时间序列回归档案
[Submitted on 19 Jun 2020 (v1), last revised 22 Jun 2020 (this version, v2)]

回复 ts13 获取论文及项目源码
摘要
在过去十年中,时间序列研究引起了很多兴趣,尤其是在时间序列分类(TSC)和时间序列预测(TSF)方面。 TSC的研究极大地受益于加利福尼亚大学河滨分校和东英吉利大学(UCR / UEA)时间序列档案。另一方面,时间序列预测的进步依赖于时间序列预测竞赛,例如Makridakis竞赛,NN3和NN5神经网络竞赛以及一些Kaggle竞赛。
每年,成千上万篇针对TSC和TSF提出新算法的论文都利用了这些基准测试档案。这些算法是为解决这些特定问题而设计的,但是对于诸如使用光电容积描记图(PPG)和加速度计数据预测人的心率之类的任务可能没有用。我们将此问题称为时间序列回归(TSR),在此我们对从单变量或多变量时间序列预测单个连续值的更通用方法感兴趣。此预测可以来自相同的时间序列,也可以与预测器时间序列不直接相关,并且不一定需要是将来值或严重依赖于最新值。
据我们所知,时间序列研究界对TSR的研究很少受到关注,也没有针对一般时间序列回归问题开发模型。大多数模型都是针对特定问题开发的。因此,我们的目的是通过引入第一个TSR基准测试档案库来激发和支持对TSR的研究。该档案库包含来自不同领域的19个数据集,这些数据集的维数,长度维数不相等以及值缺失。在本文中,我们介绍了此存档中的数据集,并对现有模型进行了初步基准测试。
总结
我们发布了包含19个时间序列数据集的TSR存档的第一版,并使用典型的机器学习回归和最新的TSC模型为存档设置了初始基准。我们的结果表明,Rocket是最先进的TSC模型之一,总体表现最佳。最先进的机器学习模型(例如XGBoost和Random Forest)也非常具有竞争力。这表明需要针对此类TSR问题开发更好的模型。最后,我们欢迎您提供任何数据捐赠,并将继续扩展档案库,从而解决更多问题。
回复 ts13 获取论文及项目源码
19套数据集介绍
表1:当前TSR存档中的时间序列数据集。用星号(*)标记的那些在维度之间具有不同的长度,但是在数据集中的所有实例之间长度仍然相等。
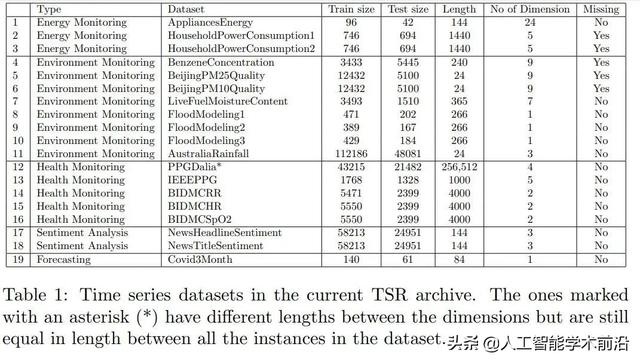
TSR归档中的数据集。当前存档包含19个时间序列数据集,如表1所示。你可以在http://timeseriesregression.org/上找到它们。档案包含8个数据集改编自UCI机器学习知识库[1],3个来自Physionet, 1个来自信号处理竞赛[29],1个来自世界卫生组织(WHO), 1个来自澳大利亚气象局(BOM),其余的都是捐赠的。
本档案目前涵盖了5个应用领域:能源监测、环境监测、健康监测、情绪分析与预测。
ts格式用于tsml和sktime时间序列机器学习知识库。
sktime网站和我们的github页面上可以找到一个将数据加载到Python的例子。
原始数据集中的缺失值不被注入和表示为“?”符号,遵循UCR/UEA档案中使用的.ts惯例[5,6]。为了对回归模型进行公平的比较,我们将存档中的数据集分割为预定义的训练集和测试集。























