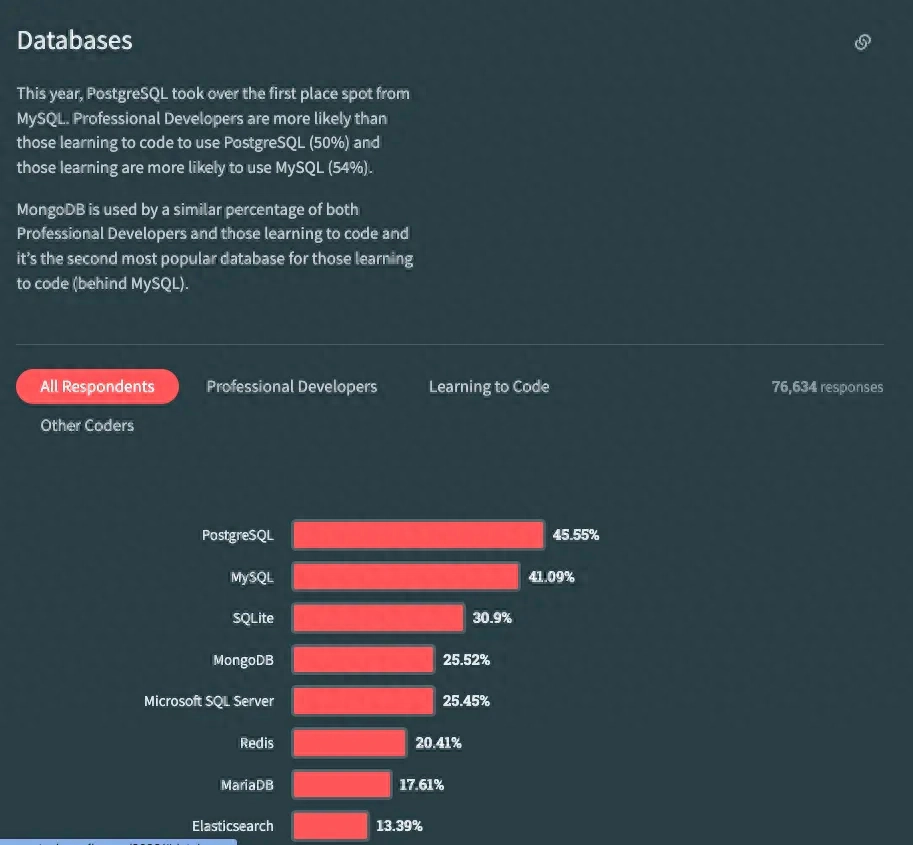
深入浅出MySQL MRR(Multi-Range Read)
在探索数据库优化的广阔领域中,我们不可避免地会遇到一系列独特的概念和技术。其中之一就是MySQL的多范围读取(Multi-Range Read, MRR)。
这种技术为我们提供了在处理大量数据时提高查询效率的强大手段。它通过改变数据检索的顺序,并利用操作系统缓存进行预读,从而显著减少I/O操作数量,提高查询速度。本文将深入探讨MRR的内部工作原理,以及如何在日常数据库管理中有效地应用这种技术。
什么是MRR
MRR 是优化器将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销的一种手段。
了解MRR之前,我们先来了解下「回表」。
回表是MySQL在执行查询时的一个步骤,它通常发生在使用索引进行搜索之后。当MySQL在索引中找到了需要的数据,但这些数据并不完全满足查询需求时(比如,索引没有包含所有需要的列),MySQL就需要回到主表中去获取完整的行数据,这个过程就被称为"回表"。
举例来说,如果查询语句中有一些列没有被包含在索引中,那么即使从索引中能查到部分信息,也还需要回到原始表中获取其他列的信息,这就是所谓的"回表"操作。为了提高查询效率,我们可以尽量减少回表操作,例如通过使用「覆盖索引(Covering Index)」。
我们知道二级索引是有回表的过程的,由于二级索引上引用的主键值不一定是有序的,因此就有可能造成大量的随机 IO,如果回表前把主键值在内存中给它排一下序,那么在回表的时候就可以用顺序 IO 取代原本的随机 IO。
在没有MRR的情况下,MySQL会按照索引顺序来访问行数据,而索引顺序并不一定与磁盘上的物理存储顺序一致,这就可能产生大量的随机磁盘I/O。
当启用MRR后,MySQL会先按照索引扫描记录,但并不立即去获取行数据,而是将每个需要访问的行位置(例如主键)保存到一个缓冲区中。
然后,MySQL会根据这些行位置,按照物理存储的顺序(通常也就是主键顺序)去获取行数据。这样就能避免大量的随机I/O,因为数据现在是按照它们在磁盘上的物理存储顺序被访问的。
比如,当我执行这个语句时:
select * from t1 where a>=1 and a<=100;
主键索引是一棵B+树,在这棵树上,每次只能根据一个主键id查到一行数据。因此,回表肯定是一行行搜索主键索引的,基本流程如图所示。
如果随着a的值递增顺序查询的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差。虽然“按行查”这个机制不能改,但是调整查询的顺序,还是能够加速的。
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
这,就是MRR优化的设计思路。此时,语句的执行流程变成了这样:
-
根据索引a,定位到满足条件的记录,将id值放入
read_rnd_buffer中。 -
将read_rnd_buffer中的id进行递增排序。
-
排序后的id数组,依次到主键id索引中查记录,并作为结果返回。
这里,read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。
如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环。
下面两幅图就是使用了MRR优化后的执行流程和explAIn结果。

从explain结果中,我们可以看到Extra字段多了「Using MRR」,表示的是用上了MRR优化。而且,由于我们在read_rnd_buffer中按照id做了排序,所以最后得到的结果集也是按照主键id递增顺序的,也就是与图1结果集中行的顺序相反。
MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询(也就是说,这是一个多值查询),可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出“顺序性”的优势。
简单来说:MRR 的核心思想就是通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
顺序读带来了两个好处:
-
磁盘和磁头不再需要来回做机械运动。
-
可以充分利用磁盘预读。
所谓的磁盘预读,比如说在客户端请求一页的数据时,可以把后面几页的数据也一起返回,放到数据缓冲池中,这样如果下次刚好需要下一页的数据,就不再需要到磁盘读取。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
MRR 在本质上是一种用「空间换时间」的做法。
MySQL 不可能给你无限的内存来进行排序,这块内存的大小就由参数read_rnd_buffer_size来控制,如果read_rnd_buffer满了,就会先把满了的 rowid 排好序去磁盘读取,接着清空,然后再往里面继续放 rowid,直到 read_rnd_buffer 又达到 read_rnd_buffe 配置的上限,如此循环。
MRR如何使用
MRR相关参数如下:
//如果你不打开,是一定不会用到 MRR 的。
set optimizer_switch='mrr=on';
set optimizer_switch ='mrr_cost_based=off';
set read_rnd_buffer_size = 32 * 1024 * 1024;
mrr_cost_based: on/off,则是用来告诉优化器,要不要基于使用 MRR 的成本,考虑使用 MRR 是否值得(cost-based choice),来决定具体的 SQL 语句里要不要使用 MRR。
很明显,对于只返回一行数据的查询,是没有必要 MRR 的,而如果你把 mrr_cost_based 设为 off,那优化器就会通通使用 MRR,这在有些情况下是很 stupid 的,所以建议这个配置还是设为 on,毕竟优化器在绝大多数情况下都是正确的。
通过本文我们可以了解到,MySQL的多范围读取(MRR)优化提供了一个高效的方式来处理和加速查询性能。特别是在处理大量数据、联接操作或者需要处理大量行的复杂查询时,MRR都会展现出其强大的优势。
然而,我们也要注意到,不是所有情况下启用MRR都会提升性能,一些具体的场景可能会产生额外的磁盘I/O开销。因此,理解其工作原理并合适地运用在恰当的场景,才是有效使用这个优化策略的关键。