网络性能debug参数整理
无线用户连接使用WiFi时有抱怨说,微信连接正常,但是有时候发送图片甚至短消息时出现转圈现象。刷抖音、腾讯视频、看B站或是开启浏览器时部分图片打不开,开启某一个视屏时一直转圈等问题。
出现这类问题时,首先需要排除网络问题,排除无线部分的干扰、有线部分的延迟。分为几个部分进行调查
无线网络检查
1. 连接无线后,通过ping检查无线到本地网关之间的丢包率、延迟、抖动等是否异常
(排除无线信道干扰,信号不好等因素导致的网络问题)

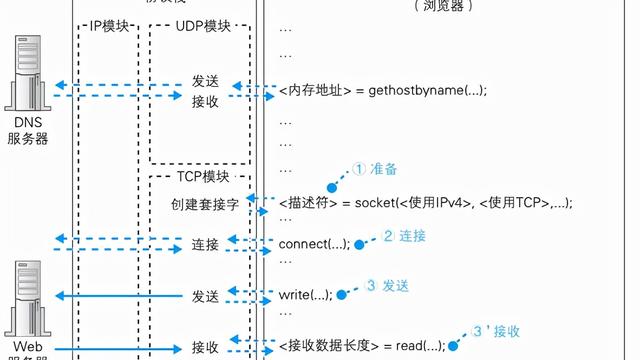
2. 检查DNS速度和应答
开启网址时,首先通过DNS获得目标IP地址,从而建立网络连接。
有时候,网络速度慢有可能时因为上一层DNS解析服务器响应慢导致页面打开慢,可通过在网关设备上运行dig命令查看dns解析的响应时间, 如:

也可在终端上,抓取DNS报文计算请求与响应报文时间戳差来了解DNS响应状况。
排除掉一些基本的网络问题后,若问题没能解决,就得从系统的角度去分析性能问题了。
有些时候,需要收集一些现场的计数(可能会直接找到问题所在),但大多数情况都需要做进一步的模拟测试,以确认问题所在。
现场信息收集
现场参数检查:
1. 检查session情况(做NAT的网关设备一般为linux或者openwrt系统)
查看nf_conntrack_count计数 --- 当前连接数
cat /proc/sys/net/netfilter/nf_conntrack_count
2. 查看nf_conntrack表最大连接数
cat /proc/sys/net/netfilter/nf_conntrack_max
可通过如下命令临时修改:
sysctl -w net.netfilter.nf_conntrack_max=65536
echo 16384 > /sys/module/nf_conntrack/parameters/hashsize
注意:
hashsize = nf_conntrack_max / 4
或者:
sysctl -w net.ipv4.ip_conntrack_max=65536
3. 查看nf_conntrack的TCP连接记录时间
cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_established
4. 通过内核参数查看命令,查看所有参数配置
sysctl -a | grep nf_conntrack
5. 查看具体的session信息
cat /proc/net/nf_conntrack
当获得一些现场信息后,需要在实验室环境构造类似的环境,模拟用户session变化情况(出现问题时,很大可能是因为资源死锁或限制导致了类似的性能,因此需要不断变化端口、IP、协议等参数,来逐步确认问题所在)
环境模拟
在进行本地机器进行模拟测试时,可能需要调整一些系统参数,以便使作为辅测设备本身不成为瓶颈。如:
- 客户端连接数限制
单个压测客户端(一个IP地址)能承载的并发连接数是有限制的(其实是TCP/UDP的端口数目限制),这个上限是 65535(一般1024下的端口作为系统使用,所以65535只是一个最大上限),不可能更多。
- File Descriptors 限制
每一个建立的连接在 Linux 上都可视为一个打开的文件,会占用一个 File Descriptor,所以 ulimit 内各种限制中跟并发连接数最相关的是进程最大能打开的 File Descriptor数量。
[root@kvmserver1 ~]# ulimit -n
1024
可根据设备内存状况,修改该数值
cat /etc/security/limits.conf
如修改为
* soft nofile 10000
* hard nofile 10000
普通用户默认使用的是 soft 限制,并且能够通过 ulimit -n 修改 soft 限制到最大跟 hard 一样,超过 hard 的话会报错:
ulimit: open files: cannot modify limit: Operation not permitted
若使用的连接需要特别的多,可能会需要调整下面这几个值。这几个值限制文件 Handle最大数量都很大,默认为 1024 * 1024,但也能调整的更大:
fs.file-max = 1000000
fs.file-nr = 13920 0 1000000
fs.nr_open = 1048576
file-max 是 kernel 能分配的文件 Handle 最大数量
file-nar 有三个值,动态变化的,第一个值是当前已经分配的文件 Handle数量,第二个值是分配但是未使用的文件 Handle 数一般都是 0,最后一个实际就是 file-max 的值,表示系统最大分配的文件 Handle 数量。当系统内文件 Handle 数超过 file-max 后,一样会报 Too many open files。
nr_open 是单个进程能分配的最大文件 Handle 数量,这个值一定比 file-max 小,并且一定要比 limits.conf 内的 soft nofile, hard nofile 大,不然 soft nofile, hard nofile 设置再大都没用。

- 自动分配本地端口范围
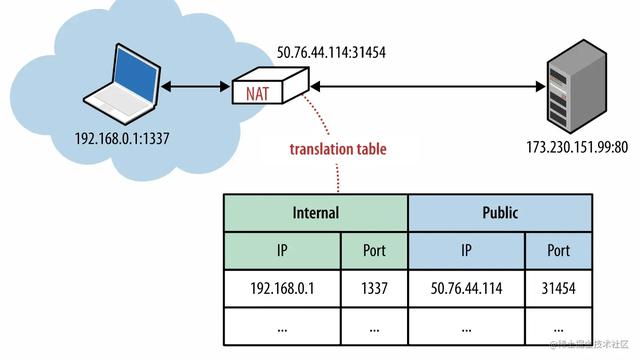
确定一个连接需要五个元素 Source IP + Source Port + Destination IP + Destination Port + 协议(TCP/UDP),一般客户端在连服务端的时候只要获取到服务端的 Destination IP 和 Destination Port 即可,Source IP 是客户端自己的 IP,客户端系统会自动分配一个 Source Port 来建立连接。而这个 Source Port 的选择范围是可通过 sysctl net.ipv4.ip_local_port_range 参数来定制的。可以执行一下这个命令来获取当前系统的设定,例如:
sysctl -w net.ipv4.ip_local_port_range="15000 61000"
即表示在与 remote 服务建立连接时,系统只能自动从 15000 至 61000 中选择一个作为 Local Port,也就是 Source Port。
如果希望压测客户端和服务器建立大量的连接,则需要将该范围设置的大一些,给客户端留足端口数(如 1024 - 65535),如果留的端口不足的话会报错。
- 端口复用
TCP 连接断开之后主动发起 FIN 的一方最终会进入 TIME_WAIT 状态,处在这个状态时连接之前所占用的端口不能被下一个新的连接使用,必须等待一段时间之后才能使用。如果是单独测试并发连接峰值,减少 TIME_WAIT 连接数可能用处不大,但如果是连续的测试,每次关闭客户端准备再来下一轮测试时必须等足 TIME_WAIT 时间,如果 TIME_WAIT 时间比较长就比较烦,所以减少 TIME WAIT 对测试有一定好处。因为一般压测都是内网,所以 TIME WAIT 清理方面能稍微激进一些。可考虑设置:
Client 开启TCP Timestamps 后开启 net.ipv4.tcp_tw_reuse 或 net.ipv4.tcp_tw_recycle,
将 net.ipv4.tcp_max_tw_buckets 设置的很小,TIME WAIT 连接超过该值后直接清理。因为一般测试都在内网,没有 NAP 的情况下 Per-Host 的 Timestamp 配合 PAWS 一般能消除跨连接数据包错误到达问题。
通过如下命令可查看当前TIME_WAIT的数量
netstat -an | grep "TIME_WAIT" | wc -l
考虑压测结束的时候由 Client 主动断开连接,并且设置 SO_LINGER 为 0,断开连接时候直接发 RST;
sysctl -w net.ipv4.tcp_timestamps=1
#开启TCP时间戳
#以一种比重发超时更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。
sysctl -w net.ipv4.tcp_tw_reuse=1
# 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
sysctl -w net.ipv4.tcp_tw_recycle=1
# 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
sysctl -w net.ipv4.tcp_max_tw_buckets=5000
# 5000 表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息
sysctl -w net.ipv4.tcp_keepalive_time=1200
#1200 表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟,单位为秒。
net.ipv4.tcp_fin_timeout=30
#30表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。单位为秒。
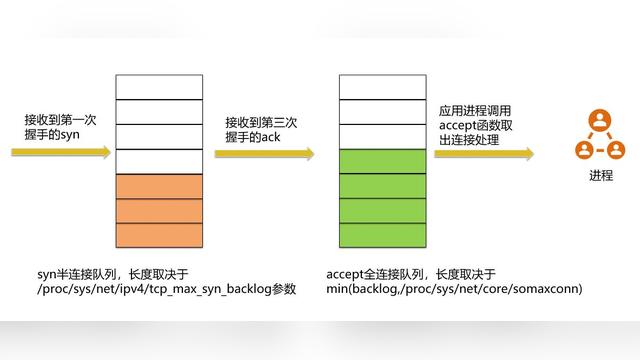
- tcp syn flood丢弃限制
在测试中,有时需要模拟大量的TCP连接,但并发连接数量多了,就会出现很多连接建立失败,同时在Server会看到如下的一些日志打印
TCP: request_sock_TCP: Possible SYN flooding on port 45000. Sending cookies. Check SNMP counters
所谓的TCP SYN Flood的攻击,其实就是利用TCP协议三次握手过程进行的攻击:如果一个客户端向另一个客户端发起TCP连接时,需要先发送TCP SYN报文,对端收到报文后回应TCP SYN+ACK报文,发起方再发送TCP ACK,这样握手成功,连接也就建立起来了。
具体实现时,当接收端收到SYN报文,回应SYN+ACK报文前,需要维护一个队列(未连接队列 ---表示收到了SYN, 状态标识为SYN_RECV), 当收到对端的ACK报文时,从队列中移除,进入ESTABLISHED状态。
[root@centos8 ~]# sysctl -a | grep cookies
net.ipv4.tcp_syncookies = 1
#表示开启CentOS SYN Cookies,这是个bool值。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量CentOS SYN攻击,默认为0,表示关闭;
能够有效防范SYN Flood攻击的手段之一就是SYN Cookie。SYN Cookie原理由D. J. Bernstain和 Eric Schenk发明。SYN Cookie是对TCP服务器端的三次握手协议作一些修改,专门用来防范CentOS SYN Flood攻击的一种手段,它的原理是, 在TCP服务器收到TCP SYN包并返回TCP SYN+ACK包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。在收到TCP ACK包时,TCP服务器在根据那个cookie值检查这个TCP ACK包的合法性。如果合法,再分配专门的数据区进行处理未来的TCP连接
[root@centos8 ~]# sysctl -a | grep backlog
net.core.netdev_max_backlog = 1000
#该参数决定了,网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。将数据包放入 CPU 的 backlog 的时候需要看队列内当前积压的数据包有多少,超过 net.core.netdev_max_backlog 后要丢弃数据
net.ipv4.tcp_max_syn_backlog = 256
#表示SYN队列长度,默认1024,改成8192,可以容纳更多等待连接的网络连接数。
- 其他参数设置
net.core.netdev_max_backlog = 400000
#该参数决定了,网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.core.optmem_max = 10000000
#该参数指定了每个套接字所允许的最大缓冲区的大小
#指定了接收套接字缓冲区大小的缺省值(以字节为单位)。
对收消息过程来说,Socket 占用内存量就是 Receive Queue、Prequeue、Backlog、Out of order 队列内排队的 sk_buff 占用内存总数。当数据被拉取到 User Space 后,就不再占用 Socket 的内存。这里有几个需要注意的,一个是发送过程和接收过程共用分配的 Socket 内存总量 sk_forward_alloc。对收消息过程来说,Receive Queue、Prequeue、Backlog、Out of order 共同占用的内存量不能超过 sk->sk_rcvbuf。如果用户进程处理消息较慢,大量消息在 Receive Queue、Prequeue、Backlog 内排队,则 Out of order 队列的大小会受到限制,而 Out of order 队列大小会影响 TCP Receive Window 的大小,从而在用户进程处理消息慢的时候能通过减小 Receive Window 让对端减慢发消息速度。一般来说 Socket 的 sk_rcvbuf 受到如下两个配置的控制:
sysctl -w net.core.rmem_max=8388608
sysctl -w net.core.rmem_default=8388608
net.core.somaxconn = 100000
#Linux kernel参数,表示socket监听的backlog(监听队列)上限
net.core.wmem_default = 11059200
#定义默认的发送窗口大小;对于更大的 BDP 来说,这个大小也应该更大。
net.core.wmem_max = 11059200
#定义发送窗口的最大大小;对于更大的 BDP 来说,这个大小也应该更大。
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
#严谨模式 1 (推荐)
#松散模式 0
net.ipv4.tcp_congestion_control = reno cubic
#默认推荐设置是 htcp
net.ipv4.tcp_window_scaling = 0
#关闭tcp_window_scaling
#启用 RFC 1323 定义的 window scaling;要支持超过 64KB 的窗口,必须启用该值。
net.ipv4.tcp_ecn = 0
#把TCP的直接拥塞通告(tcp_ecn)关掉
net.ipv4.tcp_sack = 1
#关闭tcp_sack
#启用有选择的应答(Selective Acknowledgment),
#这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);
#(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用。
net.ipv4.tcp_max_tw_buckets = 10000
#表示系统同时保持TIME_WAIT套接字的最大数量
net.ipv4.tcp_keepalive_probes = 3
#如果对方不予应答,探测包的发送次数
net.ipv4.tcp_keepalive_intvl = 15
#keepalive探测包的发送间隔
对于 TCP 连接来说稍微特别一些,除了 sk_rcvbuf 的限制之外,TCP 还有自己的一套 Socket 接收 Buffer 的限制机制,能根据系统当前所有 TCP 连接占用的总内存量判断系统压力级别,来决定是否能为某个 Socket 继续分配接收 Buffer。这里要区分清楚的是 sk_rcvbuf 是 Socket 接收 buffer 分配的上限,而 Socket 当前实际分配的接收 buffer 大小是 sk_rmem_alloc 记录。连接每次收到一个 sk_buff 放入 Socket 队列之后,就会增加 sk_rmem_alloc 并减少 sk_forward_alloc 的值,sk_forward_alloc 不够的时候就需要向系统申请配额。如果系统上只有一个连接,那 Socket 分配的接收 Buffer 没有达到 sk_rcvbuf 之前,系统可能都会允许给这个连接继续分配接收 buffer。但是如果系统上有几百万连接,占用了大量的内存,每个连接都分为 sk_rcvbuf 这么多接收 Buffer 的话系统可能会支撑不住,所以 TCP 的接收 Buffer 的限制机制就是在 Socket 的接收 Buffer 还未到达 sk_rcvbuf 之前就根据当前系统负载情况,在负载特别大的时候拒绝 Socket 扩大接收 buffer 的申请。
跟 tcp 连接的这个接收 Buffer 限制机制相关的配置是 net.ipv4.tcp_rmem ,是个数组,有三个值分别是 min, default, max,给 TCP Socket 分配 sk_rcvbuf 时会根据系统当前压力级别从 min, default, max 三个值中选择,用以控制 Socket 接收 Buffer 的大小。
net.ipv4.tcp_mem
#确定 TCP 栈应该如何反映内存使用;每个值的单位都是内存页(通常是 4KB)。
#第一个值是内存使用的下限。
#第二个值是内存压力模式开始对缓冲区使用应用压力的上限。
#第三个值是内存上限。在这个层次上可以将报文丢弃,从而减少对内存的使用。对于较大的 BDP 可以增大这些值(但是要记住,其单位是内存页,而不是字节)。
net.ipv4.tcp_rmem
#与 tcp_wmem 类似,不过它表示的是为自动调优所使用的接收缓冲区的值。
net.ipv4.tcp_wmem = 30000000 30000000 30000000
#为自动调优定义每个 socket 使用的内存。
#第一个值是为 socket 的发送缓冲区分配的最少字节数。
#第二个值是默认值(该值会被 wmem_default 覆盖),缓冲区在系统负载不重的情况下可以增长到这个值。
#第三个值是发送缓冲区空间的最大字节数(该值会被 wmem_max 覆盖)。
net.ipv4.tcp_slow_start_after_idle = 0
#关闭tcp的连接传输的慢启动,即先休止一段时间,再初始化拥塞窗口。
net.ipv4.route.gc_timeout = 100
#路由缓存刷新频率,当一个路由失败后多长时间跳到另一个路由,默认是300。
net.ipv4.tcp_syn_retries = 1
#在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.icmp_echo_ignore_broadcasts = 1
# 避免放大攻击
net.ipv4.icmp_ignore_bogus_error_responses = 1
# 开启恶意icmp错误消息保护
net.inet.udp.checksum=1
#防止不正确的udp包的攻击
net.ipv4.conf.default.accept_source_route = 0
#是否接受含有源路由信息的ip包。参数值为布尔值,1表示接受,0表示不接受。
#在充当网关的linux主机上缺省值为1,在一般的linux主机上缺省值为0。
#从安全性角度出发,建议关闭该功能。