前面的几篇文章,作者深入探讨过RLHF 的算法原理,今天站在一定高度讨论,为什么需要RLHF 这么复杂的强化学习算法,为什么SL(监督学习) 不能达到这样一个效果?
这篇文章就从Sebastian Raschka 推特上的分享的文章进行系统分析,还是来先看一下,RLHF 算法的过程。
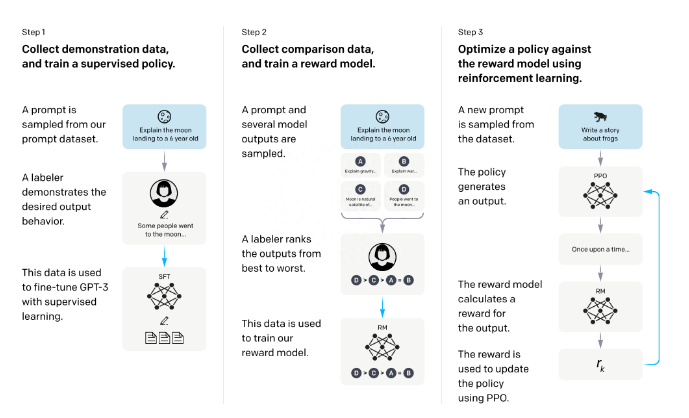
RLHF
原因一:如果使用监督学习,它只预测等级分数,不会产生连贯的反应,这样的监督学习特点是模型就尽可能训练集对应的响应上打高分( 输入句子对决定了),即使响应是不连贯的。另一方面,RLHF 则被训练来估计产生反应的质量(训练集合是回答的排序),而不仅仅是排名分数,监督学习需要对回答打分输入。
原因二:只使用监督学习将任务重新表述为一个受限的优化问题的想法(这里想表述的是,监督学习学习到的是一个固定答案,往往一个问题,可能有更好的回答响应,RLHF 需要模型具备这样的泛化能力,监督学习没有负反馈), 单纯的监督学习,损失函数结合了输出文本损失和奖励分数项, 这将使生成的响应和排名的质量更高。但这种方法只有在目标正确产生问题——答案对时才能成功,很多创新问题的回答,模型往往给不出回答,这时候监督学习会使模型编造答案。但是累积奖励对于实现用户和 ChatGPT 之间的连贯对话(多轮对话)也是必要的,而监督学习无法提供这种奖励,RLHF 由于在最终的状态动作轨迹上,求优势函数最大期望,天然适合这种多轮对话。
原因三:不选择 SL 的第三个原因是,它使用交叉熵来优化标记级的损失。虽然在文本段落的标记水平上,改变反应中的个别单词可能对整体损失只有很小的影响,但如果一个单词被否定,产生连贯性对话的复杂任务可能会完全改变上下文。因此,仅仅依靠 SL 是不够的,RLHF 对于考虑整个对话的背景和连贯性是必要的(RLHF 在全局进行优化,而不是单独对某个词生成的概率进行优化)。
原因四:监督学习可以用来训练一个模型,但根据经验发现 RLHF 往往表现得更好,实际实验结果SL + RLHF 确实表现效果更好。
原因五:使用监督学习和强化学习结合对于实现最佳性能至关重要。在这些模型中,首先使用 SL 对模型进行微调,SL 阶段允许模型学习任务的基本结构和内容,然后使用 RL 进一步更新, RLHF 阶段则完善模型的反应以提高准确性。
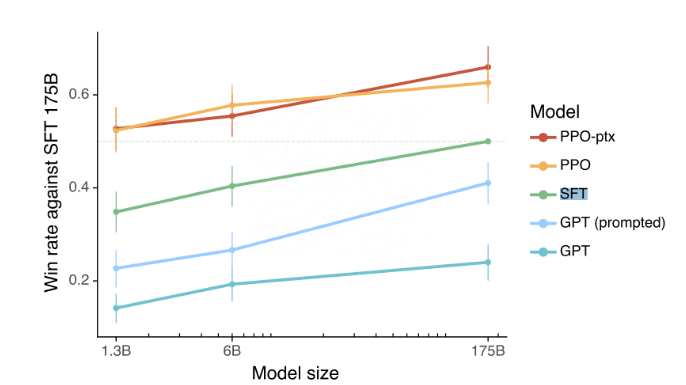
实际几种效果