前言
写过很多技术贴,今天换个维度写点别的话题,来聊聊程序员的职业发展。
不管是对于大厂还是其他软件公司,都会有全栈工程师这个职位,而且这个职位的薪资待遇明显比其他同等级的职位高出不少。
重赏之下必有勇夫,所以大家对这个职位的关注度更高一些也在情理之中。虽然每个公司对于全栈工程师的要求以及定位都各不相同,但是大体上来看,全栈工程师大概需要有以下几个特质:
- 一个人有处理一条数据链路或者业务链条的能力,能有端到端的开发能力那就太好了
- 不仅要有开发能力,还要有一定的设计能力,毕竟你这条业务线的数据或者接口大概率还是会被其他业务线来使用的,所以必要的设计能力还是很重要的
- 除了代码编写以外,数据库的设计包括运维方面的相关东西也需要能hold住,毕竟这是一个闭环,你需要对其他人提供一整套系统或者模块
一言以蔽之,就是当爹又当妈,所有的任务都是你的,所有的锅也都是你的,当然所有的成就感也由你自己独享。
上面的要求就注定了全栈工程师不是你想做,想做就能做的,毕竟人才易得,全才难求。
诸如NBA,有无数强力内线在禁区内利用身体天赋和华丽技术予取予求,也有无数顶尖后卫在弧顶和外线利用犀利突破和精湛射术翻江倒海,但是却很少有人能同时拥有内线和后卫的技术,能内能外从一打到五。
所以全栈工程师是很多研发人员的final fantasy,作者曾经也有类似的理想。但是随着时间的推进,技术的发展,作者感觉离这个目标越来越远,甚至可能永远也没办法成为全栈工程师了,那看到这篇文章的你,离这个目标还有多远呢?
如果想快速测试离全栈差多少,可以直接看文末最后一张图,看看那些技术图标你都认识多少?
十年前的全栈
首先作者是做JAVA出身,所以这里就以十多年前的JAVA应用开发流程作为样例来进行讲解,但是我技术都是相信大同小异的,而语言只是实现技术的工具。
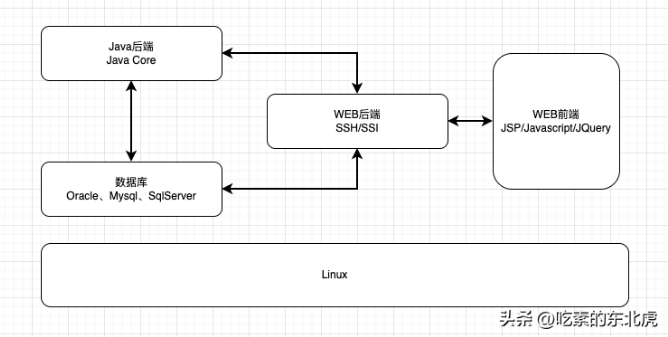
作者第一次接触到全栈大概是10年前,那时候作者也工作个3,4年,也有了点开发经验,那时候很是羡慕那些全栈大师,能一个人搞定所有的东西,任何客户现场的项目部署以及调试他一个人去就行了。
现在回头看看那时候的全栈要求,相对来说还是比较简单的,所有的技术栈都不是很复杂,拼接到一起基本上就能满足基础的全栈需求。
后端
十多年前的JAVA后端基本上就是java core以及ssh或者ssi。技术发展慢的好处就是可供选择的东西不多,很容易形成行业标准,大家把行业标准的技术和玩法搞熟练了就可以包打天下了。
前端
那时候的前端基本上主流就是JSP,脚本语言就是JavaScript+jQuery,再加上css,基本上就能hold住前端的需求了。
数据库
大部分就是SQL三剑客Oracle,SqlServer以及MySQL的天下,偶尔在大客户的现场会遇到DB2或者TeraData等高端数据库。但是除了标准SQL之外的差异化的语法,其余的基本上大同小异,尤其是应用或者系统开发(数据库DBA不在此讨论范畴内,在那个时代这个是神一般存在的职业)。
处理的数据都是结构化的数据,少量的非结构化和半结构化的数据基本上就是存硬盘,大部分场景下就是送到仓库中吃灰或者在需要使用的时候能找到然后使用即可。
运维
那时候的运维部署大部分的场景就是给一台linux服务器,在上面安装Tomcat,高端点的就是Weblogic或者WebSphere这种90后基本上没怎么听说过的上古神器。然后把打好的jar包以及war包放到固定的位置,使用web容器发布后,即可以通过web页面或者C/S架构的客户端运行和使用系统了。
后续的运维就是通过各种脚本、自研的监控系统或者Zabbix这种监控软件进行监控和运维即可。
现在的全栈
上面的全栈说得很简单,虽然实际情况会比上面描述得复杂一些,但是并没有复杂太多。个人感觉这时候的全栈还是很有希望达到的。
但是仅仅十年过去了,一切都已改变,完全看不出之前的模样了,到底发生了什么?
下面再来看看现在的全栈,作者认为只是粗略地列举了下,并不是全貌。但就算如此,你会有什么感想呢?
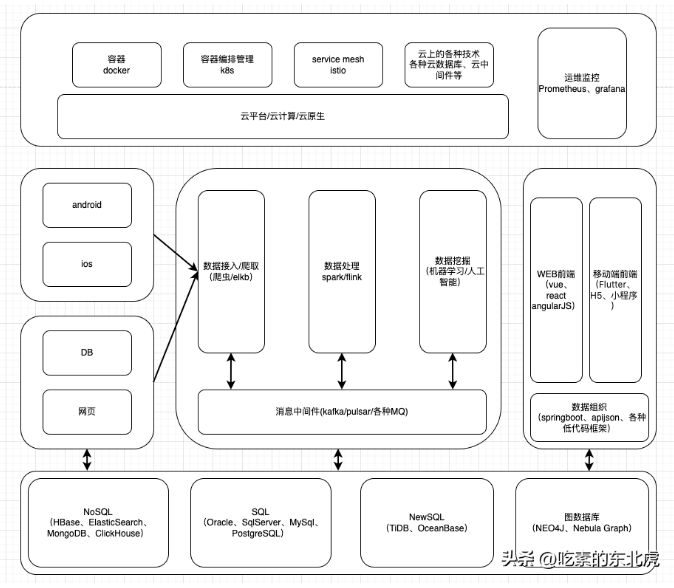
后端
此时的后端已经被细分成数据接入,数据处理,数据存储,数据挖掘等多个数据处理流程。数据已经成为了整个后端技术流转的核心,整个业务的流转基本上就是数据流转的过程。
至于技术,不胜枚举:
- 数据接入已经从十年前的库表文件导入或者业务录入转化成多元化的数据接入技术。除了传统的TCP和UDP数据接入外,爬虫也大行其道;至于商业化公司如elastic公司的elkb这种体系化的数据接入和处理流程也是深受欢迎。
- 数据处理处理传统的java外,数据处理已经从第一代的mapreduce、hive、storm以及impala框架进化到了以spark或者flink为主的新一代批流一体化的框架所代替。而且这些框架也互有攻守,无法形成一家独大的行业标准。
- 数据存储已经不是之前的sql以及jdbc的行业标准,而变成了以数据库为导向的不同api的操作,虽然现在都在推SQL标准在不同数据库的落地,但是大部分的情况下,还是需要使用不同的api进行各种操作,学习成本可见一斑。
- 数据挖掘就不多说了,之前基本上就没有。随着大数据时代的来临,机器学习以及人工智能大行其道。这对于一个人的综合实力的要求还是很高的,尤其是各种数学以及算法,真正考验基本功了。我也开始理解为什么很多算法岗位的招聘要求是211、985硕士甚至博士起,因为没有长时间的基本功沉淀是真的搞不定啊。而作者确实也”不负众望“,从入门到放弃仅仅用了一周的时间。
前端
现在的前端以及分网页端和移动端的双端了,而且前端的全栈的要求已经是端到端了,即从移动端到网页端的业务和数据的处理和展示。
至于技术,也是五花八门,作者不是很熟悉前端,这里就不多说了。当初作者放弃前端的一个原因就是因为前端的内容多于繁琐和复杂,而现在更是有过之而无不及。
数据库
这算是作者的老本行了,最近这些年基本上都是以这个为基础结合上下游来展开工作。当前的数据库已经不是当年的数据库了,不仅种类多了很多,而且单一种类也有很多不同的产品应对不用的业务场景。更麻烦的是,每个数据库产品都无法覆盖所有的场景,而且很多数据库之间都有交叉,没办法做到one db to rule them all!这无疑极大地增加了学习成本。
下面就是现在的数据库分类:
- SQL
- NoSql
- NewSql
- GraphDB
细节的分类和数据库就不多说了,因为实在是太多了,而且新的数据库也是层出不穷,更过分的是每个数据库基本上都有受众,也都能火那么一段时间,大部分也仅仅就是那么一段时间,但是对于从业者来说大多数时候真的是痛并“快乐”着....
运维
之前的运维玩明白linux和一个主流的运维软件即可。现在的运维真的是玩出花了。
之前的虚拟化已经难堪大用,云计算和云平台登上了历史舞台,公有云和私有云遍地开花;再后来是以Docker为首的容器掀起了容器化的浪潮;再后来云原生横空出世,甚至抛出了“一切皆可云原生”的豪言壮语。
当前的运维已经慢慢形成了以K8S为首的容器编排与管理,istio等一系列service mesh作为辅助的运维体系,在这个体系周围衍生出的技术也不胜枚举。运维小哥哥再也不能一招鲜吃遍天下了,而对于研发人员来说,想跨界搞专业运维的难度和成本也越来越高
至于监控,虽然Prometheus+grafana在大多数场景下都是标准选择,很多组件也都有响应的扩展包来支持在上述二者上的部分监控。但是多数情况下,很多专业的监控以及运维还是需要定制化的监控界面,甚至很多大厂都自行开发监控和运维工具以求更精准和有效的运维。
总结
曾几何时,作者的理想也是做一个全栈工程师。但是十年之后笔者才发现,原来当初刚刚怀揣这个理想的时候竟然是离目标最近的时候。
这里面固然有作者水平有限的问题,但是更深层次上的是技术和业务的发展速度已经大大地超出了预期。此一时彼一时,当前的技术广度大大增加,而技术密度却逐渐降低。一招鲜吃遍天下或者一个架构搞定一个行业的时代早已不复存在了。
而此时的全栈已经很难和当初的全栈相提并论,能做到细分领域的全栈或者一专多能已经相当不易了。但是理想还是可以有的,能不能实现不重要,能作为前进的动力就好。
白月光虽好,但总是遥不可及;朱砂痣若有,牢牢把握住就好!
全栈不死,只是凋零;不是全栈淘汰了我们,而是时代淘汰了全栈!
文章到这里就结束了,最后路漫漫其修远兮,大数据之路还很漫长。如果想一起大数据的小伙伴,欢迎点赞转发加关注,下次学习不迷路,我们在大数据的路上共同前进!
最后留个彩蛋,看看下面的图标你都认识多少?能快速测试你离全栈还有多远,作者看了下,认识的还不到一半,所以我这辈子可能永远没法成为全栈工程师了....




























