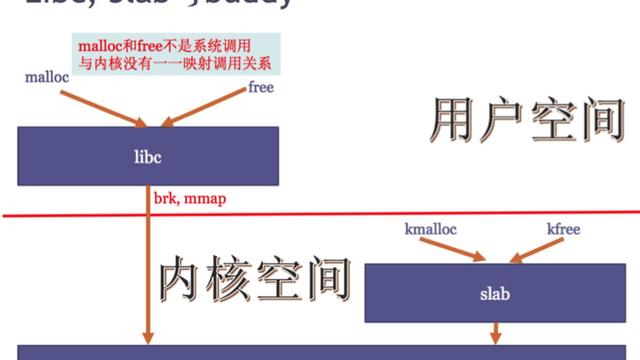
登录到一台有性能问题的机器,第一步做什么?针对于面对性能问题无从下手,本文介绍性能查找方法论和快速定位问题的 10 个命令。
USE(Utilization Saturation and Errors)方法可以分析任何系统性能问题。它的思想就是根据一个 checklist, 一一核对,快速找到系统的错误和资源瓶颈。它旨在性能优化早期发现系统问题。这些需要被检查资源包括:
检查每一个资源时,首先查看是否有错误产生,因为出现错误概率最大,其次是错误很容易被观察到,不管是我们的软件系统还是操作系统对错误都会有日志记录。其次是使用率,如果使用率是 100%,那么一定是资源瓶颈,如果是 70%,这可能存在资源瓶颈问题。最后是饱和度,通常是一些排队队列的长度,如任务调度队列长度,网络发送队列长度。通过检查资源的出错情况,使用率,饱和度往往能快速定位问题。值得注意的是,系统性能问题可能有多个原因。在着手性能分析第一步建议你使用以下 10 个命令来了解机器的使用情况,从一个比较高的层次去观察机器。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
IOStat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
$ uptime 23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
uptime 命令帮助你快速查看系统的平均负载。敲下这个命令后分别显示当前时间,系统启动时间,用户数,1 分钟 5 分钟 15 分钟内系统平均负载。平均负载可以理解成系统可运行的进程平均数。使用 3 个不同的时间粒度来帮助你分析系统负载的趋势,例如判断系统的是不是越来越大,还是已经错过了高峰。本例中,15 分钟, 5 分钟,1 分钟系统的平均负载越来越大,说明系统的负载越来越大 。
$ dmesg | tail
[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0
[...]
[1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child
[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-rss:0kB
[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP counters.
使用这条命令来查看最近的 10 条系统消息,你可以看看是否有错误产生,如上面这个例子出现了 out of memory 和 Dropping request 。如果 10 条内容不够可以使用 grep 进行搜索 或者使用 -n 参数查看更多。
$ vmstat 1
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0
32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0
32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0
32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0
32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
^C
vmstat 是 Virtual Meomory Statistics(虚拟内存统计)的缩写,这条命令可对操作系统的虚拟内存、进程、CPU 活动进行监控。以参数 1 运行 ,1 秒钟打印一次。参数说明如下
r:当前运行队列中线程的数目,r 值过大说明线程过多,就可能会出现 CPU 瓶颈了;
b:等待 I/O 的进程数量;如果该值一直都很大,说明 I/O 比较繁忙,处理较慢;
swpd:虚拟内存已使用的大小
free:空闲的物理内存的大小;
buff:用作缓冲的内存大小,这里指的是对磁盘的缓冲;
cache:用作缓存的内存大小;如果指的是文件系统的page cache
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
bi:每秒读取的块数;
bo:每秒写入的块数;随机磁盘读写的时候,这 2 个值越大,能看到 CPU 在 I/O 等待的值(io_wait)也会越大;
in:每秒中断数,包括时钟中断;
cs:每秒上下文切换数;
us:用户进程执行时间(user time);
sy:系统进程执行时间(system time);
id:空闲时间(idle 时间);
wa:等待 I/O 时间;wa 的值高时,说明 I/O 等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈。
$ mpstat -P ALL 1
linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
这个命令显示每个 CPU 的工作时间明细,可用于检查不平衡情况。 如果单 CPU 过热,可能是单线程应用程序造成的。vmstat 只能看到整体 CPU 使用情况, 而 mpstat 可以看到每个的 CPU 使用情况。
参数 释义 从/proc/stat获得数据
CPU 处理器ID
%usr 用户态的 CPU 时间(%)
%nice nice 值为负进程的 CPU 时间(%)
%sys 内核态的 CPU 时间(%)
%iowait 硬盘 I/O 等待时间(%)
%irq 硬中断时间(%)
%soft 软中断时间(%)
%steal 显示虚拟机管理器在服务另一个虚拟处理器时虚拟CPU处在非自愿等待下花费时间的百分比
%guest 显示运行虚拟处理器时 CPU 花费时间的百分比
%gnice 显示 niced guest 占比
%idle CPU 空闲等待时间(idle)(%)
$ pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 JAVA
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
^C
pidstat 有点像单进程版的 top 命令。用来查看单个进程占用 CPU 的详细情况。
$ iostat -xz 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
[...]
^C
iostat 是了解块设备(磁盘)的工作负载以及所产生的性能的绝佳工具。参数释义如下所示
%user:CPU 处在用户模式下的时间百分比。%nice:用户空间下高优先级程序时间百分比。%system:CPU 处在内核态下的时间百分比。%iowait:CPU 等待输入输出完成时间的百分比。%steal:管理程序维护另一个虚拟处理器时,虚拟 CPU 的无意识等待时间百分比。%idle:CPU 空闲时间百分比。
$ free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 59 541
-/+ buffers/cache: 23944 222053
Swap: 0 0 0
free 命令用来查看内存使用情况。buffers 表示块设备(磁盘)使用的缓存,而 cached 表示文件系统的页缓存(page cache)
$ sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM Docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
sar 是 System Activity Reporter(系统活动情况报告)的缩写。sar 工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统取样,获得大量的取样数据;取样数据和分析的结果都可以存入文件,所需的负载很小。sar 是目前 Linux 上最为全面的系统性能分析工具之一,可以从 14 个大方面对系统的活动进行报告,包括文件的读写情况、系统调用的使用情况、串口、CPU 效率、内存使用状况、进程活动及 IPC 有关的活动等。
这里参数 DEV 是检测网络接口的吞吐:rxkB/s 和 txkB/s,作为收发数据负载的度量,也是检测是否达到收发极限。在上面这个例子中,eth0 接收数据达到 22 M 字节/秒,也就是 176 Mbit/秒(网卡的上限是 1 Gbit/秒)。这个版本的工具还有一个统计字段: %ifutil,用于统计设备利用率(全双工双向最大值)。
$ sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
^C
这是对 TCP 关键指标的统计,它包含了以下内容:
TCP 重传是网络或者服务器有问题的一个信号;可能是一个不可靠的网络(例如:公网),或者可能是因为服务器过载了开始丢包。上面这个例子可以看出是每秒新建一个 TCP 连接。
$ top
top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92
Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie
%Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers
KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java
4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave
66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top
5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java
4299 root 20 0 20.015G 2.682g 16836 S 0.3 1.1 33:14.42 java
1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0
8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
top 命令用来查看系统各方面的资源使用情况。CPU,内存等等。top 像 dashboard 一样,数据是一直滚动刷新的。