容器视角下的网络性能监控
关于企业上云,在几年前大家谈论更多的是OpenStack、资源编排和分配,但近几年上云的应用部署方式发生了很多变化。首先从谷歌搜索的趋势可以发现Kubernetes的关注(热度)已经远远超过了OpenStack,同样在百度搜索趋势中K8s和Kubernetes加起来是OpenStack的两倍。

容器的特点是弹性伸缩,支撑弹性伸缩最主要的两个特征分别是分布式和负载均衡。在这两个特征支撑下,容器可以在业务压力过大时做到弹性伸缩,业务以POD单位进行弹性扩充。
从可达性来看,任何两个POD间都是可达的,而且外部也可以通过Ingress、LB的方式来访问容器集群里面任意的POD,这带来一个问题:服务之间的沟通变多了,东西向流量成为容器环境下的主体流量,而这个流量,传统的流量采集方式无法全部覆盖。
第一:因为传统的流量采集方式是通过物理交换机的镜像、分光等方式,在容器网络环境下,容器间的通信可能在K8s的Node之内或者一个VM的Hypervisor就终结了,很难去到达物理的交换机层面。
第二:即使容器、POD之间的流量能到达物理交换机,随着容器规模的扩张,要想做到全覆盖,投入用于流量采集的成本会急剧增长。
容器的环境下有大量的LB,在提供负载均衡等复杂的场景下,SNAT和DNAT会多次发生,每一次发生地址转换就意味着可能会产生网络性能问题。
即使两个POD之间是三层可达,但是这两个POD的End to End的通信路径上可能会跨越物理服务器的机架,导致可能会跨越接入交换机、物理网元;也可能会跨越两个公有云的AZ、区域,或者不同的云,甚至是在私有云和公有云之间通信。所以任何两个POD之间通过service的访问都可能会有解析、DNS性能以及负载均衡的问题。
在传统网络环境,服务器和虚拟机的IP地址是很少发生变化的,对业务的梳理其实等同于对IP地址身份信息的梳理。由于容器用DNS解析IP,可能存在IP重叠、IP对应的资源身份在不断地变化等,所以在容器环境,对IP身份的识别非常困难。
一般情况下,一个物理机上可以运行10个虚拟机,一个虚拟机上可以运行10个POD,因此容器网络环境的IP数量就有100倍的增长。IP数量的巨增,意味着网络监控的数据至少有100倍的增长。在监控计算、存储资源时,基本上有多少台机器得到的监控数据就是多少个。

但是对于网络监控而言,极限情况下数据是N方的量级,因为网络监控的本质是一个端到端的信息。极端情况下,容器里所有的POD都会产生通信,就相当于有N方的通信需要被监控,因此网络规模非常巨大。
以上这些特点都会导致容器网络监控的难度上升。
分布式系统可观测性需要去集中解决3个类型的监控数据,即Metrics、Tracing和 Logging。分别代表Prometheus监控的指标数据,比如说CPU内存、流量大小等等;第二类Tracing数据,也可以说服务调用栈的数据;第三类是日志数据,比如ELK里的日志分析。二、三类数据关联度会大一些,是每一个请求或每一条日志的数据。

Metrics通常是实现分布式系统可观测性的第一步。它是一个可聚合、可设置报警,面向大规模监控数据做分析和告警判断,针对Metrics通常会关注四个方面的指标量:

它刻画的是当前的业务系统的访问是否顺畅、耗费的时间是否在增加。例如从四层网络的角度看,有三次握手、协议栈响应的时延;从应用的角度看,有HTTP响应、DNS响应的时延。
系统的吞吐。例如一个应用系统的BPS、PPS是多少?新建连接数、新建连接速率是多少?HTTP的请求数是多少等等。
错误可能发生在网络层,比如TCP建连失败、重置、重传等,还可能会发生在应用层,比如HTTP的400、500等错误,或者是DNS解析失败。
一般来讲是对计算和存储资源的描绘,在虚拟网络情况下也可以描述虚拟交换机的负载。网络层面的负载主要体现在并发连接数、当前正在活跃的用户数等指标。
对网络的指标监控通常要考虑以上4个方面,这4个方面能够覆盖一个分布式系统所有的角落,最终实现分布式系统的可观测。
以上可见一个企业需要实现全网流量采集的重要性。往简单了说,在微服务场景下需要考虑服务和服务之间的调用关系,相当于调用栈的追踪。其实服务和服务之间访问,实际上就是POD和POD之间的访问,意味着在网络层面直接能看到它们互访的流量,因此,通过网络流量采集可以直接获取到服务的调用栈。这更加可以说明:流量采集可以解决容器网络可观测性的难题。
那么为什么需要通过流量采集来解决这个问题呢?有两个方面的原因。
第一个方面:从应用的层面无法解决问题。从日志或代码插件很难去感知到网络层面的问题。比如某个访问消耗了500毫秒,在网络层面是由于建连导致的时延问题?还是协议栈时延?其实在应用层并不清楚,只知道最终这个请求消耗了500毫秒。
第二个方面:网络层的信息能提供更精确的数据。以Nginx日志为例,当一个请求所发送的数据已在内核缓冲区里,Nginx认为已经实现了请求的完整回复,而记录了一个时延。但是如果能从网络流量的角度去监测,会发现在实际的环境中对于这样的场景会有3~10倍时延的误差。这说明,从网络层面去分析应用的质量、性能是必要的。
为了实现整个业务的监控,需要在容器网络环境获取到的数据,包括Service之间访问的追踪关系;负载均衡、Service前后IP的变化关系;真实源IP与SNAT和DNAT后的变化关系。
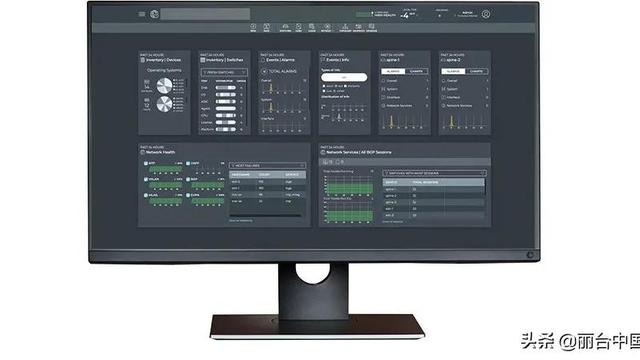
通过这些数据来刻画监控数据的分布,以及监控数据和网络逻辑拓扑的关联,构建网络知识图谱,实现各个纬度的可视化;同时对历史的交互数据进行回溯分析,在不同的维度(资源组维度、POD维度、服务维度)做层层的钻取来最终定位业务的性能问题,并进行证据的留存。目前国内已有不少企业通过自己的产品赋能容器网络性能监控,例如云杉网络DeepFlow虚拟网络流量采集、可视化与监控平台,基于高效的混合云流量全网采集和时序数据存储、检索技术,提供混合云网络流量采集与分发和性能监控诊断解决方案。