傻傻分不清的TCP keepalive和HTTP keepalive
1.TCP keepalive
1.1.概念
A keepalive (KA) is a message sent by one device to another to check that the link between the two is operating, or to prevent the link from being broken.
——From wiki
TCP keepalive是TCP的保活定时器。通俗地说,就是TCP有一个定时任务做倒计时,超时后会触发任务,内容是发送一个探测报文给对端,用来判断对端是否存活。(想到一个桥段:“如果2小时后没等到我的消息,你们就快跑”)
1.2.作用
正如概念中说的,用于探测对端是否存活,从而防止连接处于“半打开”状态。
所谓半打开,就是网络连接的双端中,有一端已经断开,而另一端仍然处于连接状态。
1.3.机制
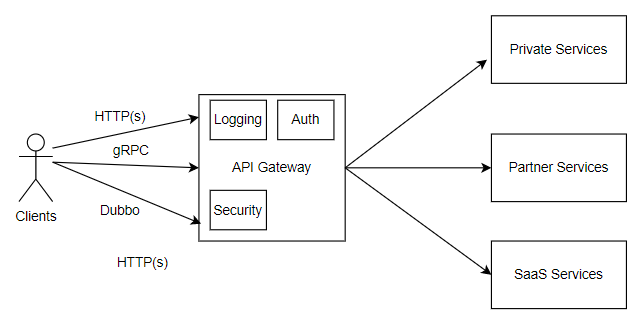
(图一)TCP keepalive 流程图
建立连接的双端在通信的同时,存在一个定时任务A,每当传输完一个报文,都会重置定时任务A。如果在定时任务的时限tcp_keepalive_time内不再有新的报文传输,便会触发定时任务A,向对端发送存活探测报文。根据响应报文的不同情况,有不同的操作分支,如上图所示。
定时任务B会被循环执行,具体逻辑是:定时任务A的探测报文没有得到响应报文,开始执行定时任务B。任务B的内容同样是发送探测报文,但不同的是,B会被执行tcp_keepalive_probes次,时间间隔为tcp_keepalive_intvl。B的探测报文同样也是在收到响应报文后,重置定时任务A,维持连接状态。
上文提到的三个参数存在于系统文件中,具体路径如下:
/proc/sys.NET/ipv4/tcp_keepalive_time
/proc/sys/net/ipv4/tcp_keepalive_intvl
/proc/sys/net/ipv4/tcp_keepalive_probes
通信双端都存在一个文件作为数据缓冲区,对端发送给本地当前端口的数据都会缓冲在这个文件中。上文中讲的“断开连接”就是关闭这个文件,关闭后所有发送到当前端口的数据将无法存储到缓冲区,即数据被丢弃了。
通过指令lsof -i :8080,8080改成你的端口号,便能看到这个缓冲区文件。
2.HTTP keepalive
2.1.概念
HTTP persistent connection, also called HTTP keep-alive, or HTTP connection reuse, is the idea of using a single TCP connection to send and receive multiple HTTP requests/responses, as opposed to opening a new connection for every single request/response pair. The newer HTTP/2 protocol uses the same idea and takes it further to allow multiple concurrent requests/responses to be multiplexed over a single connection.
——From wiki
HTTP keepalive指的是持久连接,强调复用TCP连接。(类似场景:挂电话之前总会问句,没啥事就先挂了,延长通话时长来确认没有新话题)
2.2.作用
延长TCP连接的时长,一次TCP连接从创建到关闭期间能传输更多的数据。
2.3.机制
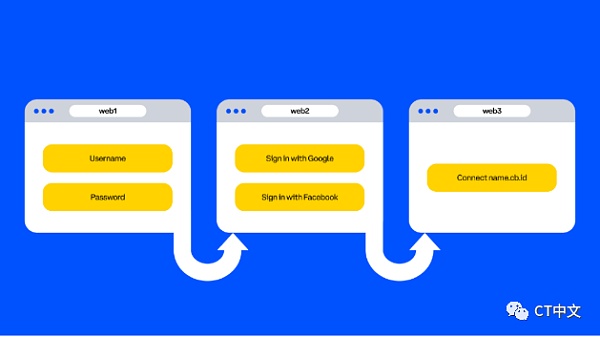
(图二)HTTP keepalive 流程图
通信连接的双端在通信的同时,存在一个HTTP层面的keepalive定时任务。当客户端发起Request,并且接收到Response之后,触发定时任务。定时任务会开始计时,达到keepalive的时间距离后,关闭连接。如果在计时期间,客户端再次发起Request,并且接收到Response,定时任务会被重置,从头计时。
图二用Python/ target=_blank class=infotextkey>Python的socket库为示例进行说明,在HTTP的“请求-响应”过程中,HTTP keepalive(或者称为HTTP持久连接)在底层是如何作用于连接释放流程,从而延长连接时长的。
为什么不用Python的requests库来举例说明?requests底层也是socket连接管理,不同的是requests支持HTTP协议,可以解析出HTTP各部分信息;socket仅仅是从文件缓冲区读取二进制流。同样地,各种Web框架中的Request和Response对象的内部仍然是socket连接管理,只提socket可以排除很多干扰信息。
服务端HTTP keepalive超时后的数据丢弃的说明。刚入门的同学可能也会像我一样感到疑惑:服务端keepalive超时后再收到数据就会丢弃,那么服务端后续还怎么接收端口的数据?
这就不得不提到服务端的fork模型了:服务端主进程监听端口,当数据到来时便交给子进程来处理,主进程继续循环监听端口。
具体地说,当数据到来时,主进程先创建新的socket连接句柄(本质就是生成了socket文件描述符落在磁盘上,端口数据会存储在该文件中缓冲),随后fork出子进程;主进程关闭新的socket句柄,子进程则维持socket句柄的连接(当一个socket句柄在所有进程中都被close之后才会开始TCP四次挥手);此后,子进程接管了与客户端的通信。
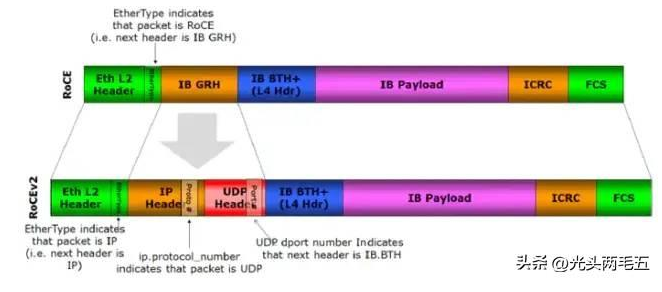
正如(图三)的例子,主进程会fork出很多子进程,A和B分别对接的是不同客户端发来的请求,socket文件描述符a不会影响b的数据读写。
(图三)fork模型下传递socket句柄的过程
结论是,服务端与外界建立的每一个socket连接,都有独立的文件描述符和独立的子进程与客户端通信。服务端断开连接是指关闭了某个文件描述符的读写,并非关闭了整个端口的数据往来,不影响其他的socket连接之间通信。至于丢弃,就是说外界如果还有发往这个socket文件描述符的数据被丢弃,因为这个文件描述符已经禁止写入,自然地数据便无法落地。
3.两者之间的关系
TCP keepalive更像是保障系统有序工作的兜底机制,确保系统最终能收回半打开的socket连接,否则长期运行后无法再接收更多的请求(系统的socket最大连接数限制)。
HTTP keepalive则是应用层的骚操作,使得服务端的应用程序能自主决定socket的释放,因为TCP keepalive的倒计时默认值很长,web服务的某次连接通常不需要等待那么久。说直白点,就是TCP有一个计时器,HTTP也可以自己搞个计时器,如果HTTP的计时器先超时,同样有权利让TCP进入四次挥手流程。
在某个数据包传输后,两个keepalive的定时任务同时存在且一起进入倒计时状态,一个是系统内核TCP相关代码的程序,另一个是高级编程语言(Python/JAVA/Go等)Web框架代码的程序,他们一起运行并不冲突。
4.念经
HTTP keepalive是应用层的东西,在上生产时对外提供服务的应用程序都会有keepalive参数,例如Gunicorn的keepalive、Nginx的keepalive_timeout。通过这个参数,我们能在更高级的层面控制等待下一个数据的时长。
还有,如果同一台服务器有N个Web服务,TCP keepalive参数是全局生效,众口难调。
如果你的网络结构是类似client-nginx-web server,那么你就要同时考虑nginx和web server的keepalive参数大小搭配的问题,此处引用Gunicorn对keepalive参数的使用建议:
Generally set in the 1-5 seconds range for servers with direct connection to the client (e.g. when you don’t have separate load balancer). When Gunicorn is deployed behind a load balancer, it often makes sense to set this to a higher value.
假设web等待时间比nginx短很多,client-nginx的连接还在,nginx-web就已经断开了,web就会错过一些数据,对于客户来说好端端的我拿不到结果是无法容忍的。因此最好是和nginx的等待时间协调好,不要相差太多(不要太短,也不要长很多)。
关于不要太长,多说一句。如果等待很久,web服务会累积维持非常多的连接,这样子新的请求无法打进来,正在维持的连接不见得利用率很高(可能客户端的代码在打断点、可能客户端早就close)。结果就是服务端netstat显示一堆连接,新的请求全都被挂起甚至丢弃。
原文链接:
https://mp.weixin.qq.com/s/duDNJGbQtr05Y4S9_abveQ