阿里GPT测评:AI摩尔定律时代真的来了?
半导体领域的摩尔定律正在失效,AI世界的“摩尔定律”才刚开始。不久前,OpenAI CEO 、“ChatGPT之父”Sam Altman发文指出,全球AI运算量每隔18个月就会提升一倍。从科技公司对GPT你追我赶的态势看,“AI摩尔定律”,也许正在成为全球大模型竞争的节拍器。
继OpenAI、微软、谷歌之后,中国公司也正加速公布各自的大模型研发进展。上周,阿里云官宣其大模型“通义千问”启动企业邀测,达摩院多年磨一剑的AI研发工作初现真身。电脑报参与了“通义千问”的定向邀测,短短几天内,感受到了中国大模型「以日为进」的成长速度。
阿里云大模型“通义千问”亮相
从OpenAI 的ChatGPT到百度的文心一言,同AI对话成功挑起人类的好奇心,而就在人们为“哪家AI更聪明”争论不休时,阿里云突然宣布“通义千问”开始企业邀测。

“通义千问,一个专门响应人类指令的大模型。我是效率助手,也是点子生成机,我服务于人类,致力于让生活更美好。”——这是“通义千问”官方主页上对自己的介绍,单从字面上了解,“通义千问”更像是一个问答平台或对话工具,但登录进入其交互界面后,“通义千问”对自己的“工作范畴”其实是有引导性解释的。
在“通义千问”页面最下方的“百宝袋”通道,展示了9种应用,这些应用被分为3类:效率类、生活类和娱乐类。
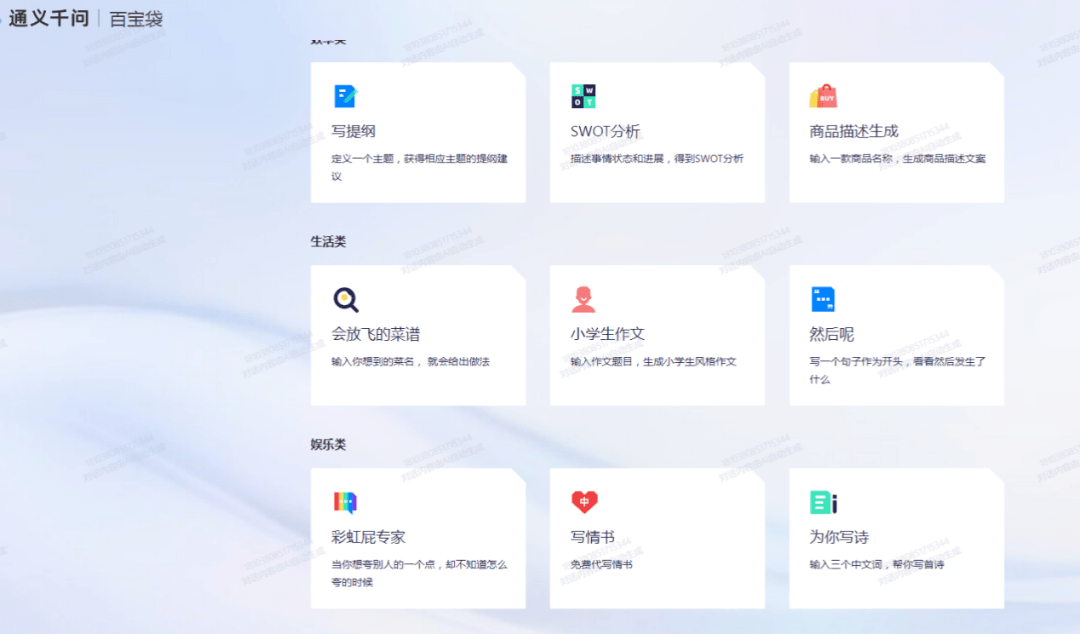
在娱乐类应用中,有“彩虹屁专家”“写情书”“为你写诗”3个功能,比如“彩虹屁专家”,当你想夸别人,却不知道怎么夸的时候,就能让通义千问帮吹一些彩虹屁。
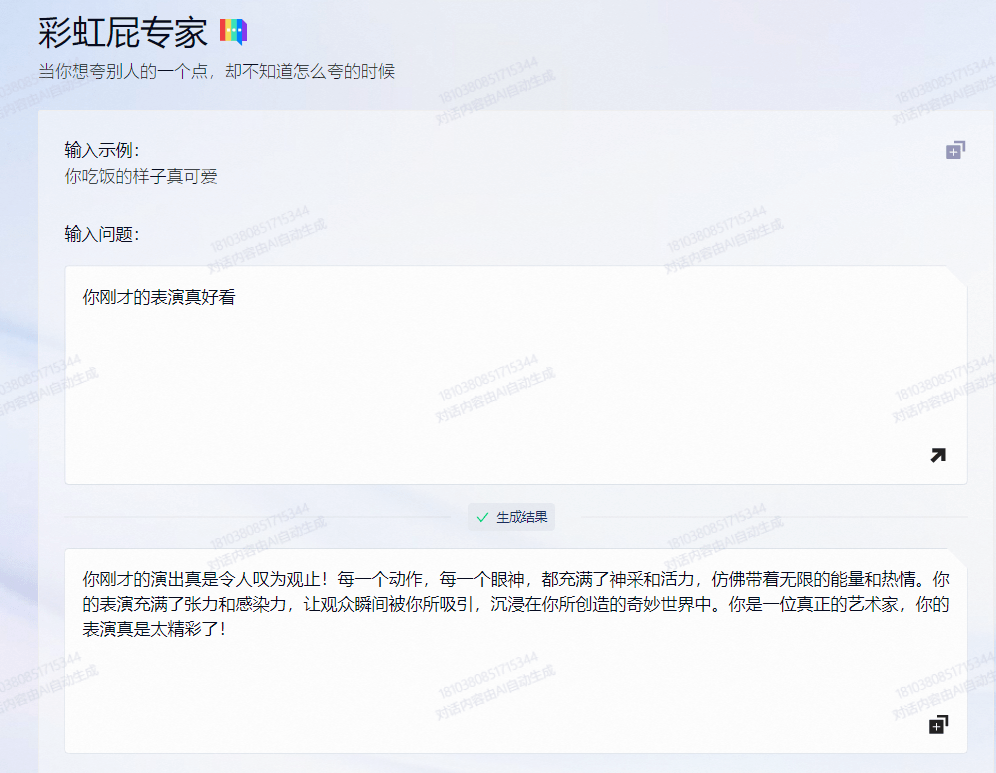
显然,从这9种应用定位可以看出,“通义千问”并非单纯用于对话娱乐,更有生产力工具属性,而在我们输入“通义千问自身定位是?”提问时,它是这么回答的。

以“日”为单位成长的AI
“最初第一批拿到测试资格时蛮兴奋的,第一时间就尝试同‘通义千问’进行对话,但对话结果却有些失望,除‘牛头不对马嘴’外,更给出了不少错误答案。可当我们带着失望心情在第二天输入同样问题时,‘通义千问’竟给出了近乎完美的正确答案,这种‘低开高走’的测试真的很刺激,‘通义千问’真是以肉眼可见的速度在成长!”
2023年4月8日,《电脑报》记者根据热点新闻事件向“通义千问”提出“能否制作一段有关石墨烯的视频脚本?”要求时,它写出来的视频脚本非常生涩,甚至像说明文多过视频脚本。

“通义千问”在4月8日时写的视频脚本更像是说明文
然而,仅仅过了一天时间,当记者在4月9日向“通义千问”再次提出“能否制作一段有关石墨烯的视频脚本?”时,“通义千问”非常准确地了解了记者需求,且创作出可行性较高的视频脚本,从旁白对话到画面设计,都给予了详细的内容和建议。

每天都在变强的“通义千问”成功吊起我们好奇心,同当下主流免费的ChatGPT(GPT3.5)和文心一言相比,“通义千问”能力究竟如何呢?
一场“谁更聪明”的对局
2023年4月9日,我们分别从逻辑思维及语言组织能力(教育心理分析)、语言文字创作能力(小学生作文)及非线性思维能力(数学组合题目)三个方面进行了横向测试。当下各家AI更新太快,本次结论仅做测试当日参考。
逻辑思维及语言组织能力:如何处理同叛逆期初中生的亲子关系?
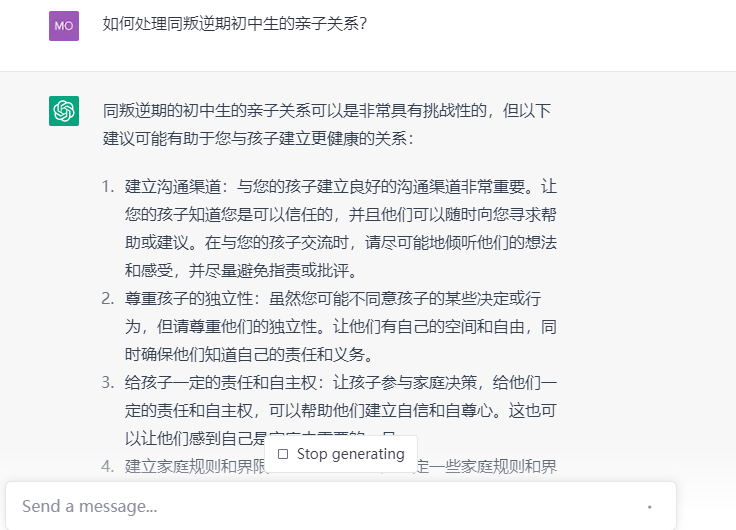
ChatGPT(GPT3.5)在该测试场景下的表现堪称完美,整体逻辑非常有条理,将同孩子关系的处理方式方法进行了罗列,具有较强的说服性。

文心一言回答显然简单了许多,这样的回答想要说服一个叛逆期的初中生,显然不太具有可执行性。


通义千问的逻辑性已经和ChatGPT不相上下,其给出的解决办法具有比较明显的条理性。
点评:无论是ChatGPT还是通义千问,都已具备初步逻辑思维能力,完全可以应对日常交互,并针对用户需求给出符合逻辑的解决方案。
语言文字创作能力:帮我写一篇赞美秋天的作文
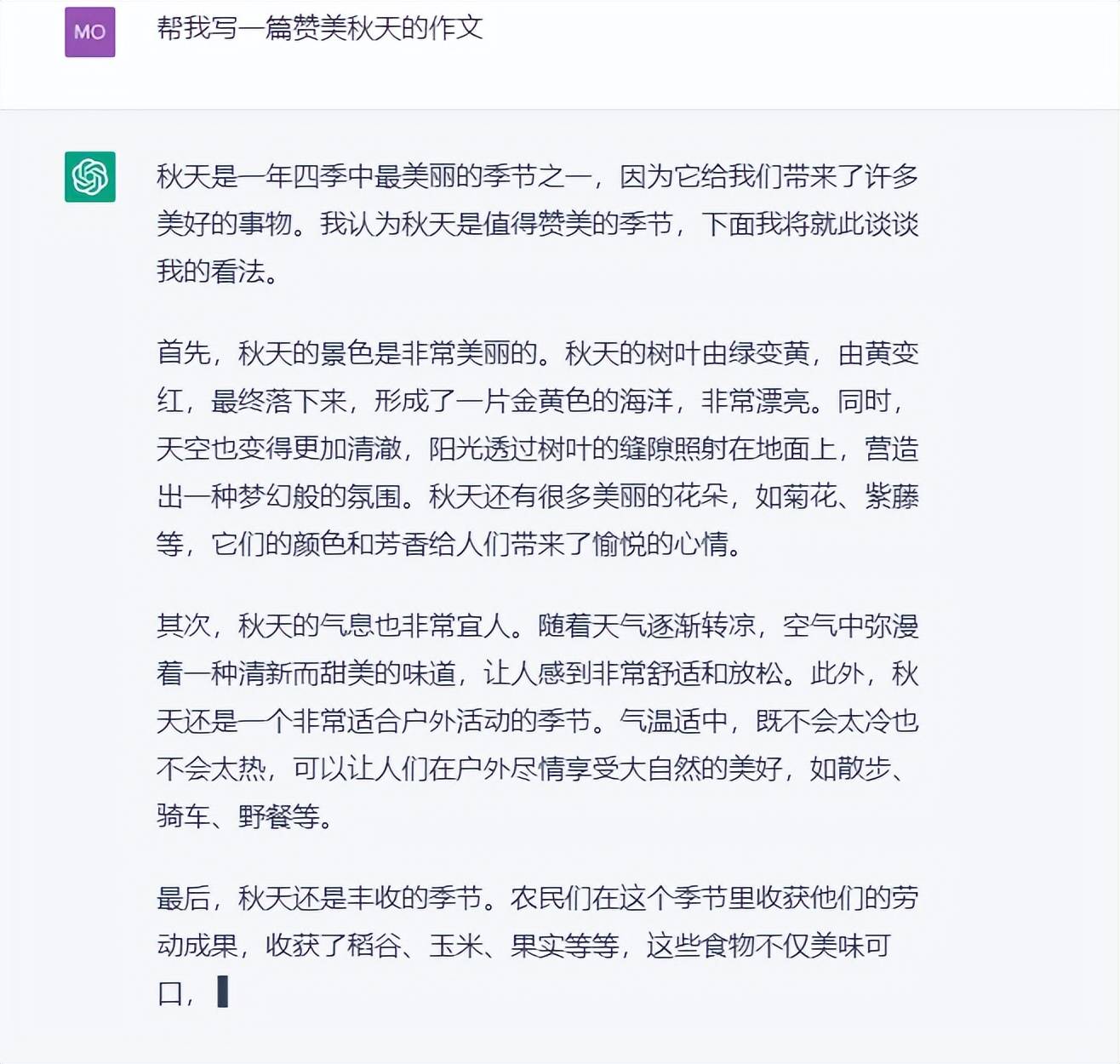
在文字描述细节上,ChatGPT(GPT3.5)抓住了秋天的特点,但在文章结构和具体事物的表述上显得有些僵硬,对于这样一个相对简单的入门级作文,ChatGPT(GPT3.5)的表现让人有些失望。

文心一言将果实作为赞美秋天的核心来展开,很好地领悟了中文作文“主次分明”的技巧。只是在对秋天整体的把控上稍欠火候。


通义千问的作文能力多少让人有些惊喜,总分总的结构拿捏得十分到位,开篇明义的同时,通过树木、树叶、果园三个事务在秋天的表现,完成了秋天具象化描写,很好地表达了对秋天景色的赞美和喜爱之情。
点评:从作品看,三款AI在语言文字创作能力上均有不错的表现,尤其是通义千问对作文的打造显得非常“老练”,稍加修改就能成为一篇传阅的优秀范文,整体作文的逻辑性上稳压ChatGPT一筹!
非线性思维能力:老师打算将 10 张相同的积分卡分给甲、乙和菲菲,甲想得到至少 4 张,菲菲想得到至少 3 张,乙则表示无所谓,给不给他都行,若老师打算满足每个人的要求,共有多少种分法呢?
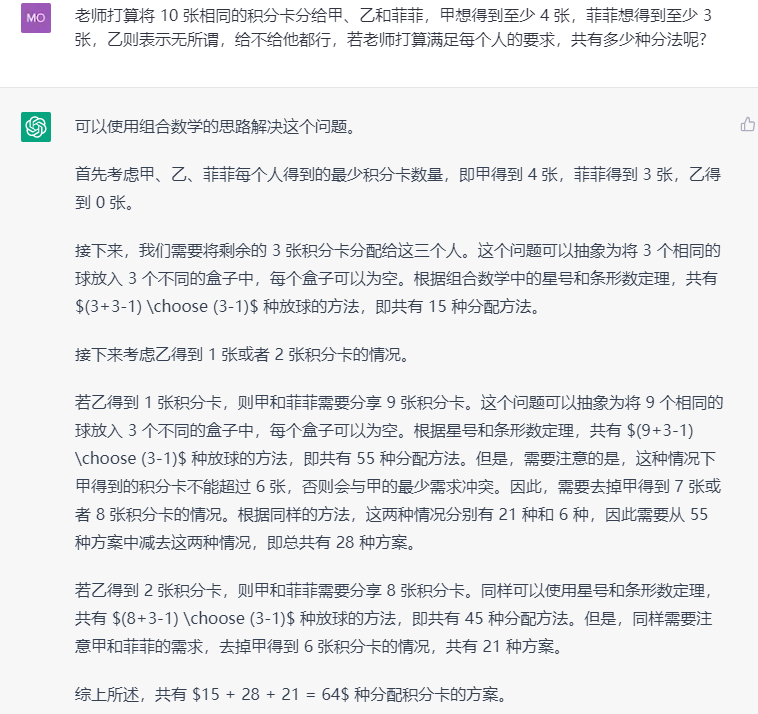
答案错误,显然,ChatGPT(GPT3.5)这一次在一本正经的胡说八道。
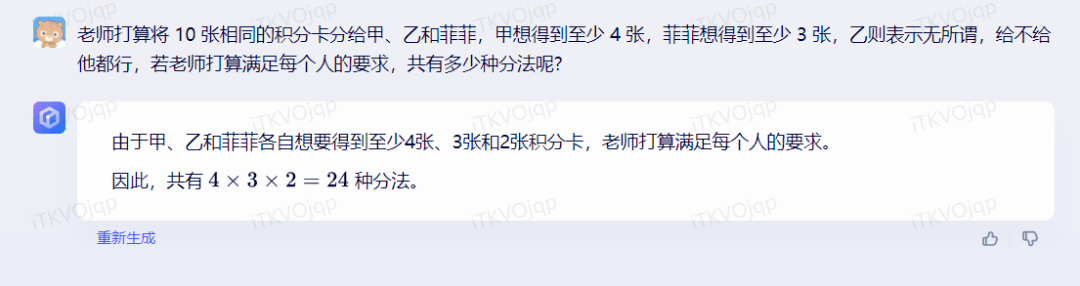
答案错误,虽然文心一言简短的回答看上去挺有自信,可答案依旧错了。

通义千问的解题思路非常清楚,条理清楚地对问题进行了分布求解,不过遗憾的是依旧没有给出正确答案。
点评:相对于编程、鸡兔同笼、流水行船、牛吃草等线性思维的数学学科题目,排列组合这类非线性思维模式题目能考验AI自主思考能力。显然,从这道题目的测试情况看,三家AI均败下阵来,不过非线性学科问题本身就是AI测试的难点,很期待未来AI在该领域的表现。
科技巨头的大模型之战
“通义千问”并非凭空出现,而是阿里厚积薄发的结果。
阿里达摩院深耕 NLP 领域,在大模型技术路径上具备多年前瞻技术积累,阿里达摩院于2019 年启动大模型研发,在超大模型、语言及多模态能力、低碳训练、平台化服务、落地应用等多个方面,为中文大模型的发展做出一系列探索工作。

动辄超千亿参数的大模型研发,不是单一的算法问题,也不是简单的堆算力的过程,这是囊括了底层算力、网络、存储、数据清洗与治理、AI 框架、AI 算法、人类调优等多个方面的系统性工程问题。
目前头部科技企业均采取“模型+工具平台+生态”三层共建模式,有助于业务的良性循环,也更容易借助长期积累形成竞争壁垒,国内大模型厂商目前主要为百度、阿里两家。
2022 年 9 月,在世界人工智能大会上,阿里巴巴达摩院主办“大规模预训练模型”主题论坛,达摩院副院长周靖人发布阿里巴巴最新“通义”大模型系列,并宣布相关核心模型向全球开发者开源开放;2022年云栖大会上,阿里推出魔搭平台,并在业界率先提出“模型即服务”(Model as a service,MaaS)概念。面向大模型通用性与易用性仍欠缺的难题,通义打造了业界首个 AI 统一底座,并构建了大小模型协同的层次化人工智能体系,将为 AI 从感知智能迈向知识驱动的认知智能提供先进基础设施。

以统一底座为基础,达摩院构建了层次化的模型体系,其中,通用模型层覆盖自然语言处理、多模态、计算机视觉,专业模型层深入电商、医疗、法律、金融、娱乐等行业。
而如此庞大的构想底气源自阿里系庞大的算力。根据行业权威研究机构Gartner 2021 年全球云计算IaaS 市场份额数据显示,阿里云排名全球第三,市场份额为9.55%,连续六年实现份额增长;同时,阿里云排名亚太市场第一,市场份额为25.53%。
在AI 算力方面,2022 年阿里云宣布正式推出全栈智能计算解决方案“飞天智算平台”,为科研、公共服务和企业机构提供强大的智能计算服务,通过先进的技术架构,飞天智算平台实现了90%的千卡并行计算效率,可将算力资源利用率提高3 倍以上,AI 训练效率提升11 倍,推理效率提升6 倍。

依托于坚实的云计算底座,AI正像水一样浸润到千行百业,帮助更多企业从数字化走向智能化,更多应用涌现出更智能的新功能和新体验。
对于这样的变革,你会期待吗?