MySQL的自增id会用完吗?用完怎么办
MySQL作为最常用的关系型数据库,无论是在应用还是在面试中都是必须掌握的技能。

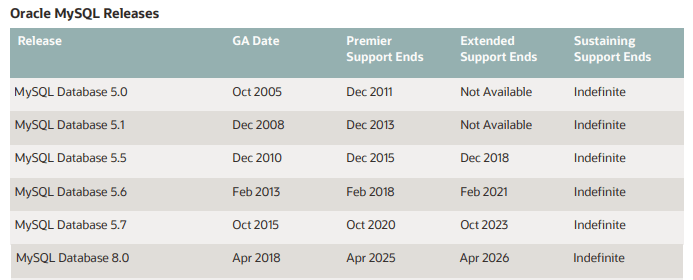
一、MySQL自增主键会用完吗
我们在使用MySQL设置的自增主键的时候,一般都是定义初始值和定义步长,我们知道自然数是没有上限的,但是MySQL的自增主键是会设置字节长度的,但凡有字节长度那么就会有上限。
二、MySQL自增主键用完会怎样
不管我们设置字节长度为多大,如果假设MySQL运行时间足够长,那么就一定会用完,对于MySQL的情况会分为两种:
1.程序员自己设置的自增主键。
毫无疑问,当数值达到最大时候,再去获取自增主键得到的依然是最大值,插入的时候就会报主键冲突。这个是在server层实现的。
2.程序员没有设置自增主键,mysql自动创建row_id。
这里需要注意,MySQL中的row_id是在引擎层实现的,InnoDB代码中会创建一个不可见的长度为8的自增字段row_id,步长为1,但是InnoDB在实现的时候却只给此字段分配6个字节的空间长度,因此在保存数据的时候只能取row_id字段的最后6字节进行保存,我们知道6字节数值最大为2的248次方,如果已经达到这个值后,再次插入数据时候,row_id就是2的248次方加1,从这个数值中取最后6字节正好是0,而在InnoDB的实现逻辑中如果row_id重复,不会报主键冲突,而是会覆盖原数据。
现在你应该清楚mysql的自增主键是有上限的,达到上限后就会出现上面说的现象。
三、mysql中还有哪些自增id,达到最大又会如何呢
1.max_trx_id
我们知道MySQL中,没创建一个事物就会去申请一个事物id(trx_id),申请的方式就是从获取全局变量max_trx_id当前值,然后将max_trx_id+1,max_trx_id是InnoDB内部维护的,并且是持久化保存的,也就是说即便MySQL重启也不会重置这个值。
一般的select语句是不会申请事物id的,除非语句后面加上for update。
max_trx_id也是8个字节的长度,虽然数字足够大,但是假设mysql运行时间足够长,早晚也会达到最大值的,max_trx_id达到最大值后会重置为0,重新开始。
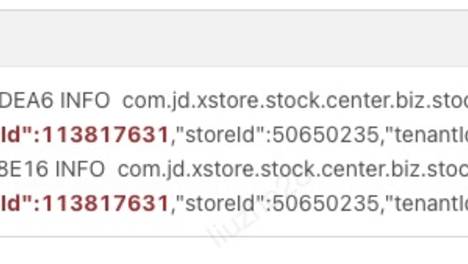
这种情况下就会有个问题,看下图:

我们知道在可重复读隔离级别下数据的可见性是通过事物的一致性视图来判断的。这种情况下就会出现脏读的bug。
解释:
假设在上面sql执行前系统的max_trx_id已经是最大值999(假设这是最大值),所以在session A启动的事务的低水位就是999。
在T2时刻,session B执行第一条update语句的事务id就是999,而第二条update语句的事务id就是0了,这条update语句执行后生成的数据版本上的trx_id就是0。
在T3时刻,session A执行select语句的时候,判断可见性发现,c=3这个数据版本的trx_id,小于sessionA的事务低水位,因此认为这个数据可见。
但实际sessionA不应该看到c=3这条数据,因此出现这个是脏读。
这是MySQL必现的一个bug。
2.thread_id
thread_id是MySQL中常见的一种自增id,长度为4个字节,当达到最大值时就会重置为0,重新开始,但是我们在日常的维护中用show processlist查看的时候从来都不会看到重复的id,这是因为MySQL在实现的时候做了一些操作,代码如下:
do {
new_id= thread_id_counter++;
} while (!thread_ids.insert_unique(new_id).second);
因此MySQL中的thread_id不会出现重复。
mysql中还有一些其他的自增id,比如mysql中还有redo log和binlog相关的xid,binlog文件序号,还有table_id等。但是我们最应该知道就是上面这几个,其他的感兴趣可以随时来找我探讨。