基于协同矩阵分解的多模态数据的哈希方法

引用
Ding G, Guo Y, Zhou J. Collective matrix factorization hashing for multimodal data[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 2075-2082.
摘要
在计算机视觉和信息检索领域,基于哈希的最近邻搜索方法在有效和高效的大规模相似性搜索中备受瞩目。以多模态数据为中心,本文研究了学习哈希函数进行跨视角的相似性搜索的问题。我们提出了一种新型的哈希方法,称为协同矩阵分解的哈希(CMFH)。CMFH 通过协同矩阵分解与潜因子模型从一个实例的不同模态中学习统一的哈希码,不仅可以支持跨视图的搜索,而且可以通过合并多个视图的信息源,提高搜索精度。我们还证明了 CMFH 作为一种保留相似性的哈希学习方法,具有阈值。通过大量的实验,我们在三个不同的数据集上验证了 CMFH 相较于几种最先进的方法的显著优越性。
1 介绍
最近邻搜索在许多重要的应用中发挥着基础性的作用,如信息检索、数据挖掘和计算机视觉等领域。基于散列的最近邻搜索是将高维数据嵌入到紧凑的二进制码字中,因其近年来在海量数据中的巨大效率提升而引起了研究人员们的极大兴趣。其中,基于哈希的模型中最值得借鉴的是位置敏感哈希(LSH),其基本思想是将原始数据映射到汉明空间,同时保留它们的相似性。LSH 可以很有效地处理相似性搜索,因为在计算二进制码之间的汉明距离时,应用了位运算。在标准 LSH 的基础上, 也可以采用一些机器学习的方法来设计有效的紧凑哈希。
随着相似性搜索在不同视图中的应用,上述的单视图方法已趋向于多视图场景。最近, 一些跨视图哈希函数学习的核心问题是:如何处理来自不同概率分布的多模态数据。
一般来说,跨视角哈希方法可以分为两类:特定视图哈希方法和综合哈希方法。以特定视图的散列方法为实例的每个视图,首先会学习独立的散列码,然后将多个特定视图的二进制码进行串联,得到综合散列码。跨模态相似性搜索散列(CMSSH)是通过将不可知数据嵌入到一个共同的度量空间中来解决的。Kumar 等人将频谱哈希扩展到多视图文件中,并提出了跨视图哈希模型(CVH),该模型通过求解广义特征值问题来最小化对象的权重平均多视图的 L2 范式距离。共规化哈希(CRH),其目标函数意图是将数据投影到远离 0 的地方,以获得良好的泛化效果,同时,有效地保留模态间的相似性。媒介间哈希(IMH)引入媒介间一致性和媒介内一致性来发现一个共同的汉明,并利用线性回归与复合模型来学习特定视图的哈希函数。上述哈希方法主要用于不同视图间的相似性搜索。例如,将一张图片作为查询对象,搜索引擎可以返回一些文档,以准确描述细节。为了实现跨视图搜索,每个视图都需要存储独立的哈希码,增加了存储和搜索的成本。
综合哈希方法为每个实例学习统一的哈希码。多信息源复合哈希(CHMIS)通过优化放宽哈希码,将不同信息源的信息结合到最终的综合哈希码中。多视图频谱哈希(MVSH)将多视图信息分解为二进制代码,并使用码字乘积来避免不良嵌入。这类哈希方法一般是利用一个实例的多个信息源进行组合来提高哈希码的搜索精度,对于跨视图相似搜索没有实现。它们只有在所有信息源都可用的情况下才能很好地工作,这在现实世界中需求量太大。
在本文中,我们提出了一种新型的哈希方法,基于协同矩阵分解的哈希方法(CMFH)。CMFH 假设一个实例的每个视图都会产生相同的哈希码,这些哈希码并不是不同视图中的一些哈希码的组合或并发。图 1 说明了上述两类方法和 CMFH 的区别。对于每个实例,我们通过协同矩阵分解与潜因子模型从不同的视图中形成源学习统一的代码。为了保证学习到的哈希码可以搜索到不同的视图,我们还为每个视图学习线性哈希函数,以确定未见实例的二进制代码。我们的论文有以下贡献:
- 我们提出了一种跨视图场景下的统一哈希方法,不仅可以支持跨视图搜索,而且可以通过合并多个视图信息提高搜索精度。
- 我们的工作是首次尝试采用协同矩阵分解(CMF)技术来学习跨视角的哈希函数。我们的实验证明,当有多个视图信息源时,CMF 是一种有效的哈希方法。
- 我们证明所提出的 CMFH 是一种具有近似双连续性的相似性保存哈希方法。

图 1. 三类方法的区别
2 基于协同矩阵分解的哈希方法
在本节中,我们将介绍我们的多模态数据哈希方法,即基于协同矩阵分解的哈希方法(CMFH)。在不失通用性的前提下,我们首先介绍双模态情况下的 CMFH,因为它简单易懂。
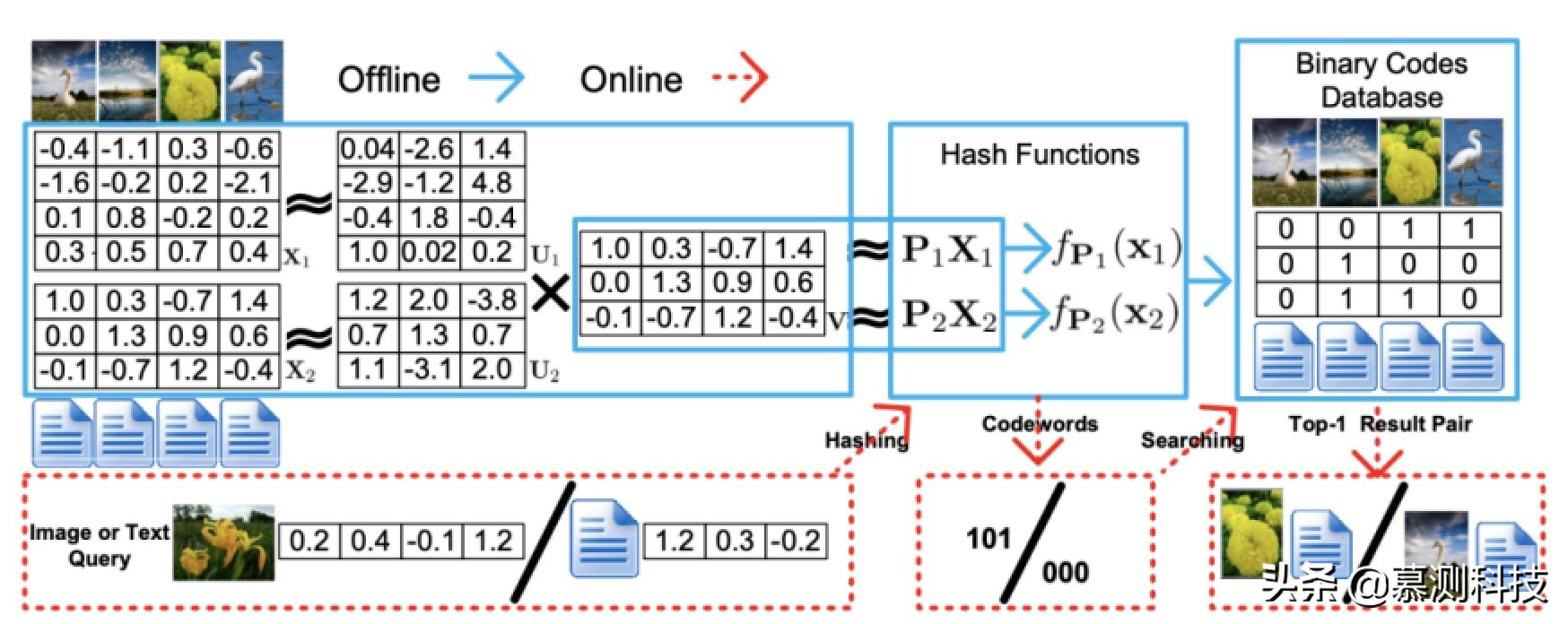
图 2. CMFH 的框架
如图 2 所示,所提出的 CMFH 包括两个阶段。一个是离线哈希函数学习和数据库生成,另一个是在线编码和搜索。在离线阶段,CMFH 学习统一的哈希码 Y = [y1 , ..., yn ]。对于样本外的实例,CMFH 学习第 t 个视图的特定视图哈希函数 ft。与之前的工作类似,我们只考虑了以下形式的仿射
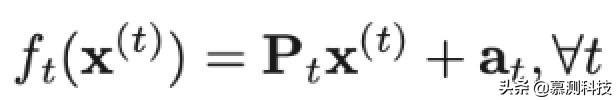
我们可以通过矩阵分解从源数据集中学习潜在的语义特征。我们假定:
1.相互关联的数据应具有相同的潜在语义表示。
2.哈希码可以从潜在语义表示中学习
本方法的优化问题为非凸问题,有五个矩阵变量 U1,U2,P1,P2,V,幸运的是,在固定其他四个矩阵变量的情况下,对五个矩阵变量中的任何一个都是凸的。因此,该优化问题可以反复迭代求解,直到收敛为止。该方法可总结为算法 1。

3 实验
我们在三个不同的数据集上进行了实验:Wiki、NUS-WIDE 和 MIRFLICKR-25000。我们将所提出的 CMFH 与几种最先进的方法进行了比较,实验结果表明,CMFH 的性能明显优于基线方法。
3.1 实验设置
WiKi。它是从维基百科中收集的 2,866 个图像-文本对。每幅图像由 128 维的 SIFT 直方图表示,每篇文字由 10 维的主题向量表示。它包含 10 个语义类,每对图像都被标记为其中之一。我们将 75%的对子作为训练集,其余 25%作为查询集。
NUS-WIDE。它是一个真实世界的网络图像数据库,包含 81 个概念和 269,648 张带标签的图像。我们对十个最大的概念和相应的 186,577 张图片进行了讲解。图像由 500 维的 SIFT 直方图表示,文本由最常见的 1000 个标签的索引向量表示。每对图像由 10 个概念中的至少一个来注释。如果它们至少共享一个概念,则认为它们是相似的。我们使用 99%的数据作为训练集,其余 1%作为查询集。
MIRFLICKR-25000。它由 25000 张图像组成,每张图像都被一些标签注释为 38 个唯一的标签。图像由 100 维度的 SIFT 直方图描述,主要编码表面纹理,144 维度的 CEDD 特征主要是颜色和边缘直接性。由于它们在纹理空间上相似,而在颜色空间上不同,我们选择它们来模拟跨视角环境。我们将 75%的对子作为训练集,其余 25%作为查询集。
CMFH 与五种最先进的散列 55566 方法进行了比较。LSH , CVH , IMH , CMSSH 和 CHMIS .它们可以分为三种类型。LSH 是单视图哈希方法,而 CVH、IMH 和 CMH 是跨视图哈希方法,其中学习特定视图的哈希码,CHMIS 是跨视图方法,学习综合哈希码。我们仔细调整了它们的参数,并报告了它们的最佳结果。
3.2 实验结果
表 1. mAP 对比,View1 为图像或 CEDD,View2 为文本或 SIFT
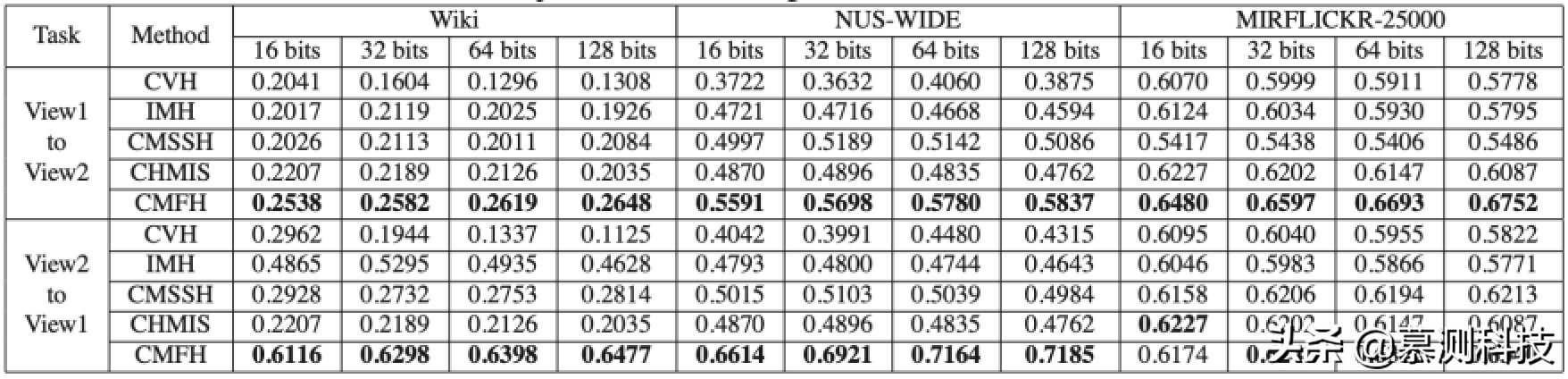
表 1 报告了 CMFH 和四种基线方法的 mAP 值。图 4 绘制了精度-召回曲线。我们可以观察到,CMFH 在两个不同代码长度的任务上都显著优于所有基线方法,这验证了 CMFH 的有效性。
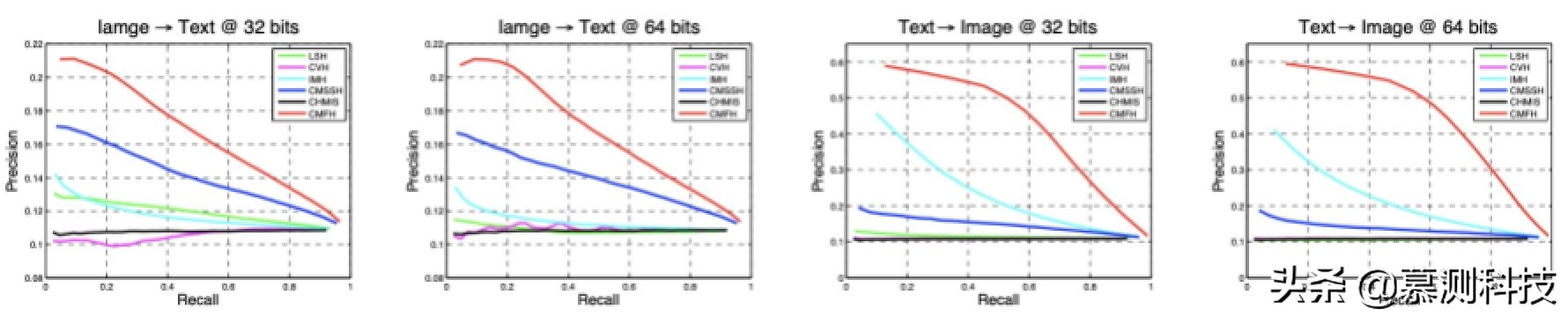
图 4. 不同代码长度的 PR 曲线
此外,CMFH 在代码较长的情况下表现更好。这是合理的,因为较长的哈希码可以编码更多的信息,因此可以提高 mAP 表现。然而,我们可以观察到几种方法的 PR 曲线看起来很奇怪,例如 CVH 在 64 位时的 PR 曲线在实验中表现得像随机猜测。实际上,所有的基线方法都是通过特征值分解来解决的,并且对每个位子都有正交约束,所以每个位子之间没有相关性。前几个投影方向可能具有较高的方差,其对应的哈希位可以具有相当的判别能力,这对相似性搜索相当有用。但是,随着码长的增加,哈希码将以方差很低的位为主。其实,由于方差太低,低位的比特是没有意义的,也是模棱两可的。所以这些不加区分的哈希位可能会导致该方法在实验中进行随机猜测。
表 1 报告了 CMFH 和四种基线方法的 mAP 值。如上所述,我们随机选取 5000 个实例作为训练集来学习哈希函数。并将学习到的哈希函数扩展到整个数据库中。CMFH 在两个任务上都显著优于所有基线方法,不同的代码长度。
此外,我们还比较了不同哈希方法在 NUS-WIDE 上进行单视图相似度搜索的性能。我们可以观察到,结合了一个实例的多个信息源的 CMFH 可以优于其他哈希方法。这是合理的,因为当结合多个视图时,一个实例的更多信息可以被编码成哈希码。此外,这个结果也验证了 CMFH 通过合并多个信息源来提高搜索精度的能力。
在实际应用中,由于计算资源的限制,数据库的规模可能非常大,不可能对整个数据库进行哈希函数的学习。而且随着时间的推移,新的数据不断进入数据库,必须为新数据输入哈希码。本研究的目的是为了解决这些问题,在一个较小的训练集上学习哈希函数,并将其扩展到样本外的实例(数据库中的其他实例或新出现的实例)。在 NUS-WIDE 上的实验设置与现实世界的场景相当相似。实验结果表明,CMFH 可以很容易地处理样本外的实例,并且具有处理大规模数据库的能力。
另外,表 1 还报告了 CMFH 和四种基线方法的跨视角相似性搜索的 mAP 值。如上结果,CMFH 在跨视角相似性搜索中可以优于所有不同代码长度的基线方法。

上一节中描述的贪心算法的计算成本很高,因为它每一步都要调用一个决策过程。我们现在提出一种成交相对较低的技术,它依赖于数据,避免了多次调用决策过程。我们的想法是观察大量输入的激活特征,并学习各种输出属性的决策模式。在本文中,我们使用决策树学习来提取基于层中神经元的激活状态(激活或未激活状态)的紧凑规则。采用决策树是很有必要,因为决策树能够根据各种信息理论的衡量标准得到一个决策模式,并且是紧凑的(因此具有较高的可靠性)。所得到的模式是经过实证验证的层属性,可以通过对决策过程的一次调用来正式检验。
4 总结
多模态数据的跨视图相似性搜索。CMFH 通过协同矩阵分解与潜因子模型从一个实例的不同模态中学习统一的哈希码,可以对不同视图进行搜索。我们还表明,CMFH 是一种具有近似双连续性的相似性保存哈希方法。
我们进行实验来验证所提出的 CMFH 的有效性。我们表明,在所有的跨视角和大多数单视角相似性搜索实验中,CMFH 的性能比几种最先进的哈希方法好得多。参数分析表明,CMFH 对参数设置并不敏感,在很宽的参数值范围内都能提供显著的性能。此外,CMFH 能够轻松处理样本外的实例,并且能够从大规模数据库中以合理的小训练集学习稳定的哈希函数,这使得它适用于实际场景。
5 致谢
本文由南京大学软件学院 2019 级硕士刘佳玮转述























