视频创作者饭碗不保!Meta和谷歌推出的AI黑科技来抢活儿了

9月末,Meta发布了新款AI系统Make-A-Video,开启了“用嘴做视频”的时代。谷歌不甘落后,在Make-A-Video推出后一周带着Imagen Video和Phenaki两款类似的人工智能产品登场。
这几款产品吸引了技术圈、流媒体行业和吃瓜者的一波又一波的关注,不少大V纷纷感慨原来AI在不知不觉间已经发展得如此智能,自己似乎有些适应不了AI的进化速度了。。。
那么,Meta和谷歌推出的这几款AI产品究竟有哪些逆天功能?AI的发展又会给Web3时代的内容创作带来怎样的改变?
“用嘴做视频”的时代到来了吗?
首先,Meta推出的Make-A-Video是一款可以直接基于文字生成短视频的人工智能系统。
根据Meta AI官网生成的部分短视频内容显示,Make-A-Video允许用户输入一些单词或句子,比如“一只披着红色斗篷、穿着超人服装的狗在天空中飞翔”,然后系统会生成一个时长5秒的视频片段。
除此之外,官网示例还有UFO在火星着陆、画家在画布上画画、马喝水等短视频片段。

除了文本输入外,Make-A-Video还可以根据其他视频或图片制作新视频,或是生成连接图像的关键帧,让静态图片动起来。
不过,Make-A-Video目前只能生成5秒的16帧/秒无声片段,画面只能描述一个动作或场景,像素也只有768×768。
并且从官网示例来看,虽然Make-A-Video生成视频的画面准确率很高,但动态效果生硬、部分画面要素过于猎奇,甚至还有些不符合常理,总体上来说视频效果还是不尽如人意。
不过,对于AI产品的视频清晰度和画面时长问题,谷歌AI又一次带给大家惊喜。
此次谷歌推出的两款产品中,其中一个叫Imagen Video。Imagen Video是一款和Make-A-Video类似的产品,可以根据文本生成视频。
与Meta的产品相比,Imagen Video可以生成1280×768的24帧/秒高清视频片段,至少对于目前人工智能发展来看,技术已经相当可以了。不少网友看了产品网站之后纷纷感慨“误以为进了视频素材网站”。
在官方发表的论文中写到,Imagen Video除了能够生成高清视频外,还会在公开可用的LAION-400M图像文本数据集、1400万个视频文本对和6000万个图像文本对上进行训练,因此还具备一些纯从数据中学习的非结构化生成模型所没有的独特功能。
例如,它能理解并生成不同艺术风格的作品,如“水彩”或者“像素画”,或者直接“梵高风格绘画”等。
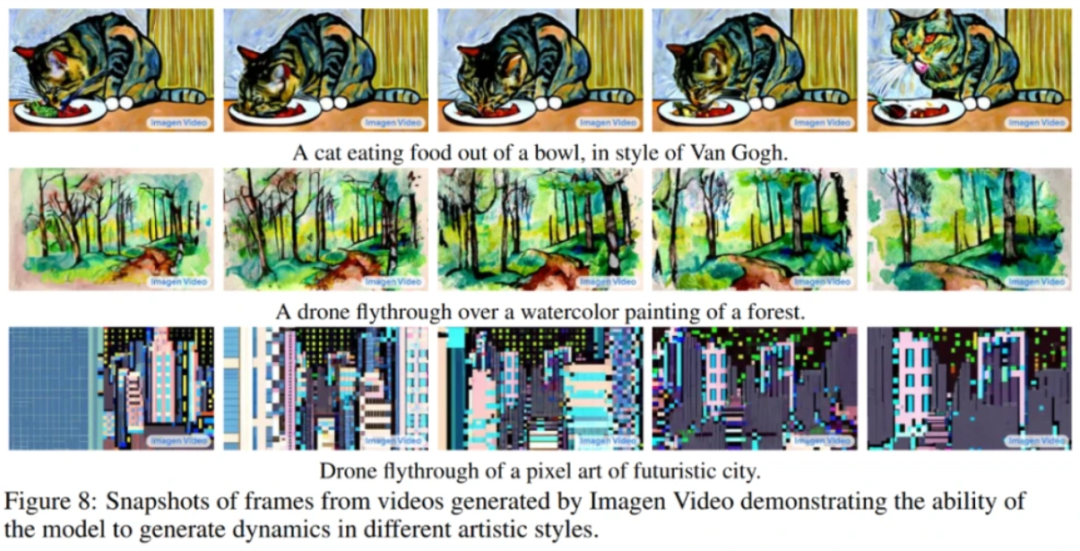
它还能理解物体的3D结构,并基于理解生成旋转对象的视频,同时物体的大致结构也能保留,至少不会变形。

最后,它还继承了此前Imagen文本生成图像系统的准确描绘文字的能力,在此基础上仅靠简单描述产生各种创意动画,为众多自媒体行业的朋友们提供了一条素材选择、制作的捷径。
而谷歌此次推出的另一款产品Phenaki,则是能根据200个词左右的提示语生成2分钟以上的长视频,讲述一个完整的故事。
虽然图片画质不如Imagen Video,但Phenaki所呈现的视频非常贴近文本描述,而且谷歌认为它不仅可用来产生描述单个概念的视频,还能可根据一系列的文本,产生有连贯性的多个视频。
基于移动互联网的普及,产生的图像资料集、视频资料库数据非常庞大。
不管是Meta的Make-A-Video还是谷歌的Imagen Video或Phenaki,都可以利用现有的视频与图像数据资源进行AI训练,让生成的AI作品更加真实,也为之后的内容生产提供了新的思路。
对AI还有哪些期待?
如今,互联网内容形态正在变得丰富多样,从文字、图片到音乐、视频,再到直播、游戏,内容需求无处不在,用户每天消费的内容不断增加,但是靠人力创作已经很难满足需求的增长。
随着科技技术的提升,AI让内容生产变得更容易、更个性。
尽管从画面效果和情节串联上,现有的AI产品还远远比不上人力创作,但Meta和谷歌此次的新产品着实让人眼前一亮,并且让人们开始期待AI将会如何引领内容生产的发展。
可以说,从UGC、PGC到如今的AIGC(人工智能生产内容),内容生产正在进入一段新的革命,不仅会将内容产业的繁荣推向新的高度,也将对社会的演进产生更深远的影响。
最后,我们不妨看得更长远些,无论是元宇宙还是Web3,下一代互联网的繁荣需要海量的数字内容,同时对内容的数量、形式和交互性都提出了更高的要求。从这个角度来看,AIGC便显得尤为必要。
在可预见的未来里,AIGC会改变很多行业。那我们不妨多些期待,去拥抱AIGC时代的到来。