集型(I/O-bound):
IO密集型是指系统运行时大部分时间时CPU在等待IO操作(硬盘/内存)的读写操作,特点是CPU占用较低。
例如:文件读写、网络爬虫、数据库读写。
多进程、多线程、多协程的对比
|
类型 |
优点 |
缺点 |
适用 |
|
多进程
Process(multiprocessing) |
可以利用CPU多核并行运算 |
占用资源最多
可启动数目比线程少 |
CPU密集型计算 |
|
多线程
Thread(threading) |
相比进程更轻量占用资源少 |
相比进程,多线程只能并发执行,不能利用多CPU(GIL)
相比协程启动数目有限制,占用内存资源有线程切换开销 |
IO密集型计算、同时运行的任务要求不多 |
|
多协程
Coroutine(asyncio) |
内存开销最少,启动协程数量最多 |
支持库的限制
代码实现复杂 |
IO密集型计算、同时运行的较多任务 |
GIL全称Global Interpreter Lock
下图为GIL的运行
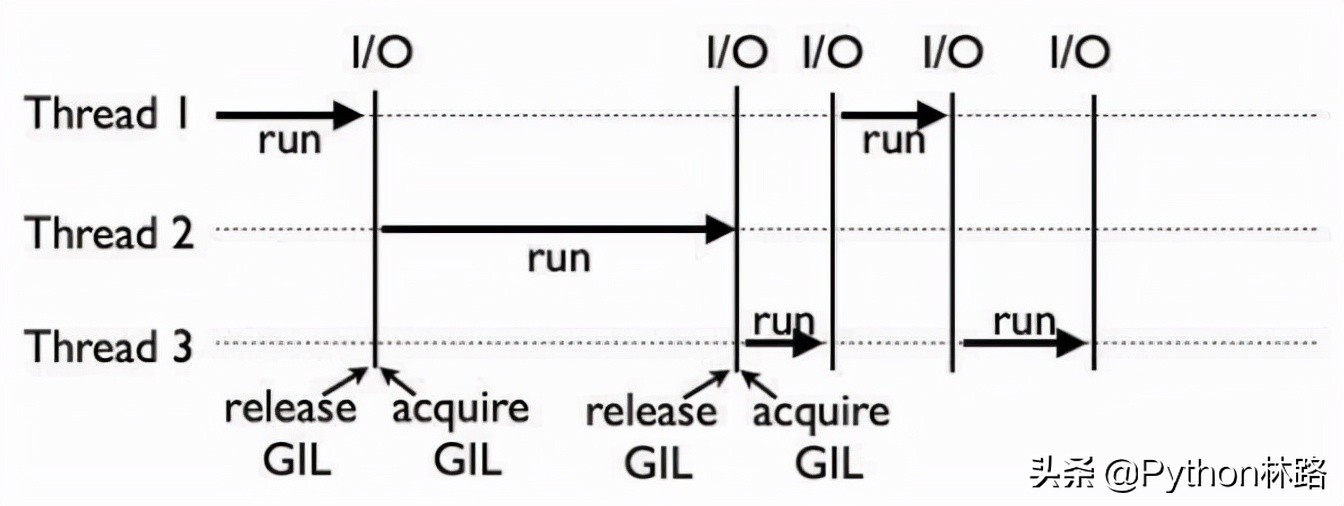
Python/ target=_blank class=infotextkey>Python的多线程是伪多线程,同时只能有一个线程运行。
一个进程能够启动N个线程,数量受系统限制。
一个线程能够启动N个协程,数量不受限制。
怎么选择
对于其他语言来说,多线程是能同时利用多CPU(核)的,所以是适用CPU密集型计算的,但是Python由于GIL的限制,只能使用IO密集型计算。
所以对于Python来说:
对于IO密集型来说能用多协程就用多协程,没有库支持才用多线程。
对于CPU密集型就只能用多进程了。

协程(异步IO)
简单示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import asyncio
async def test():
await asyncio.sleep(3)
return "123"
async def main():
result = await test()
print(result)
if __name__ == '__main__':
asyncio.run(main())
|
单次请求查看结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import threading
import asyncio
async def myfun(index):
print(f'[{index}]({threading.currentThread().name})')
await asyncio.sleep(1)
return index
def getfuture(future):
print(f"结果为:{future.result()}")
if __name__ == "__main__":
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(myfun(1))
future.add_done_callback(getfuture)
loop.run_until_complete(future)
loop.close()
|
或者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import threading
import asyncio
async def myfun(index):
print(f'[{index}]({threading.currentThread().name})')
await asyncio.sleep(1)
return index
if __name__ == "__main__":
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(myfun(1))
loop.run_until_complete(future)
print(f"结果为:{future.result()}")
loop.close()
|
多次请求查看结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import threading
import asyncio
async def myfun(index):
print(f'线程({threading.currentThread().name}) 传入参数({index})')
await asyncio.sleep(1)
return index
loop = asyncio.get_event_loop()
future_list = []
for item in range(3):
future = asyncio.ensure_future(myfun(item))
future_list.Append(future)
loop.run_until_complete(asyncio.wait(future_list))
for future in future_list:
print(f"结果为:{future.result()}")
loop.close()
|
asyncio.wait和asyncio.gather
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import threading
import asyncio
async def myfun(index):
print(f'[{index}]({threading.currentThread().name})')
await asyncio.sleep(1)
loop = asyncio.get_event_loop()
tasks = [myfun(1), myfun(2)]
loop.run_until_complete(asyncio.wait(tasks))
#loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
|
asyncio.gather 和asyncio.wait区别:
在内部wait()使用一个set保存它创建的Task实例。因为set是无序的所以这也就是我们的任务不是顺序执行的原因。wait的返回值是一个元组,包括两个集合,分别表示已完成和未完成的任务。wait第二个参数为一个超时值
达到这个超时时间后,未完成的任务状态变为pending,当程序退出时还有任务没有完成此时就会看到如下的错误提示。
gather的使用
gather的作用和wait类似不同的是。
- gather任务无法取消。
- 返回值是一个结果列表
- 可以按照传入参数的 顺序,顺序输出。

协程和多线程结合
同时多个请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import asyncio
import time
from concurrent.futures import ThreadPoolExecutor
import requests
def myquery(url):
r = requests.get(url)
print(r.text)
return r.text
if __name__ == "__main__":
loop = asyncio.get_event_loop()
executor = ThreadPoolExecutor(3)
urls = ["https://www.psvmc.cn/userlist.json", "https://www.psvmc.cn/login.json"]
tasks = []
start_time = time.time()
for url in urls:
task = loop.run_in_executor(executor, myquery, url)
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print(f"用时{time.time() - start_time}")
|
结果
1
2
3
|
{"code":0,"msg":"success","obj":{"name":"小明","sex":"男","token":"psvmc"}}
{"code":0,"msg":"success","obj":[{"name":"小明","sex":"男"},{"name":"小红","sex":"女"},{"name":"小刚","sex":"未知"}]}
用时0.11207175254821777
|
单个请求添加回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import asyncio
import threading
import time
from concurrent.futures import ThreadPoolExecutor
import requests
def myquery(url):
print(f"请求所在线程:{threading.current_thread().name}")
r = requests.get(url)
return r.text
def myfuture(future):
print(f"回调所在线程:{threading.current_thread().name}")
print(future.result())
if __name__ == "__main__":
loop = asyncio.get_event_loop()
executor = ThreadPoolExecutor(3)
url = "https://www.psvmc.cn/userlist.json"
tasks = []
start_time = time.time()
task = loop.run_in_executor(executor, myquery, url)
future = asyncio.ensure_future(task)
future.add_done_callback(myfuture)
loop.run_until_complete(future)
print(f"用时{time.time() - start_time}")
|
多线程与多进程
多线程
引用模块
1
2
3
4
5
6
7
8
|
from threading import Thread
def func(num):
return num
t = Thread(target=func, args=(100,))
t.start()
t.join()
|
数据通信
1
2
3
4
5
|
import queue
q = queue.Queue()
q.put(1)
item = q.get()
|
锁
1
2
3
4
5
|
from threading import Lock
lock = Lock()
with lock:
pass
|
池化技术
1
2
3
4
5
6
7
8
|
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor() as executor:
# 方法1
results = executor.map(func, [1, 2, 3])
# 方法2
future = executor.submit(func, 1)
result = future.result()
|
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from concurrent.futures import ThreadPoolExecutor
import threading
import time
# 定义一个准备作为线程任务的函数
def action(num):
print(threading.current_thread().name)
time.sleep(num)
return num + 100
if __name__ == "__main__":
# 创建一个包含3条线程的线程池
with ThreadPoolExecutor(max_workers=3) as pool:
future1 = pool.submit(action, 3)
future1.result()
print(f"单个任务返回:{future1.result()}")
print('------------------------------')
# 使用线程执行map计算
results = pool.map(action, (1, 3, 5))
for r in results:
print(f"多个任务返回:{r}")
|
结果
1
2
3
4
5
6
7
8
9
|
ThreadPoolExecutor-0_0
单个任务返回:103
------------------------------
ThreadPoolExecutor-0_0
ThreadPoolExecutor-0_1
ThreadPoolExecutor-0_2
多个任务返回:101
多个任务返回:103
多个任务返回:105
|
多进程
引用模块
1
2
3
4
5
6
7
8
|
from multiprocessing import Process
def func(num):
return num
t = Process(target=func, args=(100,))
t.start()
t.join()
|
数据通信
1
2
3
4
|
import multiprocessing
q = multiprocessing.Queue()
q.put(1)
item = q.get()
|
锁
1
2
3
4
5
|
from multiprocessing import Lock
lock = Lock()
with lock:
pass
|
池化技术
1
2
3
4
5
6
7
8
|
from concurrent.futures import ProcessPoolExecutor
with ProcessPoolExecutor() as executor:
# 方法1
results = executor.map(func, [1, 2, 3])
# 方法2
future = executor.submit(func, 1)
result = future.result()
|
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from concurrent.futures import ProcessPoolExecutor
import multiprocessing
import time
# 定义一个准备作为进程任务的函数
def action(num):
print(multiprocessing.current_process().name)
time.sleep(num)
return num + 100
if __name__ == "__main__":
# 创建一个包含3条进程的进程池
with ProcessPoolExecutor(max_workers=3) as pool:
future1 = pool.submit(action, 3)
future1.result()
print(f"单个任务返回:{future1.result()}")
print('------------------------------')
# 使用线程执行map计算
results = pool.map(action, [1, 3, 5])
for r in results:
print(f"多个任务返回:{r}")
|
结果
1
2
3
4
5
6
7
8
9
|
SpawnProcess-1
单个任务返回:103
------------------------------
SpawnProcess-2
SpawnProcess-3
SpawnProcess-1
多个任务返回:101
多个任务返回:103
多个任务返回:105
|
多进程/多线程/协程对比
异步 IO(asyncio)、多进程(multiprocessing)、多线程(multithreading)
IO 密集型应用CPU等待IO时间远大于CPU 自身运行时间,太浪费;
常见的 IO 密集型业务包括:浏览器交互、磁盘请求、网络爬虫、数据库请求等
Python 世界对于 IO 密集型场景的并发提升有 3 种方法:多进程、多线程、多协程;
理论上讲asyncio是性能最高的,原因如下:
- 进程、线程会有CPU上下文切换
- 进程、线程需要内核态和用户态的交互,性能开销大;而协程对内核透明的,只在用户态运行
- 进程、线程并不可以无限创建,最佳实践一般是 CPU*2;而协程并发能力强,并发上限理论上取决于操作系统IO多路复用(linux下是 epoll)可注册的文件描述符的极限
那asyncio的实际表现是否如理论上那么强,到底强多少呢?我构建了如下测试场景:
请求10此,并sleep 1s模拟业务查询
- 方法 1;顺序串行执行
- 方法 2:多进程
- 方法 3:多线程
- 方法 4:asyncio
- 方法 5:asyncio+uvloop
最后的asyncio+uvloop和官方asyncio 最大不同是用 Cython+libuv 重新实现了asyncio 的事件循环(event loop)部分,
官方测试性能是 node.js的 2 倍,持平 golang。

顺序串行执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import time
def query(num):
print(num)
time.sleep(1)
def main():
for h in range(10):
query(h)
# main entrance
if __name__ == '__main__':
start_time = time.perf_counter()
main()
end_time = time.perf_counter()
print(f"时间差:{end_time-start_time}")
|
多进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from concurrent import futures
import time
def query(num):
print(num)
time.sleep(1)
def main():
with futures.ProcessPoolExecutor() as executor:
for future in executor.map(query, range(10)):
pass
# main entrance
if __name__ == '__main__':
start_time = time.perf_counter()
main()
end_time = time.perf_counter()
print(f"时间差:{end_time-start_time}")
|
多线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from concurrent import futures
import time
def query(num):
print(num)
time.sleep(1)
def main():
with futures.ThreadPoolExecutor() as executor:
for future in executor.map(query, range(10)):
pass
# main entrance
if __name__ == '__main__':
start_time = time.perf_counter()
main()
end_time = time.perf_counter()
print(f"时间差:{end_time-start_time}")
|
asyncio
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import asyncio
import time
async def query(num):
print(num)
await asyncio.sleep(1)
async def main():
tasks = [asyncio.create_task(query(num)) for num in range(10)]
await asyncio.gather(*tasks)
# main entrance
if __name__ == '__main__':
start_time = time.perf_counter()
asyncio.run(main())
end_time = time.perf_counter()
print(f"时间差:{end_time-start_time}")
|
asyncio+uvloop
注意
windows上不支持uvloop。
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import asyncio
import uvloop
import time
async def query(num):
print(num)
await asyncio.sleep(1)
async def main():
tasks = [asyncio.create_task(query(host)) for host in range(10)]
await asyncio.gather(*tasks)
# main entrance
if __name__ == '__main__':
uvloop.install()
start_time = time.perf_counter()
asyncio.run(main())
end_time = time.perf_counter()
print(f"时间差:{end_time-start_time}")
|
运行时间对比
|
方式 |
运行时间 |
|
串行 |
10.0750972s |
|
多进程 |
1.1638731999999998s |
|
多线程 |
1.0146456s |
|
asyncio |
1.0110082s |
|
asyncio+uvloop |
1.01s |
可以看出: 无论多进程、多线程还是asyncio都能大幅提升IO 密集型场景下的并发,但asyncio+uvloop性能最高!

原文链接:
https://www.psvmc.cn/article/2021-11-24-python-async.html