腾讯云把向量数据库“卷”到哪一步了?
“不是我不明白,这世界变化快”,崔健在20世纪写下的这句歌词,放在刚刚过去的2023年,也同样适用。技术风向的变化之快,让不少人感到惊讶,向量数据库这一年的潮起潮落,就是一个典型的例子。
2023年初大模型、生成式 AI的起飞,也带来了向量数据库的火爆,投融资项目爆发式增长,传统数据库厂商和公有云厂商都推出了相关产品。然而一年狂飙之后,市场又开始退潮,前不久全球最著名的 AI 项目之一AutoGPT 宣布,不再使用向量数据库。

向量数据库真的是AI革命中的组成部分吗?这一市场有哪些参与者?腾讯云为代表的公有云厂商,又在这场技术创新中发挥了什么作用?
向量数据库,刚刚开始
新技术的火爆,必然会伴随炒作和泡沫,但向量作为大模型理解世界的数据形式,向量数据库作为AI革命重要基建的位置,长期来看,是不会动摇的。
为什么这么说?
向量数据库并不是一种特别新的数据库技术,在AI领域已经应用了七八年,谷歌在2015年就宣布使用RankBrain语义检索来处理搜索任务。如果说数据库是数据的“硬盘”,那么,向量数据库就是更适合AI体质的“硬盘”。
其“AI原生”的体质,具体表现在几个方面:
1.更高的效率。AI算法,要从图像、音频和文本等海量的非结构化数据中学习,提取出以向量为表示形式的“特征”,以便模型能够理解和处理。因此,向量数据库比传统基于索引的数据库有明显优势。
2.更低的成本。大模型要从一种新技术转化为产业价值,必须达到合理的投入产出比,而向量数据库可以有效减少存储和计算成本。一个公开数据是,通过腾讯云向量数据库,QQ音乐人均听歌时长提升3.2%、腾讯视频有效曝光人均时长提升1.74%、QQ浏览器成本降低37.9%,就在于检索效率、运行稳定性、运营效率、推荐算法等,有了较大的提升。
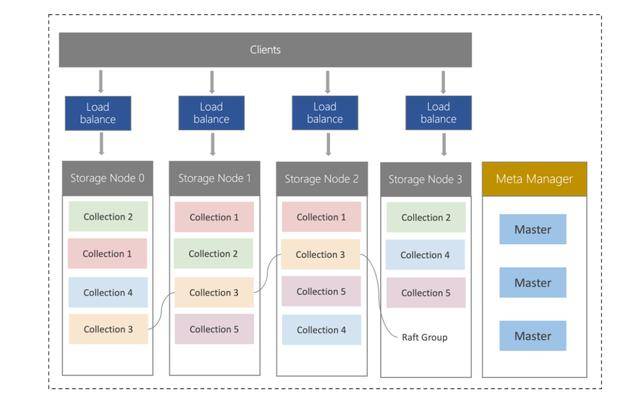
(腾讯云数据库产品架构)
3.更强的数据安全。有个企业直言:我沉淀了几十年的内部数据,是我的的核心竞争力,让我无偿去公开给大模型做训练,我肯定不愿意。想做大模型,还要确保数据的隐私安全,就必须与数据库产品做好配合,这给向量数据库的本地部署带来了广阔的需求。
4.更大的扩展性。随着大模型走向行业应用,垂直领域的AI用例不断增多,汹涌的数据洪潮和存算任务,会带来大量向量搜索的需求。而向量数据库嵌入向量的长度不受限制,具有良好的扩展性,可以根据AI用例和模型而变化,更好地处理大规模数据集。
所以说,除非大模型技术,在短期内发生颠覆性改变,否则落地应用还是需要向量检索和向量数据库。而作为大模型技术标杆的OpenAI最近也透露:我们可能已经非常接近实现通用人工智能(AGI),应该以通用人工智能的实现为前提进行创业和技术开发。
由此可以肯定,向量数据库市场必然还会迎来一轮增长。年底趋于冷静,只是2023年热情过度高涨的适当回调。
两股新势力,云是方向
从引爆到饱和,向量数据库市场的发展速度迅猛,也吸引了“群雄逐鹿”。
传统数据库厂商不必多说,既有相应的能力建设,也有一定的客户基础,推出相关产品是必然。一些在AI领域积淀已久的科技大厂,如谷歌、微软、Meta、百度等大厂,都有向量数据库的技术积累,也都可以向外输出相关能力和产品。这些我们都比较熟悉了。
而上一年狂飙突进的两股新势力,成为市场上的黑马,分别是创业公司和公有云。
以上半年爆火的AI创业新秀Pinecone为代表。Pinecone是闭源的领跑者,凭借良好的开箱即用的产品体验,获得了非常大的增长,B轮估值达到7.5亿美元。其他竞争者大多建立在开源项目的基础上。
总体来说,这些创业“独角兽”的向量数据库公司,固然新锐,但长期盈利能力还有待验证。原因是,其客户大多是尝鲜、实验性质。
一般来说,企业需要先将非结构化的私密数据,进行一个小的模型,进行向量化,产生一个向量的矩阵,再存储到向量数据库里,来供大模型学习和检索。这个过程涉及大量的工程化,会耗费企业许多开发人员、时间成本,一开始可能会因为AI大模型很火而对向量数据库产生兴趣,但能否真正在业务中落地还是个未知数,因此,长期付费意愿还有较大的不确定性。
另一股“新势力”:公有云厂商,也是向量数据库的积极参与者。
不是所有企业都有能力自建大模型所需要的基础设施,通过MaaS(模型即服务)业务来训练应用大模型,是更灵活的选择。

此外,上云用数赋智是大势所趋,很多政企客户往往会选择公有云或行业云来满足其业务需求,将数据迁移到云上,对云数据库的关注度和接受度上升,而这些用户在探索大模型时,会倾向于以整体解决方案的形式来交付,这就给了云厂商参与游戏的机会,同时也要求云厂商提供向量数据库的全栈支持。
以腾讯云为代表,腾讯云的AI 原生(AI Native)向量数据库Tencent Cloud VectorDB是国内首个从接入层、计算层、到存储层提供全生命周期AI化的向量数据库。
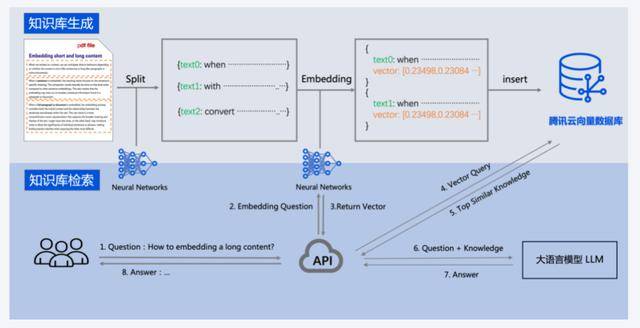
除了产品之外,腾讯云提供了全面AI化解决方案,覆盖接入层、计算层、存储层,使用户在使用向量数据库的全生命周期,都能应用到AI能力。有数据显示,企业原先接入一个大模型需要花1个月左右时间,使用腾讯云向量数据库后,3天时间即可完成,极大降低了企业的接入成本。
此外,腾讯庞大的业务集群及智能化应用,为腾讯云向量数据库提供了绝佳的练兵场。腾讯集团每日处理千亿次检索的向量引擎(OLAMA),让腾讯云向量数据库的基本功能和性能得到了更加充分地检验与优化,从而淬炼出了很多让人眼前一亮的新能力。
以腾讯视频的应用为例,视频库中的图片、音频、标题文本等内容使用腾讯云向量数据库,月均完成的检索和计算量高达200亿次,有效满足了版权保护、原创识别、相似性检索等场景需求。
风物长宜放眼量,AI技术还在快速变化之中,AI Native的腾讯云在这一市场领域的竞争力还会进一步扩大。
接下来,向量数据库卷什么?
不难看到,市面上并不缺少向量数据库产品,缺少的是商业模式。
据东北证券预测,到 2030 年,全球向量数据库市场规模有望达到 500 亿美元,国内向量数据库市场规模有望超过600亿人民币。想要吃到这块巨大的蛋糕,仅仅形成技术趋势是远远不够的,成熟的产品化才能说服用户、兑现商业价值。

目前来看,以腾讯云为代表的云厂商有几重特殊优势,或许会让向量数据库加速走向商业成功:
1.多元化部署。垂直行业大模型,数据都是私有机密的,客户一般不愿意放到公有云上,腾讯云提供私有部署、分布式、混合云等多种方案,打消疑虑。背后需要混合多云的云基础设施。
2.一体化AI方案。向量数据库的火爆,本质是AI需求,而AI Native时代的数据工程,还有许多复杂问题尚待解决,腾讯云提供一体化的AI解决方案,从底层算力集群、Maas模型平台到全栈工具链,通过软硬件协同优化AI开发成本,是企业和开发者所期待的。
3.产业服务能力。AI技术革命方兴未艾,行业热情高涨,但大多处于尝试探索期,需要结合自身业务、AI应用、IT设施等多种因素试错并迭代,这个过程中,随叫随到、帮助客户及时解决问题的ToB服务能力,也是非常看重的。深耕产业互联网的腾讯云,确实是企业在这场AI技术革命中可靠的伙伴。
开放、全面、贴心,才能支持企业用好向量数据库、大模型等基础设施,弄潮AI。
被大模型“带飞”的向量数据库,才刚刚开始,将在腾讯云上长出商业成功的羽翼,飞向更广阔的天地。