19 种常见的 JavaScript 和 Node.js 错误
译者 | 刘汪洋
审校 | 重楼
速度、性能和响应性在 Web 开发中起着至关重要的作用,尤其是在使用 JAVAScript 和 Node.js 开发时尤为重要。如果一个网站响应缓慢或界面卡顿,就会让人感到非常业余;如果网站经过精心设计和优化,能够给用户带来丝滑的使用体验,就显得非常专业。

打造一个真正高性能的 Web 应用并非易事,其中潜藏着许多容易忽视的性能陷阱。这些不易被察觉的编程习惯或错误不仅可能降低 JavaScript 的执行速度,还可能导致代码冗余,进一步降低应用的运行效率。
即使你已经压缩了代码并合理地使用了缓存,网站在某些情况下仍然可能运行缓慢。例如,用户界面在滚动或点击按钮时出现明显的卡顿,或页面加载时间过长。
这到底是为什么呢?
分析表明,有多种常见的不良实践会无意中拖慢 JavaScript 的执行效率。随着时间推移,这些不良实践会逐步影响网站的整体性能。
幸运的是,这些性能问题都是可以预防和解决的。
本文将深入分析 19 个可能降低 JavaScript 和 Node.js 应用性能的隐性问题,并通过具体的实例和解决策略,对这些问题进行详细讨论和优化。
准确地识别并解决这些性能陷阱是实现高效、流畅用户体验的关键。下面,就让我们一起探索吧!
1. 变量声明与作用域的不恰当使用
在 JavaScript 初学阶段,开发者常常习惯性地在全局作用域中声明变量,但这种做法往往会带来很多副作用。
让我们通过一个示例来解释:
// globals.js
var color = 'blue';
function printColor() {
console.log(color);
}
printColor(); // 输出 'blue'
虽然上述代码看着没有问题,但如果有另一个脚本中编写如下代码:
// script2.js
var color = 'red';
printColor(); // 输出 'red'!
由于 color 变量是在全局作用域内定义的,因此 script2.js 就能够轻易覆盖它。为避免这种情况,应尽量在函数作用域内声明局部变量:
function printColor() {
var color = 'blue'; // 局部变量
console.log(color);
}
printColor(); // 输出 'blue'
这样一来,其他脚本中对全局变量的更改不会影响 printColor 函数。
在全局作用域内随意声明变量是一种不良的编程习惯,也被认为是编程反模式。应当尽量将全局变量的使用局限于配置常量,并确保其他变量在尽可能小的作用域内被声明。
2. DOM 操作的效率问题
在更新 DOM 元素时,建议批量更改,而不是一次只操作一个节点。
请看以下逐个添加列表项的代码示例:
const ul = document.getElementById('list');
for (let i = 0; i < 10; i++) {
const li = document.createElement('li');
li.textContent = i;
ul.AppendChild(li);
}
更好的做法是先构建一个字符串,然后通过 .innerhtml进行设置:
const ul = document.getElementById('list');
let html = '';
for (let i = 0; i < 10; i++) {
html += `<li>${i}</li>`;
}
ul.innerHTML = html;
构建字符串可以减少回流。我们只需一次更新 DOM,而不是十次。
对于多次更新,可以先集中收集所有的更改,然后一次性地应用。或者更好的办法是使用 DocumentFragment 进行批量节点添加。
3. DOM 操作的过度使用
过于频繁地更新 DOM 会对性能产生严重影响。
以一个聊天应用为例,该应用将每条新消息插入到页面中。
不推荐的做法:
// 收到新消息
const msg = `<div>${messageText}</div>`;
chatLog.insertAdjacentHTML('beforeend', msg);
这种方法会在每收到一条新消息时直接进行 DOM 插入。
一个更加高效的方法是限制更新的频率:
推荐的做法:
let chatLogHTML = '';
const throttleTime = 100; // ms
// 收到新消息
chatLogHTML += `<div>${messageText}</div>`;
// 对 DOM 更新进行节流
setTimeout(() => {
chatLog.innerHTML = chatLogHTML;
chatLogHTML = '';
}, throttleTime);
通过这种方式,我们最多每 100ms 执行一次 DOM 更新,有效地控制了更新操作的频率。
对于高度动态的用户界面,可考虑使用如 React 等支持虚拟 DOM 的库。这些库能通过虚拟表示来最小化实际的 DOM 操作。
4. 事件委托的缺失
给多个元素分别添加事件监听器会导致不必要的资源消耗。例如,一个表格,其中每一行都有一个删除按钮:
不推荐的实践:
const rows = document.querySelectorAll('table tr');
rows.forEach(row => {
const deleteBtn = row.querySelector('.delete');
deleteBtn.addEventListener('click', handleDelete);
});
这种方式为每一个删除按钮都单独设置了一个事件监听器。更优的做法是采用事件委托机制:
推荐的实践:
const table = document.querySelector('table');
table.addEventListener('click', e => {
if (e.target.classList.contAIns('delete')) {
handleDelete(e);
}
});
采用这种方式后,整个 <table> 元素仅需一个事件监听器,从而降低了内存消耗。
事件委托是通过利用事件冒泡,让单一的事件监听器管理多个事件。应该在合适的情况下使用委托。
5. 字符串拼接的低效性
在循环中进行字符串拼接会影响性能。
看看下面的代码:
let html = '';
for (let i = 0; i < 10; i++) {
html += '<div>' + i + '</div>';
}
创建新字符串需要内存分配。为了提高性能,更有效的做法是使用数组:
const parts = [];
for (let i = 0; i < 10; i++) {
parts.push('<div>', i, '</div>');
}
const html = parts.join('');
使用数组能减少中间字符串的生成。.join() 方法在最后进行一次性的拼接。
对于多次字符串拼接,使用数组的 join 方法。同时,也可以考虑使用模板字面量来嵌入变量。
6. 循环性能未经优化
在 JavaScript 中,循环常常是性能问题的罪魁祸首。一个常见的错误是反复获取数组长度:
不佳实践:
const items = [/*...*/];
for (let i = 0; i < items.length; i++) {
// ...
}
重复检查 .length 会阻碍优化。
优秀实践:
const items = [/*...*/];
const len = items.length;
for (let i = 0; i < len; i++) {
// ...
}
通过缓存数组长度,我们可以避免在每次迭代中都去计算它,从而提高循环速度。其他优化手段包括从循环中提升不变量,简化终止条件,以及避免在迭代中进行耗时较长的操作。
7. 不必要的同步操作
JavaScript 的异步能力是其一大优点。但要警惕阻塞式 I/O!
例如:
不佳实践:
const data = fs.readFileSync('file.json'); // 阻塞!
这会在从磁盘读取数据时暂停执行。相反,应使用回调或 Promise:
优秀实践:
fs.readFile('file.json', (err, data) => {
// ...
});
现在,在文件读取过程中,事件循环仍然会继续执行。对于复杂的流程,async/await 可以简化异步逻辑。要避免使用同步操作以防止阻塞。
8. 阻塞事件循环
JavaScript 使用单线程的事件循环。阻塞它会导致整个程序暂停执行。常见的阻塞因素包括:
- 大量的计算任务
- 同步 I/O
- 未优化的算法
例如:
function countPrimes(max) {
// 未优化的循环
for (let i = 0; i <= max; i++) {
// ...检查是否为质数...
}
}
countPrimes(1000000); // 长时间运行!
这样的代码会同步执行,从而阻塞其他事件。为了避免这种情况,你可以:
- 延迟不必要的任务
- 批量处理数据
- 使用 Worker 线程
- 寻找代码优化的机会
要确保事件循环可以流畅地运行。定期进行性能分析以捕获阻塞性代码。
9. 低效的错误处理
在 JavaScript 中,正确地处理错误是至关重要的。但要小心性能陷阱!
不佳实践:
try {
// ...
} catch (err) {
console.error(err); // 仅仅是记录
}
这样虽然捕获了错误,但并未采取纠正措施。未处理的错误通常会导致内存泄漏或数据损坏。
更佳实践:
try {
// ...
} catch (err) {
console.error(err);
// 触发错误事件
emitError(err);
// 将变量置为空
obj = null;
// 通知用户
showErrorNotice();
}
单纯记录错误是不够的!要清理残留数据,通知用户,并考虑恢复选项。使用像 Sentry 这样的工具来监控生产环境中的错误,并明确处理所有错误。
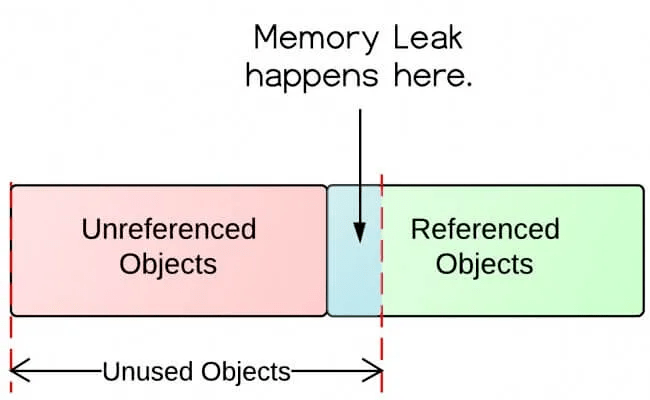
11. 内存泄漏
内存泄漏是当内存被分配但从未被释放的情况。随着时间的推移,泄漏会累积并降低性能。
在 JavaScript 中,常见的内存泄漏来源包括:
- 未清理的事件监听器
- 过时的对已删除 DOM 节点的引用
- 不再需要的缓存数据
- 在闭包中累积的状态
例如:
function processData() {
const data = [];
// 使用闭包累积数据
return function() {
data.push(getData());
}
}
const processor = processData();
// 长时间运行...持续持有对不断增长的数据数组的引用!
这个数组持续变大,但从未被清理。要修复这个问题,你可以:
- 使用弱引用
- 清理事件监听器
- 删除不再需要的引用
- 限制闭包状态的大小
持续监控内存使用情况,并关注其增长趋势。在问题积累之前,主动消除内存泄漏。
12. 过度依赖外部库
NPM (Node Package Manager) 提供了大量的库和工具,让开发者可以选择和使用,但应避免不加考虑地导入过多的依赖!每增加一个依赖,都会增加包的大小和潜在的攻击面。
不佳做法:
import _ from 'lodash';
import moment from 'moment';
import validator from 'validator';
// 等等...
仅为了一些小功能就导入整个库。更好的做法是按需选择性地导入所需的函数:
良好做法:
import cloneDeep from 'lodash/cloneDeep';
import { format } from 'date-fns';
import { isEmail } from 'validator';
只导入你真正需要用到的功能。定期审查依赖,剔除不再使用的库。保持项目依赖精简,尽量减少不必要的库和工具。
13. 没有充分利用缓存
缓存能够通过重用之前的结果,以避免重复进行耗时的计算,但人们常常忽视这一点。
不佳做法:
function generateReport() {
// 执行耗时的处理过程
// 以生成报告数据...
}
generateReport(); // 计算一次
generateReport(); // 再次计算!
由于输入没有改变,报告完全可以被缓存:
良好做法:
let cachedReport;
function generateReport() {
if (cachedReport) {
return cachedReport;
}
cachedReport = // 耗时的处理...
return cachedReport;
}
现在,重复的函数调用会很快。其他的缓存策略:
- 像 redis 这样的内存缓存
- HTTP 缓存头
- 用于客户端缓存的 LocalStorage
- 用于资产缓存的 CDN
对适合缓存的数据进行缓存,通常会显著提升速度!
14. 未优化的数据库查询
在与数据库交互时,低效的查询会拖慢性能。应避免的问题有:
不佳做法:
// 没有使用索引
db.find({name: 'John', age: 35});
// 查询不必要的字段
db.find({first: 'John', last:'Doe', email:'john@doe.com'}, {first: 1, last: 1});
// 过多的独立查询
for (let id of ids) {
const user = db.find({id});
}
这样做没有利用到索引、检索了不需要的字段,还进行了大量不必要的查询。
良好做法:
// 在 'name' 上使用索引
db.find({name: 'John'}).hint({name: 1});
// 只获取 'email' 字段
db.find({first: 'John'}, {email: 1});
// 一次查询获取多个用户
const users = db.find({
id: {$in: ids}
});
分析并解释查询计划,有针对性地创建索引,避免分散的多次查询,优化与数据存储的交互。
15. 不恰当的 Promise 错误处理
Promises 简化了异步代码,但如果拒绝没有得到处理,就会静默地失败。
不佳的做法:
function getUser() {
return fetch('/user')
.then(r => r.json());
}
getUser();
如果 fetch 拒绝,异常将不会被注意到。
良好的做法:
function getUser() {
return fetch('/user')
.then(r => r.json())
.catch(err => console.error(err));
}
getUser();
通过链接 .catch() 来恰当地处理错误。其他建议:
- 避免 Promise 嵌套地狱
- 在最顶层处理拒绝
- 配置未处理拒绝的跟踪
不要忽视 Promise 的错误!
16. 同步的网络操作
网络请求应当是异步的。但有时会使用同步版本:
不佳的做法:
const data = http.getSync('http://example.com/data'); // 阻塞!
这将在请求期间暂停事件循环。应使用回调函数:
良好的做法:
http.get('http://example.com/data', res => {
// ...
});
或者使用 Promises:
fetch('http://example.com/data')
.then(res => res.json())
.then(data => {
// ...
});
异步的网络请求允许在等待响应时进行其他处理。避免使用同步网络调用。
17. 文件 I/O 操作的低效性
同步地读取/写入文件会造成阻塞。例如:
糟糕的做法:
const contents = fs.readFileSync('file.txt'); // 阻塞!
这会在磁盘 I/O 期间暂停程序执行。更好的方式是:
良好的做法:
fs.readFile('file.txt', (err, contents) => {
// ...
});
// 或者使用 Promise
fs.promises.readFile('file.txt')
.then(contents => {
// ...
});
这样做使得在读取文件期间,事件循环能够继续运行。
对于多个文件,应使用流:
function processFiles(files) {
for (let file of files) {
fs.createReadStream(file)
.pipe(/*...*/);
}
}
避免使用同步文件操作。应优先使用回调、Promise 和流。
18. 忽略性能分析和优化
性能问题往往在明显出现之前容易被忽视。然而,优化应该是一个持续的过程!首先,应使用性能分析工具进行测量:
- 浏览器开发者工具时间线
- Node.js 分析器
- 第三方性能分析工具
即便性能看似正常,这些工具也能揭示一些优化的机会:
// profile.js
function processOrders(orders) {
orders.forEach(o => {
// ...
});
}
processOrders(allOrders);
分析器显示 processOrders 函数耗时 200ms。经过调查,我们发现:
- 循环没有优化
- 内部操作耗时高
- 存在不必要的工作
我们逐步进行优化,最终版本仅需 5ms!
性能分析是优化的指导方针。应设立性能阈值,并在超过阈值时触发告警。应经常进行性能测试,并谨慎地进行优化。
19. 不必要的代码重复
代码重复不仅影响维护性,还降低了优化空间。考虑以下例子:
function userStats(user) {
const name = user.name;
const email = user.email;
// ...逻辑...
}
function orderStats(order) {
const name = order.customerName;
const email = order.customerEmail;
// ...逻辑...
}
这里的信息提取逻辑是重复的。我们进行重构:
function getCustomerInfo(data) {
return {
name: data.name,
email: data.email
};
}
function userStats(user) {
const { name, email } = getCustomerInfo(user);
// ...逻辑...
}
function orderStats(order) {
const { name, email } = getCustomerInfo(order);
// ...逻辑...
}
现在,相同的逻辑只定义了一次。其他可行的修复措施包括:
- 提取实用函数
- 创建辅助类
- 利用模块实现重用性
尽量避免代码重复,这样既能提高代码质量,也能提供更多优化的机会。
结论
优化 JavaScript 应用性能是一个持续迭代的任务。通过掌握高效的编程方法和不断地进行性能评估,能够明显提升网站的运行速度。
特别需要关注的几个核心方面包括:降低 DOM 的修改频率、运用异步技术、避免阻塞性操作、精简依赖、利用数据缓存,以及消除冗余代码。
随着专注度和实践经验的不断积累,你将能有效地定位到性能瓶颈,并针对特定业务场景进行有针对性的优化。这样一来,你将构建出更快、更简洁和响应更敏捷的 Web 应用,从而赢得用户的青睐。
总之,在性能优化的路上,不能有丝毫的大意。遵循这些优化建议,你会发现你的 JavaScript 代码执行速度得到了显著提升。
原文标题:Is Your Code Slow?: Avoid These 19 Common JavaScript and Node.js Mistakes,作者:JSDevJournal