一些长时间GC停顿问题的排查及解决办法
原文地址:https://mp.weixin.qq.com/s/fP--JJnkTR92NWdZtdEgqQ
作者:阿飞的博客

对于许多企业级应用,尤其是OLTP应用来说,长暂停很可能导致服务超时,而对这些运行在JVM上的应用来说,垃圾回收(GC)可能是长暂停最主要的原因。本文将描述一些可能碰到GC长暂停的不同场景,以及说明我们如何排查和解决这些GC停顿的问题。
下面是一些应用在运行时,可能导致GC长暂停的不同场景。
1. 碎片化
这个绝对要排在第一位。因为,正是因为碎片化问题--CMS最致命的缺陷,导致这个统治了OLAP系统十多年的垃圾回收器直接退出历史舞台(CMS已经是deprecated,未来版本会被移除,请珍惜那些配置了CMS的JVM吧),面对G1以及最新的ZGC,天生残(碎)缺(片)的CMS毫无还手之力。
对于CMS,由于老年代的碎片化问题,在YGC时可能碰到晋升失败(promotion failures,即使老年代还有足够多有效的空间,但是仍然可能导致分配失败,因为没有足够连续的空间),从而触发Concurrent Mode Failure,发生会完全STW的FullGC。FullGC相比CMS这种并发模式的GC需要更长的停顿时间才能完成垃圾回收工作,这绝对是JAVA应用最大的灾难之一。
为什么CMS场景下会有碎片化问题?由于CMS在老年代回收时,采用的是标记清理(Mark-Sweep)算法,它在垃圾回收时并不会压缩堆,日积月累,导致老年代的碎片化问题会越来越严重,直到发生单线程的Mark-Sweep-Compact GC,即FullGC,会完全STW。如果堆比较大的话,STW的时间可能需要好几秒,甚至十多秒,几十秒都有可能。
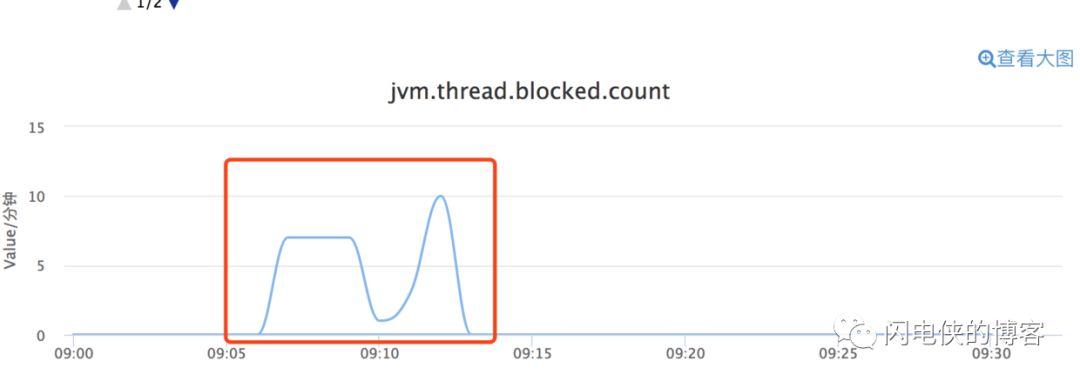
接下来的cms gc日志,由于碎片率非常高,从而导致promotion failure,然后发生concurrent mode failure,触发的FullGC总计花了17.1365396秒才完成:



2. GC时操作系统的活动
当发生GC时,一些操作系统的活动,比如swap,可能导致GC停顿时间更长,这些停顿可能是几秒,甚至几十秒级别。
如果你的系统配置了允许使用swap空间,操作系统可能把JVM进程的非活动内存页移到swap空间,从而释放内存给当前活动进程(可能是操作系统上其他进程,取决于系统调度)。SwApping由于需要访问磁盘,所以相比物理内存,它的速度慢的令人发指。所以,如果在GC的时候,系统正好需要执行Swapping,那么GC停顿的时间一定会非常非常非常恐怖。
下面是一段持续了29.48秒的YGC日志:

最后一行[Times: user=915.56, sys=6.35, real=29.48 secs]中real就是YGC时应用真实的停顿时间。
发生YGC的这个时间点,vmstat命令输出结果如下:

YGC总计花了29秒才完成。vmstat命令输出结果表示,可用swap空间在这个时间段减少了600m。这就意味着,在GC的时候,内存中的一些页被移到了swap空间,这个内存页不一定属于JVM进程,可能是其他操作系统上的其他进程。
从上面可以看出,操作系统上可用物理内容不足以运行系统上所有的进程,解决办法就是尽可能运行更少的进程,增加RAM从而提升系统的物理内存。在这个例子中,Old区有9G,但是只使用了1.8G(mark-sweep generation total 9437184K, used 1860619K)。我们可以适当的降低Old区的大小以及整个堆的大小,从而减少内存压力,最小化系统上的应用发生swapping的可能。
除了swapping以外,我们也需要监控了解长GC暂停时的任何IO或者网络活动情况等, 可以通过IOStat和netstat两个工具来实现. 我们还能通过mpstat查看CPU统计信息,从而弄清楚在GC的时候是否有足够的CPU资源。
3. 堆空间不够
如果应用程序需要的内存比我们执行的Xmx还要大,也会导致频繁的垃圾回收,甚至OOM。由于堆空间不足,对象分配失败,JVM就需要调用GC尝试回收已经分配的空间,但是GC并不能释放更多的空间,从而又回导致GC,进入恶性循环。
应用运行时,频繁的FullGC会引起长时间停顿,在下面这个例子中,Perm空间几乎是满的,并且在Perm区尝试分配内存也都失败了,从而触发FullGC:

同样的,如果在老年代的空间不够的话,也会导致频繁FullGC,这类问题比较好办,给足老年代和永久代,不要做太抠门的人了,嘿嘿。
4. JVM Bug
什么软件都有BUG,JVM也不例外。有时候,GC的长时间停顿就有可能是BUG引起的。例如,下面列举的这些JVM的BUG,就可能导致Java应用在GC时长时间停顿。

如果你的JDK正好是上面这些版本,强烈建议升级到更新BUG已经修复的版本。
5. 显示System.gc调用
检查是否有显示的System.gc调用,应用中的一些类里,或者第三方模块中调用System.gc调用从而触发STW的FullGC,也可能会引起非常长时间的停顿。如下GC日志所示,Full GC后面的(System)表示它是由调用System.GC触发的FullGC,并且耗时5.75秒:

如果你使用了RMI,能观察到固定时间间隔的FullGC,也是由于RMI的实现调用了System.gc。这个时间间隔可以通过系统属性配置:

JDK 1.4.2和5.0的默认值是60000毫秒,即1分钟;JDK6以及以后的版本,默认值是3600000毫秒,即1个小时。
如果你要关闭通过调用System.gc()触发FullGC,配置JVM参数 -XX:+DisableExplicitGC即可。
那么如何定位并解决这类问题问题呢?
- 配置JVM参数:-XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps and -XX:+PrintGCApplicationStoppedTime. 如果是CMS,还需要添加-XX:PrintFLSStatistics=2,然后收集GC日志。因为GC日志能告诉我们GC频率,是否长时间停顿等重要信息。
- 使用vmstat, iostat, netstat和mpstat等工具监控系统全方位健康状况。
- 使用GCHisto工具可视化分析GC日志,弄明白消耗了很长时间的GC,以及这些GC的出现是否有一定的规律。
- 尝试从GC日志中能否找出一下JVM堆碎片化的表征。
- 监控指定应用的堆大小是否足够。
- 检查你运行的JVM版本,是否有与长时间停顿相关的BUG,然后升级到修复问题的最新JDK。