题目是一个典型 《Effective C++》 的风格。
事情是这样的,我大致说一下。
我在开发一个Netfilter模块,在PREROUTING匹配一些数据包,显而易见,都能想到使用哈希表hlist作为数据结构的容器,其中装有下面的结构体:
struct item { struct hlist_node hnode; char padding[16];};
生成item的时候,我先用 kmalloc 接口分配内存:
item_nd = (struct item *)kmalloc(sizeof(struct item), GFP_KERNEL);
然后我用hlist_add/del接口将分配好的结构体插入到hlist中。
仅仅为了测试是否会宕机,所以我的所有的数据结构的hash值均是一样的,这样插入200个项的话,它们会hash冲突,从而仅仅添加到同一个hlist链表中,这样整个匹配过程就退化成了遍历200个项的链表。
虽然是万恶的遍历操作,但200个项一切还OK,性能几乎是无损的,无论是吞吐,还是pps。
这个时候,我想扩充一些功能,于是乎为item结构体增加了一个字段:
struct item { struct hlist_node hnode; char padding[16]; void *private;};
仅仅增加了一个private,其它均和之前完全一致,同样的200个项插入同一条hlist,同样遍历,吞吐和pps下降达到15%~20%!
为什么增加了一个指针变量,就出现了如此巨大的性能差异?!
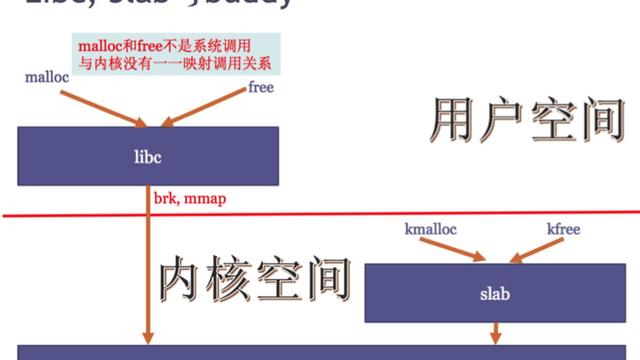
事情的端倪就隐藏在kmalloc接口中!
事情的真相是,在不添加private指针时,item结构的大小是32,添加一个指针,其大小变成了40,别小看这8个字节:
为什么会造成这个结果?32和40有什么特殊性吗?
我们还要继续向下看。
kmalloc的背后其实是一系列的kmem_cache:
我们从/proc/slabinfo里可以一窥究竟:
[root@localhost test]# cat /proc/slabinfo |grep ^kmallockmalloc-8192 52 52 8192 4 8 : tunables 0 0 0 : slabdata 13 13 0kmalloc-4096 274 288 4096 8 8 : tunables 0 0 0 : slabdata 36 36 0kmalloc-2048 578 608 2048 16 8 : tunables 0 0 0 : slabdata 38 38 0kmalloc-1024 1105 1120 1024 16 4 : tunables 0 0 0 : slabdata 70 70 0kmalloc-512 1466 1584 512 16 2 : tunables 0 0 0 : slabdata 99 99 0kmalloc-256 2289 2560 256 16 1 : tunables 0 0 0 : slabdata 160 160 0kmalloc-192 1630 1785 192 21 1 : tunables 0 0 0 : slabdata 85 85 0kmalloc-128 1632 1632 128 32 1 : tunables 0 0 0 : slabdata 51 51 0kmalloc-96 1344 1344 96 42 1 : tunables 0 0 0 : slabdata 32 32 0kmalloc-64 25408 25408 64 64 1 : tunables 0 0 0 : slabdata 397 397 0kmalloc-32 3072 3072 32 128 1 : tunables 0 0 0 : slabdata 24 24 0kmalloc-16 3072 3072 16 256 1 : tunables 0 0 0 : slabdata 12 12 0kmalloc-8 5120 5120 8 512 1 : tunables 0 0 0 : slabdata 10 10 0
当你调用 kmalloc(size, flags) 申请内存时,系统会根据你的size向上寻找一个最接近的kmem_cache,然后在其中为你分配所需的内存。
我们知道kmemcache是针对特定数据结构的独享内存池子,它以 *最小化碎片* 的原则为特定的场合提供 *可高效访问* 的内存,比如sock,skbuff这些。
然而kmalloc接口所依托的kmem_cache则是全局(同一个NUMA node)共享的内存池子,它并不针对特定场合,仅仅针对特定大小!也即是说, 最小化碎片 是针对所有调用kmalloc接口的线程的。
我们回头看上面的slabinfo,可以注意到,64字节大小的kmem_cache,即kmalloc-64已经包含了非常多的object,因此如果你调用kmalloc申请40字节的内存,其实你是在kmalloc-64里分配。
其实32和40没有什么特殊性,32字节大小的item之所以还可以保持连续,那是因为kmalloc-32几乎没有被重度使用,而kmalloc-64则已经被其它使用者打散。
我们可以试一下,看看分别申请32字节和40字节的效果:
#include <linux/module.h>struct stub32 { unsigned char m[32];};struct stub40 { unsigned char m[40];};#define SIZE 20struct stub32 *array32[SIZE] = {NULL};struct stub40 *array40[SIZE] = {NULL};%}function alloc_test()%{ int i; for (i = 0; i < SIZE; i ++) { array32[i] = kmalloc(sizeof(struct stub32), GFP_KERNEL); printk("32bytes [%d]:%p ", i, array32[i]); if (i > 0) { unsigned long hi = (unsigned long)array32[i]; unsigned long lo = (unsigned long)array32[i - 1]; signed long delta = hi - lo; if (delta < 0) delta = lo - hi; printk("delta [%lx] n", delta); } else printk("delta [0] n"); } printk("------------------n"); for (i = 0; i < SIZE; i ++) { array40[i] = kmalloc(sizeof(struct stub40), GFP_KERNEL); printk("40bytes [%d]:%p ", i, array40[i]); if (i > 0) { unsigned long hi = (unsigned long)array40[i]; unsigned long lo = (unsigned long)array40[i - 1]; signed long delta = hi - lo; if (delta < 0) delta = lo - hi; printk("delta [%lx] n", delta); } else printk("delta [0] n"); } for (i = 0; i < SIZE; i ++) { kfree(array32[i]); kfree(array40[i]); }%}probe begin{ alloc_test(); exit(); // oneshot模式}
以下是结果:
[ 466.933100] 32bytes [1]:ffff881f9649caa0 delta [20][ 466.938206] 32bytes [2]:ffff881f9649cac0 delta [20][ 466.943314] 32bytes [3]:ffff881f9649cae0 delta [20][ 466.948586] 32bytes [4]:ffff881f9649cb00 delta [20][ 466.953732] 32bytes [5]:ffff881f9649cb20 delta [20][ 466.958863] 32bytes [6]:ffff881f9649cb40 delta [20][ 466.963977] 32bytes [7]:ffff881f9649cb60 delta [20][ 466.969095] 32bytes [8]:ffff881f9649cb80 delta [20][ 466.974222] 32bytes [9]:ffff881f9649cba0 delta [20][ 466.979329] 32bytes [10]:ffff881f9649cbc0 delta [20][ 466.984731] 32bytes [11]:ffff881f9649cbe0 delta [20][ 466.990124] 32bytes [12]:ffff881f9649cc00 delta [20][ 466.995510] 32bytes [13]:ffff881f9649cc20 delta [20][ 467.000907] 32bytes [14]:ffff881f9649cc40 delta [20][ 467.006294] 32bytes [15]:ffff881f9649cc60 delta [20][ 467.011685] 32bytes [16]:ffff881f9649cc80 delta [20][ 467.017086] 32bytes [17]:ffff881f9649cca0 delta [20][ 467.022483] 32bytes [18]:ffff881f9649ccc0 delta [20][ 467.027881] 32bytes [19]:ffff881f9649cce0 delta [20][ 467.033286] ------------------[ 467.036610] 40bytes [0]:ffff881d0c904d40 delta [0][ 467.041828] 40bytes [1]:ffff881d0c904680 delta [6c0][ 467.047216] 40bytes [2]:ffff881d0c904140 delta [540][ 467.052607] 40bytes [3]:ffff881d0c904d00 delta [bc0][ 467.058001] 40bytes [4]:ffff881d0c9043c0 delta [940][ 467.063399] 40bytes [5]:ffff881d0c904940 delta [580][ 467.068801] 40bytes [6]:ffff881d0c9048c0 delta [80][ 467.074107] 40bytes [7]:ffff881d0c904e80 delta [5c0][ 467.079496] 40bytes [8]:ffff881d0c904200 delta [c80][ 467.084888] 40bytes [9]:ffff881d0c904980 delta [780][ 467.090282] 40bytes [10]:ffff881fcd725dc0 delta [2c0e21440][ 467.096280] 40bytes [11]:ffff881fcd7250c0 delta [d00][ 467.101763] 40bytes [12]:ffff881fcd725440 delta [380][ 467.107235] 40bytes [13]:ffff881fcd725340 delta [100][ 467.112722] 40bytes [14]:ffff881f8398ee80 delta [49d964c0][ 467.118633] 40bytes [15]:ffff881f8398ecc0 delta [1c0][ 467.124110] 40bytes [16]:ffff881f8398e100 delta [bc0][ 467.129589] 40bytes [17]:ffff881f8398ed40 delta [c40][ 467.135062] 40bytes [18]:ffff881f8398efc0 delta [280][ 467.140542] 40bytes [19]:ffff881f8398e700 delta [8c0]
我们可以看到,32字节的结构体,kmalloc分配的完全都是连续的,而40字节的结构体,完全就散乱碎片化了。
如果以上的这些地址是需要在网络协议栈的Netfilter hook中被遍历的,可想而知,如果地址非连续且布局无迹可寻,cache miss将会非常高。
值得一提的是,并不是说32字节的结构体分配就一定会获得连续的内存,而64字节的就不会, 这完全取决于你的系统当前的整体kmalloc使用情况。
kmalloc并不适合快速路径的内存分配,它只适合稳定的,离散的管理结构体的内存分配。
大家之所以普遍喜欢用kmalloc,因为它简单,快捷,少了kmem_cache的create和destroy的维护操作。
kmalloc有个副作用,就是它只有固定的大小,比如你分配一个24字节大小的结构体,事实上系统会给你32字节。具体的细节就参考kmalloc的kmem_cache数组吧。
在诸如网络协议栈处理这种相对快速的路径中,比如skbuff,sock,nfconntrack等结构体均是在自行维护的独享kmem_cache中被管理的,这保证了内存分配的 尽可能的连续性,尽可能的最少碎片。
这是通过kmem_cache的 栈式管理 实现的:
我再用例子给出直观的效果,依然采用专家模式的stap:
// alloc_free.stp%{#include <linux/module.h>struct stub { unsigned char m[40];};%}function kmemcache_stack_test()%{ int i; struct kmem_cache *memcache; struct stub *array[10]; struct stub *new[10] = {NULL}; memcache = kmem_cache_create("test_", sizeof(struct stub), 0, 0, NULL); if (!memcache) return; for (i = 0; i < 10; i ++) { array[i] = kmem_cache_alloc(memcache, GFP_KERNEL); STAP_PRINTF("[%d]:%llx n", i, array[i]); } STAP_PRINTF("Let's playn"); kmem_cache_free(memcache, array[4]); STAP_PRINTF("free [4]:%llx n", array[4]); array[4] = NULL; new[0] = kmem_cache_alloc(memcache, GFP_KERNEL); STAP_PRINTF("new [x]:%llx n", new[0]); kmem_cache_free(memcache, array[1]); STAP_PRINTF("free [1]:%llx n", array[1]); array[1] = NULL; kmem_cache_free(memcache, array[8]); STAP_PRINTF("free [8]:%llx n", array[8]); array[8] = NULL; new[1] = kmem_cache_alloc(memcache, GFP_KERNEL); STAP_PRINTF("new [x]:%llx n", new[1]); new[2] = kmem_cache_alloc(memcache, GFP_KERNEL); STAP_PRINTF("new [x]:%llx n", new[2]); for (i = 0; i < 10; i++) { if (new[i]) { kmem_cache_free(memcache, new[i]); new[i] = NULL; } } STAP_PRINTF("Batch freen"); for (i = 0; i < 10; i++) { if (array[i]) { kmem_cache_free(memcache, array[i]); STAP_PRINTF("free [i]:%llx n", array[i]); array[i] = NULL; } } STAP_PRINTF("Batch allocn"); for (i = 0; i < 10; i++) { new[i] = kmem_cache_alloc(memcache, GFP_KERNEL); STAP_PRINTF("new [%d]:%llx n", i, new[i]); } for (i = 0; i < 10; i++) { if (new[i]) { kmem_cache_free(memcache, new[i]); new[i] = NULL; } } kmem_cache_destroy(memcache);%}probe begin{ kmemcache_stack_test(); exit(); // oneshot模式}
很简单的实验,就是分配,释放的操作,我们运行一下:
[root@localhost test]# stap -g ./alloc_free.stp[0]:ffff88003bc4bf28[1]:ffff88003bc4bf00[2]:ffff88003bc4beb0[3]:ffff88003bc4be38[4]:ffff88003bc4be88[5]:ffff88003bc4be60[6]:ffff88003bc4bdc0[7]:ffff88003bc4be10[8]:ffff88003bc4bde8[9]:ffff88003bc4bd48Let's playfree [4]:ffff88003bc4be88new [x]:ffff88003bc4be88free [1]:ffff88003bc4bf00free [8]:ffff88003bc4bde8new [x]:ffff88003bc4bde8new [x]:ffff88003bc4bf00Batch freefree [i]:ffff88003bc4bf28free [i]:ffff88003bc4beb0free [i]:ffff88003bc4be38free [i]:ffff88003bc4be60free [i]:ffff88003bc4bdc0free [i]:ffff88003bc4be10free [i]:ffff88003bc4bd48Batch allocnew [0]:ffff88003bc4bd48new [1]:ffff88003bc4be10new [2]:ffff88003bc4bdc0new [3]:ffff88003bc4be60new [4]:ffff88003bc4be38new [5]:ffff88003bc4beb0new [6]:ffff88003bc4bf28new [7]:ffff88003bc4bf00new [8]:ffff88003bc4bde8new [9]:ffff88003bc4be88[root@localhost test]#
从地址上可以看出, kmem_cache就是按照一个栈的形式进行管理的,即便由于随机的free操作造成了空洞,后续的alloc会尽快将其填充。 这样的结果如下:
即便我们使用自行维护的kmem_cache slab,当从中分配的对象插入链表时,也要尽量按照其内存地址的升序插入链表确定的位置,这样在遍历链表时可以达到最大化预取的效果。实测过程这里从略。
一个事实是:
这是因为CPU在访问内存地址P时,会把一个cacheline的数据预取到cache,在连续的内存上,随着遍历的进行,链表项的访问和预取将形成一个流水化作业,这个流水线只要不被打断,遍历就好像在cache中进行一样。
我建议,根据slab对象的内存使用hlistaddbefore[rcu],hlistaddbebind[rcu]将对象插入hlist的特定位置,而不是简单使用hlistaddhead。