Linux性能优化之CPU

说明:文章有点长,CPU性能主要观测点的理论知识搬砖堆砌得较多,主要是为了大家对CPU性能主要观测点有深入理解,这样才能在性能调优和排错的过程中把握方向,希望你能耐心读完。当然,如果你理论基础扎实也可以跳过。
CPU物理信息
讲一个很久以前的笑话,一个老板让员工买几台服务器准备玩玩虚拟化,服务器买回来之后,安装VMware时却发现CPU不支持虚拟化,把老板气的指着那位员工鼻子骂。讲这个笑话的目的是想让大家知道了解服务器硬件特性的重要性。同一时期的市场上,一台几千元的服务器和一台几万元的服务器相比较,它们的性能肯定是不一样的。观察CPU性能,首先要关注的是一台服务器上有几个物理CPU,每个物理CPU有几个核,每个核有几个线程数。CPU逻辑核数通常是衡量服务器或虚拟机性能的重要指标。
- 查看CPU物理汇总信息
执行lscpu命令可以查看CPU物理汇总信息,CPU逻辑核数计算公式如下:
CPU(s)=Socket(s) X Core(s) per socket X Thread(s) per core
CPU(s): 总的逻辑CPU数或线程数
On-line CPU(s) list: 在线的各个逻辑CPU编号
Thread(s) per core: CPU每核的线程数
Core(s) per socket: 每个物理CPU核数
Socket(s): 物理CPU占用的槽位数,有几个表示有几颗物理CPU
[root@linuxabc ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 61
Model name: Intel(R) Core(TM) i7-5600U CPU @ 2.60GHz
Stepping: 4
CPU MHz: 2593.997
BogoMIPS: 5187.99
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 4096K
NUMA node0 CPU(s): 0-3
Flags: fpu vme de pse tsc ...
- 查看CPU逻辑核数
判断服务器的系统负载是否正常,需要参考CPU的逻辑核数,不能简单地认为只要系统负载的数值大于1就是系统负载高。
在线的CPU逻辑核数:
[root@linuxabc ~]# nproc
4
CPU逻辑核数:
[root@linuxabc ~]# nproc --all
4
- 查看CPU详细信息
下面两个命令可以查看CPU的详细信息,没有把命令执行结果粘贴出来是因为命令输出内容太多。dmidecode命令大家肯定不会陌生,不加任何参数将会显示服务器的所有硬件信息,我们通常用这个命令来查看服务器的具体型号和序列号,通过序列号可以在服务器厂家的官网查看是否在保。
[root@linuxabc ~]# cat /proc/cpuinfo
[root@linuxabc ~]# dmidecode -t processor
CPU性能主要观测点

运行队列统计
一个进程要么是可运行的,要么是阻塞的(正在等待一个事件的完成)。阻塞进程可能正在等待I/O设备的数据,或者是系统调用的结果。如果进程是可运行的,那就意味着它要和其它也是可运行的进程竞争CPU时间。一个可运行的进程不一定会使用CPU,但是当Linux进程调度器决定下一个要运行的进程时,它会从可运行进程队列中挑选。如果进程是可运行的,同时又在等待使用处理器,这些进程就构成了运行队列,运行队列越长,处于等待状态的进程就越多。

性能工具通常会给出可运行的进程个数和等待I/O的阻塞进程个数。另一种常见的系统统计是平均负载,系统的负载是指正在运行的和可运行的进程总数。比如,如果正在运行的进程为1个,而可运行的进程为2个,那么系统负载就是3,平均负载是给定时间内的负载量。Linux系统取平均负载时间为1分钟,5分钟和15分钟。从而观察到负载是如何随时间变化。
上下文切换

Linux是一个多任务操作系统,它支持远大于CPU数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。在每个任务运行前,CPU都需要知道任务从哪里加载,又从哪里开始运行,也就是说需要系统事先帮它设置好CPU寄存器和程序计数器(Program Counter, PC)。CPU寄存器是CPU内置的容量小,但速度极快的内存。而程序计数器,则是用来存储CPU正在执行的指令位置,或者即将执行的下一条指令位置。它们都是CPU在执行任何任务前必须得依赖环境,因此也被叫做CPU上下文。而这些保存下来的上下文,会存储在内核空间中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
根据任务的不同,CPU的上下文切换可以可分为三种不同的场景:
(1)进程上下文切换
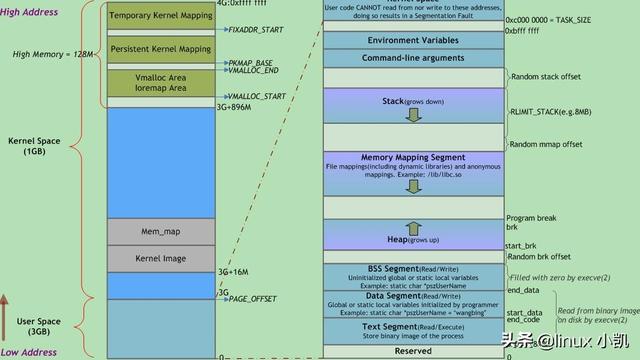
Linux系统按照特权等级,把进程的运行空间分为内核空间和用户空间,如下图所示:
内核空间(Ring 0)具有最高权限,可以直接访问所有资源。
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用访问内核空间,才能访问这些特权资源。

换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入到内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
系统调用的过程有没有发生CPU上下文的切换呢?答案自然是肯定的。
CPU寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU寄存器需要恢复原来用户保存的状态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次CPU 上下文切换。不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的。
进程上下文切换,是指从一个进程切换到另一个进程运行,而系统调用过程中一直是在同一个进程中在运行。所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。那么,进程上下文切换跟系统调用又有什么区别呢?
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。因此,进程的上下文切换就比系统调用时多了一步,在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来,而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在CPU 上运行才能完成。

根据测试报告,每次上下文切换都需要几十纳秒到数微秒的CPU时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致CPU将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正进程运行的时间。这也是导致平均负载升高的一个重要因素。在什么时候进程上下文会进行切换呢?
进程切换时(或者说进程调度时)才需要切换上下文,系统为每个CPU都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU的进程)按照优先级和等待CPU的时间排序,然后选择最需要CPU的进程,也就是优先级最高和等待CPU时间最长的进程来运行。
进程在什么时候才会被调度到CPU上运行呢?最容易想到的一个时机,就是当进程执行完终止了,它之前使用的CPU会释放出来,这个时候再从就绪队列里,取一个新的进程过来运行。其实还有很多其它场景,也会触发进程调度。
场景一,为了保证所有进程可以得到公平调度,CPU时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待CPU的进程运行。
场景二,进程在系统资源不足,比如内存不足时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
场景三,当进程通过睡眠函数sleep这样的方法将自己主动挂起时,自然也会重新调度。
场景四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
最后一个,发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。
了解这几个场景是非常有必要的,因为一旦出现上下文切换的性能问题,它们就是幕后凶手。
(2)线程上下文切换
线程与进程最大的区别在于线程是调度的基本单位,而进程则是资源拥有的基本单位。所谓内核中的任务调度,实际上的调度对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。所以对于线程和进程,我们可以这么理解:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程的上下文切换可以分为两种情况:
情况一, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
情况二,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,这正是多线程代替多进程的优势之一。
(3)中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快地执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗CPU,切换次数过多也会耗费大量的CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
为了保证公平地给每个进程分配处理器时间,内核周期性地中断正在运行的进程,在适当的情况下,内核调度器会决定开始另一个进程,而不是让当前进程继续执行。每次这种周期性中断或决定发生时,系统都可能进行上下文切换。每秒定时中断的次数和物理架构和内核版本有关。一个检查中断频率的简单方法是查看/proc/interrupts文件,它可以确定已知时长内发生的中断次数。
中断
中断是指由于CPU接收到外围硬件(相对于CPU与内存而言)的异步信号或者来自软件的同步信号而进行相应的硬/软件处理。

硬中断:外围硬件发给CPU或者内存的异步信号就是硬中断信号。简言之,外设对CPU的中断。
软中断:由软件本身发给操作系统内核的中断信号,称之为软中断。通常是由硬中断处理程序或进程调度程序对操作系统内核的中断,也就是我们常说的系统调用。
硬中断与软中断之区别与联系:
硬中断是有外设硬件发出的,需要有中断控制器参与。其过程是外设侦测到变化,告知中断控制器,中断控制器通过CPU或内存的中断脚通知CPU,然后硬件进行程序计数器及堆栈寄存器之现场保存工作,这会引发上下文切换,并根据中断向量调用硬中断处理程序进行中断处理。
软中断则通常是由硬中断处理程序或者进程调度程序等软件程序发出的中断信号,无需中断控制器参与,直接以一个CPU指令形式指示CPU进行程序计数器及堆栈寄存器现场保存工作,这会引发上下文切换,并调用相应的软中断处理程序进行中断处理,即我们通常所言之系统调用。
硬中断直接以硬件的方式引发,处理速度快。软中断以软件指令之方式适合于对响应速度要求不是特别严格的场景。
硬中断通过设置CPU的屏蔽位可进行屏蔽,软中断则由于是指令方式给出,不能屏蔽。
硬中断发生后,通常会在硬中断处理程序中调用一个软中断来进行后续工作的处理。
硬中断和软中断均会引起上下文切换(进程/线程之切换),进程切换的过程是差不多的。
CPU周期性地从硬件设备接收中断,当设备有事件需要内核处理时,就会触发中断。比如,如果磁盘控制器刚刚完成从驱动器取数据块的操作,并准备好提供给内核,那么磁盘控制器就会触发一个硬中断。对内核收到的每个中断,如果已经有响应的已注册的中断处理程序,就运行该程序,否则忽略这个中断。这些中断处理程序在系统中具有很高的运行优先级,并且通常执行速度也很快。有时,中断处理程序有工作要做,但是又不需要高优先级,因此它可以启动软中断处理程序。如果有很多中断,内核会花大量的事件服务这些中断。查看/proc/interrupts文件可以显示出哪些CPU上触发了哪些中断。
CPU使用率

CPU使用率是个简单的概念,在任何给定的时间,CPU可以执行以下八件事情中的一个:
CPU可以是空闲的,这意味着处理器实际上没有做任何工作,并且等待有任务可执行。
CPU可以运行用户代码,即指定的“用户”时间。
CPU可以执行Linux内核中的应用程序代码,这就是“系统”时间。
CPU可以执行”比较友好“的或者优先级被设置为低于一般进程的用户代码。
CPU可以处于I/O等待状态,即系统正在等待I/O(如磁盘或网络)完成。
CPU可以处于irq状态,即它正在用高优先级代码处理硬件中断。
CPU可以处于软irq模式,即系统正在执行同样由中断触发的内核代码,只不过其运行于较低优先级(下半部代码)。此情景出现的条件为:发生设备中断时,而内核在将其移交给用户空间之前必须对其进行一些处理(比如,处理网络包)。
管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
大多数性能工具将这些数值表示为占CPU总时间的百分比,这些时间的范围从0%到100%,但全部加起来等于100%。一个具有高“系统”百分百的系统表明其大部分时间都消耗在了内核上。像oprofile一样的工具可以帮助确定时间都消耗在了哪里。具有高“用户”时间的系统则将其大部分时间都用来运行应用程序。如果系统在应该工作的时候花费了大量的时间处于iowait状态,那它很可能在等待来自设备的I/O,导致速度变慢的原因可能是磁盘,网卡或其它设备。
CPU性能工具

选择使用系统性能工具时,通常会使用系统已经默认安装的工具,使用性能工具通常要注意以下几个方面:
第一:所选择的工具最好已经安装好。在管理比较规范的企业中,在产品环境对服务器的任何人为变动都是要计划一个时间窗口,准备好变动的步骤,并获得上级的批准,安装性能工具也不例外。
第二:所选择的工具占用系统开销要小。通常来说系统默认安装的性能工具所占用的系统开销都是比较小的,如果你使用了一个新的性能工具,一定要事先测试这个工具在运行时占用的系统资源开销情况,否则在产品环境使用,可能会因为这个工具占用的系统开销较大而导致系统资源更加紧张。
第三:对所选择的工具要非常熟悉。这样才能更好地分析系统性能,把工具的作用发挥到极致。
下面介绍的有些工具不仅仅可以观察CPU性能,有的还可以观察内存和磁盘I/O,本篇文章侧重点在CPU性能分析:
top(系统性能汇总)
top命令是查看系统性能时最常用的系统性能工具,它实时地显示当前系统性能汇总信息。从cpu性能来讲,top命令可以观察到以下几点:
第一:系统平均负载(Load Average)。
通过观察系统负载(1分钟/5分钟/15分钟)的平均值,可以判断系统负载是否正常,经过一定的时间观察之后,通过对比它们三个的平均值,可以大致判断系统负载的趋势。
第二:CPU使用率。
CPU使用率计算公式如下:
us+sy+ni+id+wa+hi+si+st=100%
us:用户态使用的cpu时间的百分比
sy:系统态使用的cpu时间的百分比
ni:用于nice操作,所占用 CPU 总时间的百分比
id:空闲的cpu时间比
wa:cpu等待磁盘写入完成时间
hi:硬中断消耗时间
si:软中断消耗时间
st:虚拟机偷取时间
通过观察上面各个选项的百分比,可以给我们指出排查CPU性能瓶颈问题的大致方向。如果wa比较高,通常意味着磁盘的读写性能问题。如果hi比较高,可能与系统硬中断有关,如果us比较高,应该是用户程序导致CPU性能问题。
系统负载和CPU使用率没有直接关系,系统负载高不一定CPU使用率高,反之,CPU使用率高不一定系统负载高。系统负载和进程运行队列相关,它是正在运行的和可运行的进程总数;CPU使用率是程序在运行期间实时占用CPU百分比。
系统负载理想值:在长期的生成实践中,大家以CPU的总逻辑核数(或线程数)和系统负载大小进行对比作为判断系统负载是否正常的依据,比如,一台服务器有4个逻辑核,如果系统负载小于4,通常情况下我们认为系统负载是正常的;如果系统负载大于4,系统可能存在潜在的性能问题。
CPU使用率理想值:如果CPU使用率长时间处在60% ~ 80%以上,通常可能存在系统性能瓶颈问题。在生产环境,可能由于业务流量的原因在某个时间段CPU使用率会升高,如果从监控系统发现峰值一直存在,且超过80%,就要考虑扩容了。
第三:占用CPU资源最高的进程。
当CPU使用率或平均负载达到警戒线而触发告警之后,系统管理员通常首先要做的是查找CPU使用率最高的进程,如果它是系统进程,可能就需要重启这个进程或进一步排查根本原因。如果是应用进程,就需要及时联系业务运维人员检查,在生产实践中,我们有时发现系统审计守护进程(auditd)和发送邮件守护进程(sendmail&postfix)运行异常导致系统负载较高,重启之后问题解决。
第四:占用CPU最高的线程。
当需要查看某个进程的每个线程的CPU使用率时,意味着需要更深层次地调查根本原因,通常是程序代码级别的原因。在给开发部门发邮件之前,我们需要提供充分的证据表明这是应用代码级别的问题。
top命令选项
-H 表示以线程方式显示
-p process ID 查看某个进程占用的系统资源状况,参数后面跟的时进程号
-u username 查看某个用户占用的系统资源状况,参数后面跟的时用户名
-i 不显示未使用任何CPU的进程
-d delay 统计数据更新的时间间隔
-n interations 退出前的迭代次数。
用法示例
示例一:top命令默认输出。
从top命令的默认输出结果,我们可以看到系统负载,CPU使用率和占用CPU最多的进程。
[root@linuxabc ~]# top

示例二:查看占用CPU最多的线程。
通过top命令的默认输出,我们可以找到占用CPU最多的进程,然后根据下面的命令查看某个进程中占用CPU最多的线程,下面的命令输出仅仅是命令示例,其实这个进程的线程本身占用CPU很低。
[root@linuxabc ~]# top -Hp 1351

mpstat(多处理器统计)
mpstat命令比较简单,它展示了随着时间变化的CPU使用率,如果你有多个CPU,mpstat还能够把CPU使用率按处理器进行区分,因此你可以发现与其它处理器对比,是否某个处理器的CPU使用率比较高,你也可以选择想要监控的单个CPU,也可以对所有的CPU进行监控。
运行mpstat命令可以帮助观察是否所有的CPU使用率是均匀的,如果只有其中一个CPU使用率比较高,通常意味着这是一个问题,我们需要进一步调查是那个进程或线程引起的。通过mpstat命令的各个选项输出,可以帮助我们确定排查的方向。
mpstat命令格式:
mpstat [-P { cpu | ALL ] [ delay { count } ]
命令选项 -P 可以指定对某个或全部CPU进行监控
dely指定了采样间隔
count指定了采样次数
mpstat性能统计信息:
cpu:处理器编号。关键字all表示统计数据是作为所有处理器之间的平均值计算的
%user:在用户级别(应用程序)执行时发生的CPU使用率百分比
%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比
%system:在系统级(内核)执行时发生的CPU使用率百分比。请注意这不包括硬件和软件中断所花费的时间
%iowait:CPU等待I/O所花费的时间百分比
%irq:CPU处理硬件中断所花费的时间百分比
%softirq:CPU因软件中断服务所花费的时间百分比
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比
%guest:CPU运行虚拟处理器所花费的时间百分比
%gnice:CPU运行“niced guest”所花费的时间百分比
%idle:CPU空闲且系统没有磁盘I/O请求的时间百分比
用法示例
示例一:显示每隔1秒钟刷新3次的所有CPU性能统计信息。
[root@linuxabc ~]# mpstat -P ALL 1 3

示例二:显示每隔1秒钟刷新5次的CPU编号为0的性能统计信息。
[root@linuxabc ~]# mpstat -P 0 1 5

vmstat(虚拟内存统计)
vmstat提供了一个低开销的良好系统性能视图。是在系统负载非常高的服务器上观察系统性能的好工具。vmstat有两种运行模式,分别是采样模式和平均模式,如果不指定参数,则vmstat统计工作于平均模式,vmstat显示从系统启动以来所有统计数据的均值。如果指定了延迟,第一个采样仍然是系统启动以来的均值,之后vmstat按延迟秒数采样系统并显示系统统计信息。
vmstat指的是虚拟内存统计,但它不仅能统计系统的虚拟内存性能信息,还能获取整个系统性能的总体信息,与CPU相关的包括:
正在运行的进程个数
CPU的使用情况
CPU接收中断次数
调度器执行的上下文切换次数
vmstat命令格式:
vmstat [ -n [ -s ] [ delay [ count ] ]
命令选项:
-n 默认情况下,vmstat定期显示每个性能统计数据的列标题。本选项禁止该特性,因此初始列标题之后,只显示性能数据。
-s 本选项一次性输出vmstat收集的系统统计的详细信息。该信息为系统启动后的总数据
delay 延迟秒数,采样的间隔时间
count 采样次数
CPU性能统计信息:
vmstat命令提供的各种统计输出信息,让我们能跟踪系统性能的不同方面,在这里只解释用CPU性能相关的输出。
r: 当前可运行的进程数。这些进程没有等待I/O,而是已经准备好运行。理想状态下,可运行的进程数应与可用CPU的数量相等。
b:等待I/O完成的被阻塞进程数。
forks:创建新进程的次数。
in: 系统发生中断的次数。
cs: 系统发生上下文切换的次数。
us: 用户进程消耗的总CPU时间的百分比(包括“nice"时间)
sy: 系统代码消耗的总CPU时间的百分比,其中包括消耗在系统,硬中断和软中断的时间。
wa: 等待I/O消耗的总CPU时间的百分比
id:系统空闲时间的总cpu时间的百分比
用法示例
示例一:vmstat默认输出。
如果vmstat运行时没有使用命令行参数,显示的将是自系统启动后它记录下的统计信息的均值。通过观察"CPU“列下面的us,sy,sa和id对应的值,可以判断CPU的工作状态,下面的示例告诉我们CPU基本处于空闲状态。
[root@linuxabc ~]# vmstat

示例二:vmstat工作于采样模式。
vmstat是一个记录系统在一定负载或测试条件下行为的好工具,这样就能够用于查看系统对负载和各种系统事件是如何反应的。在下面的例子中,在in列和cs列能分别看到中断和上线文切换的次数。上下文切换的数量小于中断的数量。调度器切换进程的次数少于定时器中断触发的次数。这很可能是因为系统级别上是空闲的,在定时器中断触发的大多数时候,调度器没有任何工作要做,因此它不需要从空闲进程切换出去。
[root@linuxabc ~]# vmstat 1 10

示例三:一次性输出vmstat收集的系统统计的详细信息。
在下面的vmstat命令输出中,我们可以看到有一组和”CPU ticks“相关的统计数据,它显示了全部的CPU ticks的分布情况。”CPU ticks"显示的是自系统启动的cpu时间,这里的“tick"是一个时间单位。另外,我们还可以看到中断和上下文切换的总数,forks也值得我们注意,它表示的是从系统启动开始,已经创建的新进程的数量。
[root@linuxabc ~]# vmstat -s

sar(系统活动报告)
sar使用低开销的,记录系统执行情况信息的方法,r将收集到的系统性能数据记录到二进制文件。sar既可以显示当前系统的实时信息,也可以回访之前收集的历史信息。
sar能把不同类型的时间戳系统数据保存到日志文件,以便日后检索和审查。当试图找出特定服务器在特定时间出现故障的原因时,这个特性是sar最大的亮点。
sar命令格式:
sar [ options ] [ delay [ mount ] ]
命令选项:
-P { cpu | ALL }
-q 报告机器的运行队列长度和平均负载
-u 报告系统的CPU使用情况(该项为默认输出)
-w 报告系统发生的上下文切换次数
-o filename 指定保存性能统计信息的二进制输出文件名
-f filename 从指定性能统计信息的文件名读取信息
delay 需要等待的采样间隔时间
count 记录的样本总数
CPU性能统计信息:
CPU: all表示所有CPU
%user:显示在用户级别(Application)运行使用CPU总时间的百分比
%nice: 显示在用户级别,用于nice操作,所占用CPU总时间的百分比
%system:在核心级别(kernel)运行所使用CPU总时间的百分比
%iowait:显示用于等待I/O操作占用CPU总时间的百分比
%steal: 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU的百分比
%idle: 显示 CPU 空闲时间占用CPU总时间的百分比
用法示例
示例一:sar命令默认输出历史的CPU性能统计信息。
[root@linuxabc ~]# sar

示例二:每隔1秒进行10次实时CPU性能采样。
[root@linuxabc ~]# sar 1 10

示例三:查看CPU实时运行队列长度,上下文切换和平均负载。
下面的命令每隔1秒进行2次实时CPU性能采样,可以看到每秒钟的上下文切换数,创建的进程数和系统负载。从最后的平均负载来看有290个进程在内存中,但是没有在CPU中运行,也没有等待运行的进程。
[root@linuxabc ~]# sar -w -q 1 2

------ END ------