在这一节,我们将简要介绍不同类型的机器学习,并重点关注它们的主要特点和差异。在接下来的部分中,我们将讨论非正式定义,以及正式定义。如果你不熟悉讨论中涉及的数学概念,则可以跳过详细信息。但是,研究所有未知的理论因素是非常明智的,因为它们对于理解后面章节的概念至关重要。
1.3.1 有监督学习算法
在有监督的场景中,模型的任务是查找样本的正确标签,假设在训练集时标记正确,并有可能将估计值与正确值进行比较。有监督这个术语源自外部教学代理的想法,其在每次预测之后提供精确和即时的反馈。模型可以使用此类反馈作为误差的度量,从而减少错误所需的更正。
更正式地说,如果我们假设一个数据生成过程,数据集

的获取如下:

其中
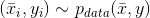
且


如1.2节所述,所有样本必须是从数据生成过程中统一采样的独立且同分布(Independent and Identically Distributed,IID)的值。特别地,所有类别必须代表实际分布(例如,如果p( y = 0) = 0.4且p( y = 1) = 0.6,则该比例应为40%或60%)。但是,为了避免偏差,当类之间的差异不是很大时,合理的选择是完全统一的采样,并且对于y = 1,2,…,M是具有相同数量的代表。
通用分类器

可以通过两种方式建模。
- 输出预测类的参数化函数。
- 参数化概率分布,输出每个输入样本的类概率。
对于第一种情况,我们有:
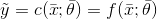
且

是一个错误的测量结果
考虑整个数据集X,可以计算全局成本函数L:
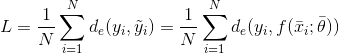
由于L仅取决于参数向量(xi和yi是常数),因此通用算法必须找到最小化成本函数的最佳参数向量。例如在回归问题(标签是连续的)中,误差度量可以是实际值和预测值之间的平方误差:

这种成本函数可以用不同的方式优化(特定算法特有的),但一个非常常见的策略(尤其在深度学习中)是采用随机梯度下降(Stochastic Gradient Descent,SGD)算法。它由以下两个步骤的迭代组成。
- 使用少量样本xi∈X计算梯度∇L(相对于参数向量)。
- 更新权重并在梯度的相反方向上移动参数(记住渐变始终指向最大值)。
对于第二种情况,当分类器是基于概率分布时,它应该表示为参数化的条件概率分布:
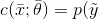
换句话说,分类器现在将输出给定输入向量y的概率。现在的目标是找到最佳参数集,它将获得:
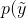
在前面的公式中,我们将pdata表示为条件分布。我们可以使用概率距离度量来进行优化,例如Kullback-Leibler散度DKL(DKL始终为非负,且仅当两个分布相同时,DKL=0):

通过一些简单的操作,我们得到:

因此,生成的成本函数对应于p和pdata之间交叉熵的差值达到定值(数据生成过程的熵)。训练策略现在是基于使用独热编码表示的标签(例如如果有两个标签0→(0,1)和1→(1,0),那么所有元素的总和必须始终等于1)并使用内在概率(例如在逻辑回归中)或softmax滤波器(其将M值转换为概率分布)输出。
在这两种情况下,很明显隐藏教师模型的存在提供了一致的误差测量,它允许模型相应地校正参数。特别地,第二种方法对达到我们的目的非常有用,因此如果你还不太清楚,我建议你进一步研究它(主要定义也可以在machine Learning Algorithms, Second Edition一书中找到)。
我们现在讨论一个非常基本的监督学习示例,它是一个线性回归模型,可用于预测简单时间序列的演变。
有监督的hello world!
在此示例中,我们要展示如何使用二维数据执行简单的线性回归。特别地,假设我们有一个包含100个样本的自定义数据集,如下所示:
import numpy as np
import pandas as pd
T = np.expand_dims(np.linspace(0.0, 10.0, num=100), axis=1)
X = (T * np.random.uniform(1.0, 1.5, size=(100, 1))) +
np.random.normal(0.0, 3.5, size=(100, 1))
df = pd.DataFrame(np.concatenate([T, X], axis=1), columns=['t', 'x'])
我们还创建了一个pandas的DataFrame,因为使用seaborn库创建绘图更容易。在本书中,通常省略了图表的代码(使用Matplotlib或seaborn),但它始终存在于库中。
我们希望用一种综合的方式表示数据集,如下所示:
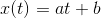
此任务可以使用线性回归算法执行,如下所示:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(T, X)
print('x(t) = {0:.3f}t + {1:.3f}'.format(lr.coef_[0][0], lr.intercept_[0]))
最后一个命令的输出如下:
X(t) = 1.169t + 0.628
我们还可以将数据集与回归线一起绘制,获得视觉确认,如图1-4所示。
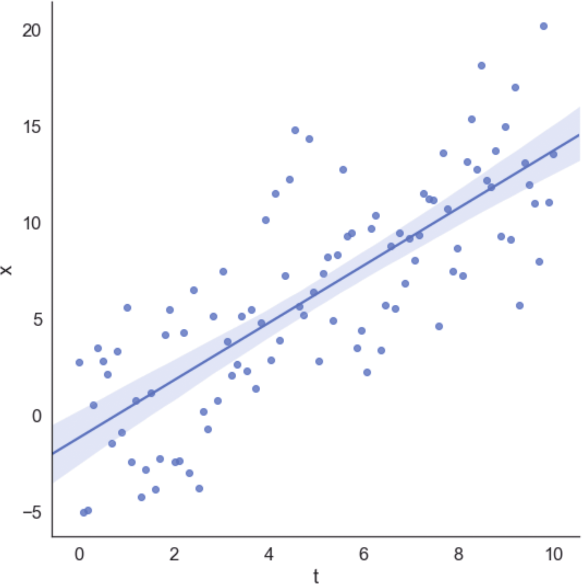
图1-4 数据集与回归线
在该示例中,回归算法最小化了平方误差成本函数,试图减小预测值与实际值之间的差异。由于对称分布,所以高斯(空均值)噪声对斜率的影响最小。
1.3.2 无监督学习算法
很容易想象在无监督的场景中,没有隐藏的老师,因此主要目标与最小化基本事实的预测误差无关。实际上,在这种背景下,相同的基本事实的概念具有略微不同的含义。事实上,在使用分类器时,我们希望训练样本出现一个零错误(这意味着除了真正类之外的其他类永远不会被接受为正确类)。
相反,在无监督问题中,我们希望模型在没有任何正式指示的情况下学习一些信息。这种情况意味着唯一可以学习的因素是样本本身包含的。因此,无监督算法通常旨在发现样本之间的相似性和模式,或者在给定一组从中得出的向量的情况下,再现输入分布。现在让我们分析一些最常见的无监督模型类别。
1.聚类分析
聚类分析(通常称为聚类)是我们想要找出大量样本中共同特征的示例。在这种情况下,我们总是假设存在数据生成过程
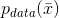
,并且将数据集X定义为:

其中

且
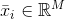
聚类算法基于一个隐含假设,即样本可以根据其相似性进行分组。特别是当给定两个向量,相似性函数被定义为度量函数的倒数或相反数。例如,如果我们在欧几里得空间中,则有:

且
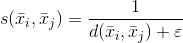
在前面的公式中,引入了常数ε以避免除以零。很明显,d(a,c) < d(a,b) ⇒ s(a,c) > s(a,b)。因此,给定每个聚类

的代表,我们可以根据规则创建一组分配的向量:

换句话说,聚类包含代表距离同所有其他代表相比最小的所有元素。这意味着聚类包含同所有代表相比与代表的相似性最大的样本。此外,在分配之后,样本获得与同一聚类的其他成员共享其功能的权利。
事实上,聚类分析最重要的应用之一是尝试提高被认为相似样本的同质性。例如推荐引擎可以基于用户向量的聚类(包含有关用户兴趣和购买产品的信息)来进行推荐。一旦定义了组,属于同一聚类的所有因素都被认为是相似的,因此我们被隐式授权共享差异。如果用户A购买了产品P并对其进行了积极评价,我们可以向没有购买产品的用户B推荐此商品,反之亦然。该过程看似随意,但是当因素的数量很大并且特征向量包含许多判别因素(例如评级)时,因素就变得非常有效了。
2.生成模型
另一种无监督方法是基于生成模型。这个概念与我们已经讨论的有监督算法的概念没有太大区别,但在这种情况下,数据生成过程不包含任何标签。因此,我们的目标是对参数化分布进行建模并优化参数,以便将候选分布与数据生成过程之间的距离最小化:
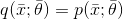
该过程通常基于Kullback-Leibler散度或其他类似度量:

在训练阶段结束时,我们假设L→0,所以p≈pdata。通过这种方式,我们不会将分析限制在可能样本的子集,而是限制在整个分布。使用生成模型,我们可以绘制与训练过程选择样本截然不同的新样本,但它们始终属于相同的分布。因此,它们(可能)总是可以接受的。
例如生成式对抗网络(Generative Adversarial Network,GAN)是一种特殊的深度学习模型,它能够学习图像集的分布,生成与训练样本几乎无法区分的新样本(从视觉语义的角度来看)。无监督学习是本书的主题,因此我们不会在此处进一步讨论GAN。所有这些概念将在第9章(用实际例子)进行深入讨论。
3.关联规则
我们正在考虑的最后一种无监督方法是基于关联规则的,它在数据挖掘领域非常重要。常见的情形是由一部分商品组成的商业交易集合,目标是找出商品之间最重要的关联(例如购买Pi和Pj的概率为70%)。特定算法可以有效地挖掘整个数据库,突出所有可以考虑到的战略和物流目的之间的关系。例如在线商店可以使用这种方法来促销那些经常与其他商品一起购买的商品。此外,预测方法允许通过建议所有很可能售罄的商品来简化供应流程,这要归功于其他项目的销售增加。
在这一点上,读者了解无监督学习的实际例子是有帮助的。不需要特别的先决条件,但你最好具备概率论的基本知识。
4.无监督的hello world!
由于本书完全致力于无监督算法的讲解,在此不将简单的聚类分析显示为hello world!示例,而是假设一个非常基本的生成模型。假设我们正在监控每小时到车站的列车数量,因为我们需要确定车站所需的管理员数量。特别地,要求每列列车至少有1名管理员,每当管理员数量不足时,我们将被罚款。
此外,在每小时开始时发送一个组更容易,而不是逐个控制管理员。由于问题非常简单,我们也知道泊松分布是一个好的分布,参数μ同样也是平均值。从理论上讲,我们知道这种分布可以在独立的主要假设下有效地模拟在固定时间范围内发生的事件的随机数。在一般情况下生成模型基于参数化分布(例如神经网络),并且不对其系列进行具体假设。仅在某些特定情况下(例如高斯混合),选择具有特定属性的分布是合理的,并且在不损失严谨性的情况下,我们可以将该示例视为此类方案之一。
泊松分布的概率质量函数为:

此分布描述了在预定义的间隔内观察k个事件的概率。在我们的例子中,间隔始终是1小时,我们希望观测10多趟列车,然后估计概率。我们如何才能获得μ的正确数值?
最常见的策略称为最大似然估计(Maximum Likelihood Estimation,MLE)。该策略通过收集一组观测值,然后找到μ的值,该值使分布生成所有点的概率最大化。
假设我们已经收集了 N 个观测值(每个观测值是一小时内到达的列车数量),则相对于所有样本的μ的似然度是在使用以下公式计算的概率分布下所有样本的联合概率μ(为简单起见,假设为IID):

当我们使用乘积和指数时,计算对数似然是一种常见的规则:
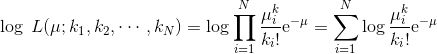
一旦计算出对数似然,我们就可以将μ的导数设置为0,以便找到最佳值。在这种情况下,我们省略了证明(直接获得)并直接得出μ的最大似然估计值:

很幸运的是最大似然估计值只是到达时间的平均值。这意味着,如果我们观察到N个平均值为μ的值,则有很大可能生成它们的泊松分布,其特征系数为μ。因此,从这种分布中抽取的任何其他样本将与观察到的数据集兼容。
我们现在可以从第一次模拟开始。假设我们在工作日的下午收集了25个观察结果,如下所示:
import numpy as np
obs = np.array([7, 11, 9, 9, 8, 11, 9, 9, 8, 7, 11, 8, 9, 9, 11, 7, 10, 9, 10, 9, 7, 8, 9, 10, 13])
mu = np.mean(obs)
print('mu = {}'.format(mu))
最后一个命令的输出如下:
mu = 9.12
因此,每小时平均到达9趟列车。初始分布的直方图如图1-5所示。
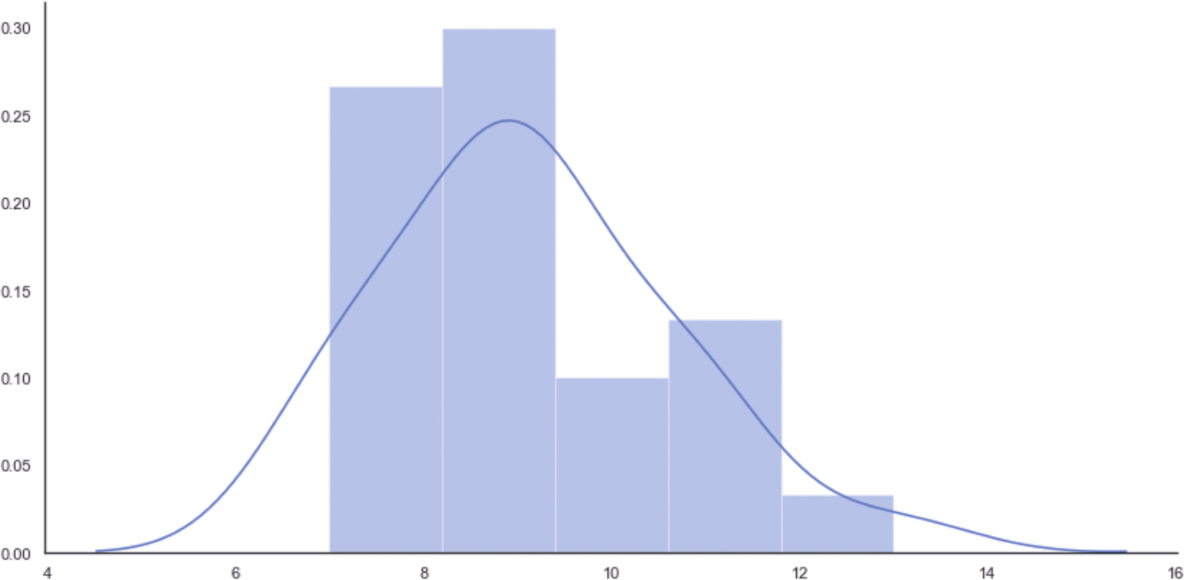
图1-5 初始分布的直方图
要计算请求的概率,我们需要使用累积分布函数(Cumulative Distribution Function,CDF),它在SciPy中实现(在scipy.stats包中)。特别地,由于我们感兴趣的是观察到的列车数量超过固定值的概率,因此有必要使用与1-CDF相对应的生存函数(Survival Function,SF),如下所示:
from scipy.stats import poisson
print('P(more than 8 trains) = {}'.format(poisson.sf(8, mu)))
print('P(more than 9 trains) = {}'.format(poisson.sf(9, mu)))
print('P(more than 10 trains) = {}'.format(poisson.sf(10, mu)))
print('P(more than 11 trains) = {}'.format(poisson.sf(11, mu)))
上述代码段的输出如下所示:
P(more than 8 trains) = 0.5600494497386543
P(more than 9 trains) = 0.42839824517059516
P(more than 10 trains) = 0.30833234660452563
P(more than 11 trains) = 0.20878680161156604
正如预期的那样,能观测10多趟列车的概率很低(30%),派10名管理员似乎不合理。但是,由于我们的模型是自适应的,我们可以继续收集观测值(例如在清晨),如下所示:
new_obs = np.array([13, 14, 11, 10, 11, 13, 13, 9, 11, 14, 12, 11, 12,14,
8, 13, 10, 14, 12, 13, 10, 9, 14, 13, 11, 14, 13, 14])
obs = np.concatenate([obs, new_obs])
mu = np.mean(obs)
print('mu = {}'.format(mu))
μ的新值如下所示:
mu = 10.641509433962264
现在平均每小时 11 趟列车。假设我们收集了足够的样本(考虑所有潜在的事故),我们可以重新估计概率,如下所示:
print(P(more than 8 trains) = {}'.format(poisson.sf(8, mu)))
print(P(more than 9 trains) = {}'.format(poisson.sf(9, mu)))
print(P(more than 10 trains) = {}'.format(poisson.sf(10, mu)))
print(P(more than 11 trains) = {}'.format(poisson.sf(11, mu)))
输出如下:
P(more than 8 trains) = 0.734624391080037
P(more than 9 trains) = 0.6193541369812121
P(more than 10 trains) = 0.49668918740243756
P(more than 11 trains) = 0.3780218948425254
使用新数据集观测超过9趟列车的概率约为62%(这证实了我们最初的选择),但现在观测超过10趟列车的概率约为50%。由于我们不想承担支付罚款的风险(这比管理员的成本高),因此最好派10名管理员。为了得到进一步的确认,我们决定从分布中抽取2000个值,如下所示:
syn = poisson.rvs(mu, size=2000)
相应的直方图如图1-6所示。
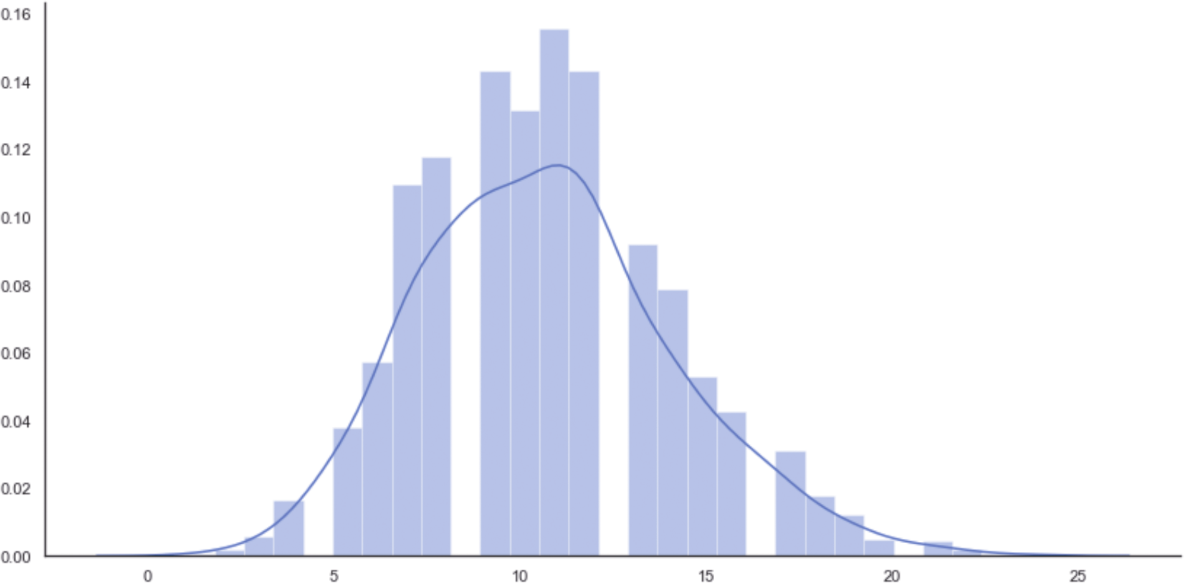
图1-6 从最终泊松分布中抽取2000个值的直方图
该图在10(表示10名管理员)之后(非常接近11时)达到峰值,然后从k=13开始快速衰减,这是使用有限数据集发现的(比较直方图的形状以进一步确认)。但是,在这种情况下,我们正在生成无法存在于观察集中的潜在样本。MLE保证了概率分布与数据一致,并且新样本将相应地进行加权。这个例子非常简单,其目的只是展示生成模型的动态性。
我们将在本书的后续章节中讨论许多更复杂的模型和示例。许多算法常见的一个重要技术在于不是选择预定义的分布(这意味着先验知识),而是选择灵活的参数模型(例如神经网络)来找出最优分布。只有基础随机过程存在较高的置信度时,优先选择预定义(如本例所示)才合理。在其他情况下,最好避免任何假设,只依赖数据,以便找到数据生成过程中的最适当的近似值。
1.3.3 半监督学习算法
半监督场景可以被视为标准监督场景,它利用了一些属于无监督学习技术的特征。事实上,当很容易获得大的未标记数据集,而标签成本又非常高时,就会出现一个非常普遍的问题。因此,只标记部分样本并将标签传播到所有未标记样本,这些样本与标记样本的距离就会低于预定义阈值。如果从单个数据生成过程中抽取数据集并且标记的样本均匀分布,则半监督算法可以实现与有监督算法相当的精度。在本书中,我们不讨论这些算法,但有必要简要介绍两个非常重要的模型。
- 标签传播。
- 半监督支持向量机。
第一个称为标签传播(Label Propagation),其目的是将一些样本的标签传播到较大的群体。我们可以通过图形来实现该目标,其中每个顶点表示样本并且每条边都使用距离函数进行加权。通过迭代,所有标记的样本将其标签值的一小部分发送给它们所有的近邻,并且重复该过程直到标签停止变化。该系统具有最终稳定点(即无法再演变的配置),算法可以通过有限的迭代次数轻松到达该点。
标签传播在某些样本可以根据相似性度量进行标记的情况下非常有用。例如在线商店可能拥有大量客户,但只有10%的人透露了自己的性别。如果特征向量足够丰富以表示男性和女性用户的常见行为,则可以使用标签传播算法来猜测未公开信息的客户性别。当然,请务必记住,所有分配都基于相似样本具有相同标签的假设。在许多情况下都是如此,但是当特征向量的复杂性增加时,也可能会产生误导。
第二个重要的半监督算法系列是基于标准支持向量机(Support Vector Machine,SVM)的,对包含未标记样本的数据集的扩展。在这种情况下,我们不想传播现有标签,而是传播分类标准。换句话说,我们希望使用标记数据集来训练分类器,并将分类规则扩展到未标记的样本。
与仅能评估未标记样本的标准过程相反,半监督SVM使用它们来校正分离超平面。假设始终基于相似性:如果A的标签为1,而未标记样本B的d(A,B)<ε(其中ε是预定义的阈值),则可以合理地假设B的标签也是1。通过这种方式,即使仅手动标记了一个子集,分类器也可以在整个数据集上实现高精度。与标签传播类似,这种类型的模型只有在数据集的结构不是非常复杂时,特别是当相似性假设成立时(不幸的是,在某些情况下,找到合适的距离度量非常困难,因此许多类似的样本确实不相似,反之亦然)才是可靠的。
1.3.4 强化学习算法
强化学习可以被视为有监督的学习场景,其中隐藏教师仅在模型的每个决策后提供近似反馈。更正式地说,强化学习的特点是代理和环境之间的持续互动。前者负责决策(行动),最终增加其回报,而后者则为每项行动提供反馈。反馈通常被视为奖励,其价值可以是积极的(行动已成功)或消极的(行动不能复用)。当代理分析环境(状态)的不同配置时,每个奖励必须被视为绑定到元组(行动,状态)。因此,我们的最终目标是找到一种方针(建议在每种状况下采取最佳行动的一种策略),使预期总回报最大化。
强化学习的一个非常经典的例子是学习如何玩游戏的代理。在一个事件中,代理会测试所有遇到状态中的操作并收集奖励。算法校正策略以减少非积极行为(即奖励为正的行为)的可能性,并增加在事件结束时可获得的预期总奖励。
强化学习有许多有趣的应用,这些应用并不仅限于游戏。例如推荐系统可以根据用户提供的二进制反馈(例如拇指向上或向下)来更正建议。强化学习和有监督学习之间的主要区别在于环境提供的信息。事实上,在有监督的场景中,更正通常与其成比例,而在强化学习中,必须分析一系列行动和未来的奖励。因此,更正通常基于预期奖励的估计,并且它们的影响受后续行动的价值影响。例如有监督模型没有内存,因此其更正是立竿见影的,而强化学习代理必须考虑一个事件的部分展开,以决定一个操作是否是负的。
强化学习是机器学习的一个有趣分支。遗憾的是,这个主题超出了本书的范围,因此我们不会详细讨论它(你可以在Hands-On Reinforcement Learning with Python和Mastering Machine Learning Algorithms中找到更多细节)。
本文摘自:《Python无监督学习》

本书需要你有机器学习和Python编程的基本知识。此外,为了充分理解书中所有的理论,还需要你了解大学阶段的概率论、微积分和线性代数等相关知识。但是,不熟悉这些知识的读者也可以跳过数学讨论,只关注实践方面的内容。在需要时,你可以参考相关论文和书籍,以便更深入地理解复杂的概念。
本书通过Python语言讲解无监督学习,全书内容包括10章,前面9章由浅入深地讲解了无监督学习的基础知识、聚类的基础知识、高级聚类、层次聚类、软聚类和高斯混合模型、异常检测、降维和分量分析、无监督神经网络模型、生成式对抗网络和自组织映射,第10章以问题解答的形式对前面9章涉及的问题给出了解决方案。























