系统有万亿条消息怎么存储?
我们如何设计一个能存储数万亿条信息的系统?
Discord 的消息存储演进给我们提供了真实案例参考。
下图显示了 Discord 消息存储的演变过程:MongoDB -> Cassandra -> ScyllaDB
 图片
图片
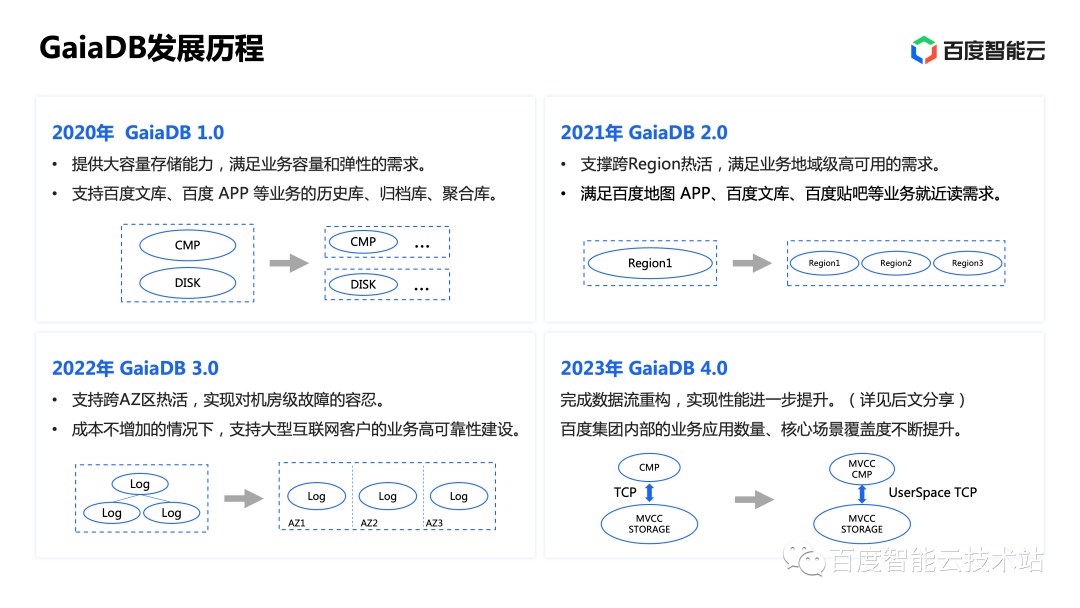
第一阶段
2015 年,Discord 的第一个版本建立在单个 MongoDB 之上。2015 年 11 月左右,MongoDB 存储了 1 亿条消息,其内存无法再容纳数据和索引。延迟变得不可预测。消息存储需要转移到另一个数据库。这时 Cassandra 被选中。
第二阶段
2017 年,Discord 拥有 12 个 Cassandra 节点,存储了数十亿条消息。
2022 年初,Discord 拥有 177 个 Cassandra 节点,存储了数万亿条消息。此时,延迟再次变得难以预测,维护的成本也变得过于昂贵。
造成这一问题有几个原因:
- Cassandra 使用 LSM 树作为内部数据结构。读取比写入更昂贵。在一台拥有数百名用户的服务器上,可能会有很多并发读取,从而导致热点问题。
- 维护集群(如压缩 SSTables)会影响性能。
- 垃圾回收会导致明显的延迟
第三阶段
这时,Discord 重新设计了消息存储的架构:
- 采用集中式的数据服务,其使用单体 API来访问,并用 Rust 重写。
- 采用基于 ScyllaDB 的存储。ScyllaDB 是用 C++ 编写的 Cassandra 兼容数据库。
新架构的优势在于:
- 用 C++ 而不是 JAVA 编写,消除了垃圾回收暂停的干扰。
- 按核分片模型(Shard-per-Core model)提供更好的负载隔离,防止热分区在节点间产生级联延迟。
- 优化了反向查询性能,以满足 Discord 的需求。
- 节点减少到 72 个,同时将每个节点的磁盘空间增加到 9 TB。
为了进一步保护 ScyllaDB,Discord 针对数据服务还做了以下优化:
- 在 Rust 中构建中间数据服务,限制并发流量峰值。
- 数据服务位于应用程序接口和数据库之间,可聚合请求。
- 即使多个用户请求相同的数据,也只需查询一次数据库。
- Rust 提供了快速、安全的并发功能,是这种工作负载的理想选择。
优化后的系统性能大大提高:
- ScyllaDB 的 p99 读取延迟为 15 毫秒,而 Cassandra 为 40-125 毫秒。
- ScyllaDB 的 p99 的写延迟为 5 毫秒,而 Cassandra 为 5-70 毫秒。
该系统可轻松应对世界杯流量高峰。
本文参考 Discord blog。