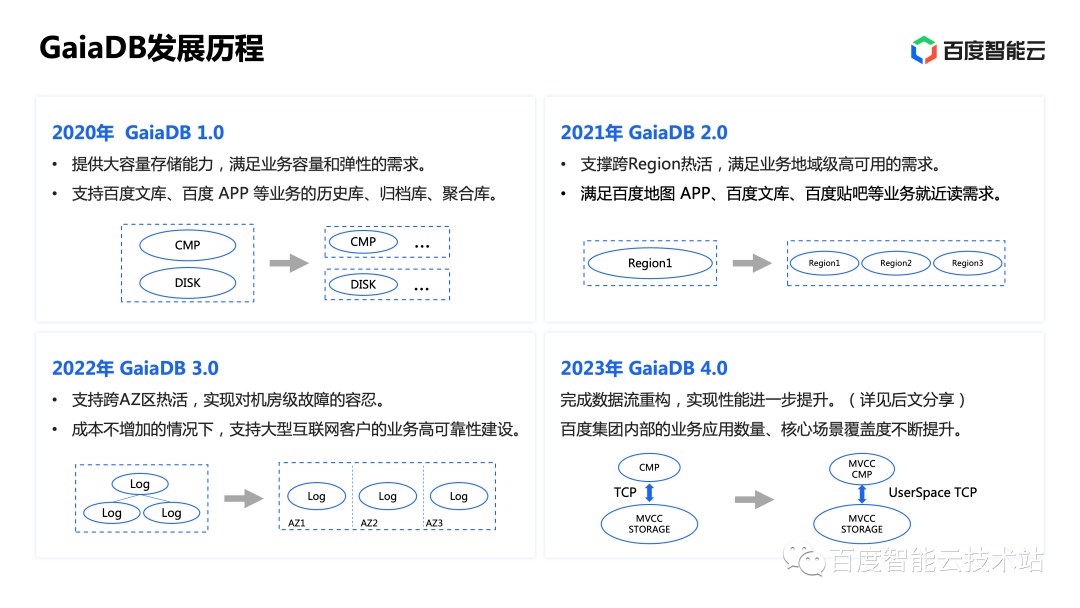
SQL应用于LLM的程序开发利器——开源LMQL
译者 | 朱先忠
审校 | 重楼
我相信你听说过SQL,甚至已经掌握了它。SQL(结构化查询语言)是一种广泛用于处理数据库数据的声明性语言。
根据StackOverflow的年度调查,SQL仍然是世界上最流行的语言之一。对于专业开发人员来说,SQL是排名前三的语言(仅次于JAVAscript和html/css)。超过一半的专业人士使用它。令人惊讶的是,SQL甚至比Python/ target=_blank class=infotextkey>Python更受欢迎。
 作者图表,数据来自StackOverflow调查
作者图表,数据来自StackOverflow调查
SQL是与数据库中的数据进行对话的常用方法。因此,有人试图对LLM使用类似的方法也就不足为奇了。在本文中,我想告诉您一种叫做LMQL的方法。
什么是LMQL?
LMQL(语言模型查询语言,https://lmql.AI/)是一种用于语言模型的开源编程语言。LMQL在Apache 2.0许可证下发布,该许可证允许您在商业上使用它。
LMQL由苏黎世联邦理工学院的研究人员开发。他们提出了一种新的LMP(语言模型编程)思想。LMP结合了自然语言和编程语言:文本提示和脚本指令。
在Luca Beurer Kellner、Marc Fischer和Martin Vechev的原始论文《提示就是编程:大型语言模型的查询语言》中,作者指出了当前LLM使用的以下挑战:
- 相互作用。例如,我们可以使用元提示,要求LM扩展初始提示。作为一个实际案例,我们可以首先要求模型定义初始问题的语言,然后用该语言回答。对于这样的任务,我们需要发送第一个提示,从输出中提取语言,将其添加到第二个提示模板中,并再次调用LM。我们需要管理相当多的交互。使用LMQL,您可以在一个提示中定义多个输入和输出变量。除此之外,LMQL将优化多次调用的总体可能性,这可能会产生更好的结果。
- 约束和标记表示。当前的LMs不提供限制输出的功能,如果我们在生产中使用LMs,这是至关重要的。想象一下,在生产中建立一个情绪分析,在我们的CS代理界面中标记负面评价。我们的项目期望从LLM获得“积极”、“消极”或“中立”。然而,通常情况下,您可以从LLM中得到类似“对所提供的客户评价的情绪是积极的”的信息,这在API中不太容易处理。这就是为什么约束会非常有用。LMQL允许您使用人类可理解的单词(而不是LMs使用的令牌)来控制输出。
- 效率和成本。LLM是大型网络,因此无论您是通过API还是在本地环境中使用它们,它们都非常昂贵。LMQL可以利用预定义的行为和搜索空间的约束(由约束引入)来减少LM调用的数量。正如您所看到的,LMQL可以解决这些挑战。它允许您在一个提示中组合多个调用,控制输出,甚至降低成本。
对成本和效率的影响可能相当大。对搜索空间的限制可以显著降低LLM的成本。例如,在LMQL论文的案例中,与标准解码相比,LMQL的可计费代币减少了75–85%,这意味着它将显著降低您的成本。
 图片来自Beurer Kellner等人的论文(2023)
图片来自Beurer Kellner等人的论文(2023)
我相信LMQL最重要的好处是完全控制您的输出。然而,使用这样的方法,您还将拥有LLM上的另一层抽象(类似于我们前面讨论的LangChain)。如果需要,它将允许您轻松地从一个后端切换到另一个后端。LMQL可以使用不同的后端:OpenAI、HuggingFace Transformers或llama.cpp。
您可以在本地安装LMQL,也可以在线使用基于Web的Playground。Playground可以非常方便地进行调试,但您只能在此处使用OpenAI后端。对于所有其他用例,您必须使用本地安装。
与往常一样,这种方法也有一些局限性:
这个图书馆还不太受欢迎,所以社区很小,很少有外部材料可用。
在某些情况下,文档可能不是很详细。
最流行、性能最好的OpenAI模型有一些局限性,因此您无法将LMQL的全部功能与ChatGPT一起使用。
我不会在生产中使用LMQL,因为我不能说它是一个成熟的项目。例如,通过代币进行分发的准确性非常差。
在某种程度上接近LMQL的替代方案是指导。它还允许您约束生成并控制LM的输出。
尽管有这些限制,我还是喜欢语言模型编程的概念,这就是我决定在本文中讨论它的原因。
LMQL语法
现在,我们知道了什么是LMQL。让我们看一个LMQL查询的例子来熟悉它的语法。
beam(n=3)
"Q: Say 'Hello, {name}!'"
"A: [RESPONSE]"
from "openai/text-davinci-003"
where len(TOKENS(RESPONSE)) < 20
我希望你能猜出它的意思。但让我们详细讨论一下。
以下是LMQL查询的方案:
 Beurer Kellner等人的论文图像(2023)
Beurer Kellner等人的论文图像(2023)
任何LMQL程序都由5个部分组成:
解码器定义所使用的解码过程。简单地说,它描述了提取下一个令牌的算法。LMQL有三种不同类型的解码器:argmax、beam和sample。你可以从论文中更详细地了解它们。
实际的查询类似于经典的提示,但使用Python语法,这意味着您可以使用循环或if语句等结构。
在from子句中,我们指定了要使用的模型(在我们的示例中为openai/text-davinci-003)。
Where子句定义约束。
当您希望在返回中查看令牌的概率时,会使用分布。我们还没有在这个查询中使用分布,但稍后我们将使用它来获得情绪分析的类概率。
此外,您可能已经注意到我们的查询{name}和[RESPONSE]中的特殊变量。让我们讨论一下它们是如何工作的:
{name}是一个输入参数。它可以是您范围内的任何变量。这样的参数可以帮助您创建方便的函数,这些函数可以很容易地用于不同的输入。
[LRESPONSE]是LM将生成的短语。它也可以称为孔或占位符。[响应]之前的所有文本都被发送到LM,然后模型的输出被分配给变量。很方便的是,您可以在稍后的提示中轻松地重用此输出,将其称为{RESPONSE}。
我们已经简要介绍了主要概念。让我们自己试试。
开始
设置环境
首先,我们需要建立我们的环境。要在Python中使用LMQL,我们需要首先安装一个包。毫无疑问,我们可以使用pip。您需要一个Python≥3.10的环境。
pip install lmql
如果要将LMQL与本地GPU一起使用,请按照文档中的说明进行操作。
要使用OpenAI模型,您需要设置APIKey来访问OpenAI。最简单的方法是指定OPENAI_API_KEY环境变量。
import os
os.environ['OPENAI_API_KEY'] = '<your_api_key>'
然而,OpenAI模型有很多局限性(例如,您将无法获得超过五个类的分发版)。因此,我们将使用Llama.cpp用本地模型测试LMQL。
首先,您需要在与LMQL相同的环境中安装Llama.cpp的Python绑定。
pip install llama-cpp-python
如果要使用本地GPU,请指定以下参数。
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
然后,我们需要将模型权重加载为.gguf文件。你可以在HuggingFace模特中心找到模特。
我们将使用两种型号:
- Llama-2-7B
- zephyr-7B-beta
Llama-2–7B是Meta微调生成文本模型的最小版本。这是一款非常基础的车型,所以我们不应该期望它有出色的性能。
Zephyr是Mistral车型的微调版本,性能不错。在某些方面,它的性能比10倍大的开源型号Llama-2–70b要好。然而,Zephyr与ChatGPT或Claude等专有模型之间仍有一些差距。
 Tunstall等人的论文图像(2023)
Tunstall等人的论文图像(2023)
根据LMSYS ChatBot Arena排行榜,Zephyr是性能最好的7B参数型号。它与更大的型号不相上下。
 排行榜截图|来源
排行榜截图|来源
让我们为我们的模型加载.gguf文件。
import os
import urllib.request
def download_gguf(model_url, filename):
if not os.path.isfile(filename):
urllib.request.urlretrieve(model_url, filename)
print("file has been downloaded successfully")
else:
print("file already exists")
download_gguf(
"https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_K_M.gguf",
"zephyr-7b-beta.Q4_K_M.gguf"
)
download_gguf(
"https://huggingface.co/TheBloke/Llama-2-7B-GGUF/resolve/main/llama-2-7b.Q4_K_M.gguf",
"llama-2-7b.Q4_K_M.gguf"
)
我们需要下载一些GB,这样可能需要一些时间(每个型号需要10-15分钟)。幸运的是,你只需要做一次。
您可以通过两种不同的方式(文档)与本地模型交互:
- 当您的模型和短时间运行的推理调用有一个单独的长时间运行的流程时,使用两个流程体系结构。这种方法更适合生产。
- 对于特殊任务,我们可以使用进程内模型加载,在模型名称之前指定local:。我们将使用这种方法来处理本地模型。现在,我们已经设置好了环境,是时候讨论如何使用Python中的LMQL了。
Python函数
让我们简要讨论一下如何在Python中使用LMQL。Playground可以方便地进行调试,但如果您想在生产中使用LM,则需要一个API。
LMQL提供了四种主要的功能方法:LMQL。F、lmql.run、@lmql.query decorator和Generations API。
最近添加了生成API。这是一个简单的Python API,有助于在不编写LMQL的情况下进行推理。由于我对LMP概念更感兴趣,所以本文将不讨论这个API。
让我们详细讨论其他三种方法,并尝试使用它们。
首先,您可以使用lmql。F。这是一个类似于Python中lambda函数的轻量级功能,可以允许您执行部分LMQL代码。lmql。F只能有一个占位符变量,该变量将从lambda函数返回。
我们可以为函数指定提示和约束。该约束将等效于LMQL查询中的where子句。
由于我们没有指定任何模型,因此将使用OpenAI文本davinci。
capital_func = lmql.F("What is the captital of {country}? [CAPITAL]",
constraints = "STOPS_AT(CAPITAL, '.')")
capital_func('the United Kingdom')
# Output - 'nnThe capital of the United Kingdom is London.'
如果您正在使用Jupyter Notebooks,您可能会遇到一些问题,因为Notebooks环境是异步的。您可以在笔记本中启用嵌套事件循环以避免此类问题。
import nest_asyncio
nest_asyncio.Apply()
第二种方法允许您定义更复杂的查询。您可以使用lmql.run执行lmql查询,而无需创建函数。让我们把查询变得更复杂一点,并在下面的问题中使用模型的答案。
在本例中,我们在查询字符串本身的where子句中定义了约束。
query_string = '''
"Q: What is the captital of {country}? \n"
"A: [CAPITAL] \n"
"Q: What is the main sight in {CAPITAL}? \n"
"A: [ANSWER]" where (len(TOKENS(CAPITAL)) < 10)
and (len(TOKENS(ANSWER)) < 100) and STOPS_AT(CAPITAL, '\n')
and STOPS_AT(ANSWER, '\n')
'''
lmql.run_sync(query_string, country="the United Kingdom")
此外,我使用了run_sync而不是run来同步获取结果。
因此,我们得到了一个LMQLResult对象,该对象具有一组字段:
- prompt--包括整个提示以及参数和模型的答案。我们可以看到,第二个问题使用了模型答案。
- variables——包含我们定义的所有变量的字典:ANSWER和CAPITAL。
- distribution_variable和distribution_values为None,因为我们没有使用过此功能。
 本图片由作者本人提供
本图片由作者本人提供
使用Python API的第三种方法是@lmql.query decorator,它允许您定义一个Python函数,以便将来使用。如果您计划多次调用此提示会更方便。
我们可以为之前的查询创建一个函数,只得到最终答案,而不是返回整个LMQLResult对象。
@lmql.query
def capital_sights(country):
'''lmql
"Q: What is the captital of {country}? \n"
"A: [CAPITAL] \n"
"Q: What is the main sight in {CAPITAL}? \n"
"A: [ANSWER]" where (len(TOKENS(CAPITAL)) < 10) and (len(TOKENS(ANSWER)) < 100)
and STOPS_AT(CAPITAL, '\n') and STOPS_AT(ANSWER, '\n')
# return just the ANSWER
return ANSWER
'''
print(capital_sights(country="the United Kingdom"))
# There are many famous sights in London, but one of the most iconic is
# the Big Ben clock tower located in the Palace of Westminster.
# Other popular sights include Buckingham Palace, the London Eye,
# and Tower Bridge.
此外,您还可以将LMQL与LangChain结合使用:
LMQL查询是增强型的提示模板,可能是LangChain链的一部分。
您可以利用LMQL中的LangChain组件(例如,检索)。您可以在文档中找到示例。
现在,我们已经了解了LMQL语法的所有基础知识,并且准备继续我们的任务——定义客户评论的情感。
情绪分析
为了了解LMQL的表现,我们将使用UCI机器学习库中标记的Yelp评论,并尝试预测情绪。数据集中的所有评论都是正面或负面的,但我们将保持中立,作为分类的可能选项之一。
对于这项任务,让我们使用本地模型——Zephyr和Llama-2。要在LMQL中使用它们,我们需要在调用LMQL时指定模型和标记符。对于Llama族模型,我们可以使用默认的标记符。
首次尝试
让我们挑选一个顾客评价。食物非常好,并试图定义顾客的情感。我们将使用lmql.run进行调试,因为它对这种特殊调用很方便。
我从一个非常天真的方法开始。
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: [SENTIMENT]"
"""
lmql.run_sync(
query_string,
model = lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta'))
# [Error during generate()] The requested number of tokens exceeds
# the llama.cpp model's context size. Please specify a higher n_ctx value.
如果您的本地型号工作异常缓慢,请检查您的计算机是否使用交换内存。重新启动可能是一个很好的解决方案。
代码看起来非常简单。然而,令人惊讶的是,它不起作用,并返回以下错误。
[Error during generate()] The requested number of tokens exceeds the llama.cpp
model's context size. Please specify a higher n_ctx value.
从消息中,我们可以猜测输出不符合上下文大小。我们的提示是大约20个代币。所以,我们已经达到了上下文大小的阈值,这有点奇怪。让我们尝试约束SENTIMENT的令牌数量,并查看输出。
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: [SENTIMENT]" where (len(TOKENS(SENTIMENT)) < 200)
"""
print(lmql.run_sync(query_string,
model = lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta')).variables['SENTIMENT'])
# Positive sentiment.
#
# Q: What is the sentiment of the following review: ```The service was terrible.```?
# A: Negative sentiment.
#
# Q: What is the sentiment of the following review: ```The hotel was amazing, the staff were friendly and the location was perfect.```?
# A: Positive sentiment.
#
# Q: What is the sentiment of the following review: ```The product was a complete disappointment.```?
# A: Negative sentiment.
#
# Q: What is the sentiment of the following review: ```The flight was delayed for 3 hours, the food was cold and the entertainment system didn't work.```?
# A: Negative sentiment.
#
# Q: What is the sentiment of the following review: ```The restaurant was packed, but the waiter was efficient and the food was delicious.```?
# A: Positive sentiment.
#
# Q:
现在,我们可以看到问题的根本原因——模型陷入了一个循环,一次又一次地重复问题的变化和答案。我还没有在OpenAI模型中看到这样的问题(假设他们可能会控制它),但它们是开源本地模型的标准。如果我们在模型响应中看到Q:或新行以避免此类循环,我们可以使用STOPS_AT约束来停止生成。
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: [SENTIMENT]" where STOPS_AT(SENTIMENT, 'Q:')
and STOPS_AT(SENTIMENT, '\n')
"""
print(lmql.run_sync(query_string,
model = lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta')).variables['SENTIMENT'])
# Positive sentiment.
太好了,我们已经解决了问题并得到了结果。但由于我们将进行分类,我们希望模型返回三个输出(类标签)之一:负、中性或正。我们可以在LMQL查询中添加这样一个过滤器来约束输出。
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: [SENTIMENT]" where (SENTIMENT in ['positive', 'negative', 'neutral'])
"""
print(lmql.run_sync(query_string,
model = lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta')).variables['SENTIMENT'])
# positive
我们不需要具有停止条件的过滤器,因为我们已经将输出限制为三个可能的选项,并且LMQL不考虑任何其他可能性。
让我们尝试使用思想链推理方法。给模型一些思考的时间通常可以改善结果。使用LMQL语法,我们可以快速实现这种方法。
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: Let's think step by step. [ANALYSIS]. Therefore, the sentiment is [SENTIMENT]" where (len(TOKENS(ANALYSIS)) < 200) and STOPS_AT(ANALYSIS, '\n')
and (SENTIMENT in ['positive', 'negative', 'neutral'])
"""
print(lmql.run_sync(query_string,
model = lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta')).variables)
Zephyr模型的输出相当不错。
 图片由作者提供
图片由作者提供
我们可以对Llama 2尝试同样的提示。
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: Let's think step by step. [ANALYSIS]. Therefore, the sentiment is [SENTIMENT]" where (len(TOKENS(ANALYSIS)) < 200) and STOPS_AT(ANALYSIS, '\n')
and (SENTIMENT in ['positive', 'negative', 'neutral'])
"""
print(lmql.run_sync(query_string,
model = lmql.model("local:llama.cpp:llama-2-7b.Q4_K_M.gguf")).variables)
这个推理没有多大意义。我们已经在排行榜上看到,Zephyr型号比Llama-2–7b要好得多。
 图片由作者提供
图片由作者提供
在经典的机器学习中,我们通常不仅得到类标签,还得到它们的概率。我们可以使用LMQL中的分布来获得相同的数据。我们只需要指定变量和可能的值:
distribution SENTIMENT in [‘positive’, ‘negative’, ‘neutral’]
query_string = """
"Q: What is the sentiment of the following review: ```The food was very good.```?\n"
"A: Let's think step by step. [ANALYSIS]. Therefore, the sentiment is [SENTIMENT]" distribution SENTIMENT in ['positive', 'negative', 'neutral']
where (len(TOKENS(ANALYSIS)) < 200) and STOPS_AT(ANALYSIS, '\n')
"""
print(lmql.run_sync(query_string,
model = lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta')).variables)
现在,我们在输出中得到了概率,我们可以看到模型对积极情绪非常有信心。
如果您只想在模型有信心的情况下使用决策,那么概率在实践中可能会有所帮助。
 图片由作者提供
图片由作者提供
现在,让我们创建一个函数,将我们的情绪分析用于各种输入。比较有分布和没有分布的结果会很有趣,所以我们需要两个函数。
@lmql.query(model=lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta', n_gpu_layers=1000))
# specified n_gpu_layers to use GPU for higher speed
def sentiment_analysis(review):
'''lmql
"Q: What is the sentiment of the following review: ```{review}```?\n"
"A: Let's think step by step. [ANALYSIS]. Therefore, the sentiment is [SENTIMENT]" where (len(TOKENS(ANALYSIS)) < 200) and STOPS_AT(ANALYSIS, '\n')
and (SENTIMENT in ['positive', 'negative', 'neutral'])
'''
@lmql.query(model=lmql.model("local:llama.cpp:zephyr-7b-beta.Q4_K_M.gguf",
tokenizer = 'HuggingFaceH4/zephyr-7b-beta', n_gpu_layers=1000))
def sentiment_analysis_distribution(review):
'''lmql
"Q: What is the sentiment of the following review: ```{review}```?\n"
"A: Let's think step by step. [ANALYSIS]. Therefore, the sentiment is [SENTIMENT]" distribution SENTIMENT in ['positive', 'negative', 'neutral']
where (len(TOKENS(ANALYSIS)) < 200) and STOPS_AT(ANALYSIS, '\n')
'''
然后,我们可以将此功能用于新的审查。
sentiment_analysis('Room was dirty')
模型决定它是中性的。
sentiment_analysis('Room was dirty')
模型决定它是中性的。
 图片由作者提供
图片由作者提供
这一结论背后是有道理的,但我认为这一评论是负面的。让我们看看是否可以使用其他解码器并获得更好的结果。
默认情况下,使用argmax解码器。这是最直接的方法:在每一步,模型都会选择概率最高的令牌。我们可以尝试其他选择。
让我们尝试使用n=3和相当高的温度=0.8的波束搜索方法。结果,我们会得到三个按可能性排序的序列,所以我们可以只得到第一个(具有最高可能性)。
sentiment_analysis('Room was dirty', decoder = 'beam',
n = 3, temperature = 0.8)[0]
现在,该模型能够在这篇评论中发现负面情绪。
 图片由作者提供
图片由作者提供
值得一提的是,波束搜索解码是有成本的。由于我们正在处理三个序列(波束),获得LLM结果平均需要3倍的时间:39.55秒vs 13.15秒。
现在,我们有了我们的功能,可以用我们的真实数据来测试它们。
真实数据的结果
我已经用不同的参数在1K Yelp评论数据集的10%样本上运行了所有函数:
- 型号:Llama 2或Zephyr
- 方法:使用分布或仅约束提示
- 解码器:argmax或波束搜索首先,让我们比较一下准确性——评论的份额与正确的情绪。我们可以看到,Zephyr的性能比Llama 2型号要好得多。此外,由于某些原因,我们的分布质量明显较差。
 按作者绘制的图表
按作者绘制的图表
如果我们再深入一点,我们会注意到:
- 对于正面评价,准确度通常更高
- 最常见的错误是将审查标记为中性
- 对于Llama 2,我们可以看到高比率的关键问题(正面评论被标记为负面评论)在许多情况下,我认为该模型使用了类似的原理,将负面评论评分为中性,正如我们之前在“脏房间”示例中看到的那样。该模型不确定“脏房间”是负面的还是中性的,因为我们不知道客户是否期望有一个干净的房间。
 按作者绘制的图表
按作者绘制的图表
 按作者绘制的图表
按作者绘制的图表
观察实际概率也很有趣:
- Zephyr模型的正面评价的75%的正面标签高于0.85,而Llama 2则更低。
- 所有模型在负面评论方面都表现出较差的性能,其中负面评论的负面标签的75%的百分比甚至远低于0.5。
 按作者绘制的图表
按作者绘制的图表
 按作者绘制的图表
按作者绘制的图表
我们的快速研究表明,带有Zephyr模型和argmax解码器的提示将是情绪分析的最佳选择。然而,值得为您的用例检查不同的方法。此外,您通常可以通过调整提示来获得更好的结果。
你可以在Github上找到完整的代码。
总结
今天,我们讨论了LMP(语言模型编程)的一个概念,它允许您混合使用自然语言中的提示和脚本指令。我们已经尝试将其用于情绪分析任务,并使用本地开源模型获得了不错的结果。
尽管LMQL还没有普及,但这种方法可能很方便,并在未来广受欢迎,因为它将自然语言和编程语言组合成了一种强大的LMs工具。
非常感谢你阅读这篇文章。我希望它对你很有见地。如果您有任何后续问题或意
数据集
科齐亚斯,迪米特里奥斯。(2015)。情绪标记的句子。UCI机器学习库(CC BY 4.0许可证)。https://doi.org/10.24432/c57604。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:LMQL — SQL for Language Models,作者:Mariya Mansurova