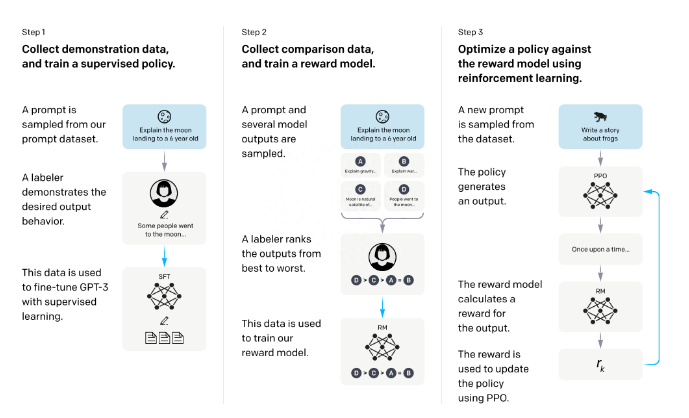
常见的缓存数据淘汰算法(LRU、LFU等算法)
常见的缓存数据淘汰算法
一个缓存组件是否好用,其中一个重要的指标就是他的缓存命中率,而命中率又和缓存组件自己的缓存数据淘汰算法息息相关。
FIFO
FIFO(First in First out)先进先出。能够理解为是一种相似队列的算法实现。
- 算法:最早进来的数据,被认为在将来被访问的几率也是最低的,所以,当规定空间用尽且需要放入新数据的时候,会优先淘汰最先进来的数据。
- 优势:最简单、最公平的一种数据淘汰算法,逻辑简单清晰,易于实现。
- 缺点:这种算法逻辑设计所实现的缓存的命中率是比较低的,由于没有任何额外逻辑可以尽量的保证经常使用数据不被淘汰掉。

LRU
LRU(The Least Recently Used)最近最久未使用算法。相比于FIFO算法智能些。
- 算法:若是一个数据最近不多被访问到,那么被认为在将来被访问的几率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰最久未被访问的数据。
- 优势:LRU能够有效的对访问比较频繁的数据进行保护,也就是针对热点数据的命中率提升有明显的效果。
缺点:对于周期性、偶发性的访问数据,有大几率可能形成缓存污染,也就是置换出去了热点数据,把这些偶发性数据留下了,从而致使LRU的数据命中率急剧降低。
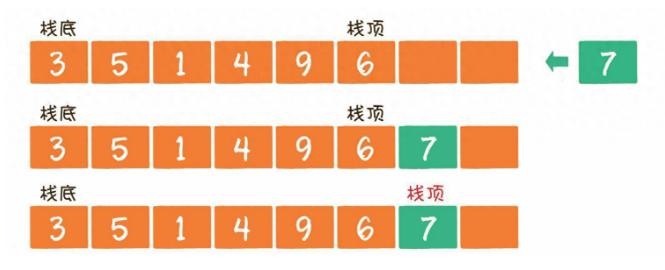
下图展现了LRU简单的工做过程,访问时对数据的提早操做,以及数据满且添加新数据的时候淘汰的过程的展现以下:

此处介绍的LRU是有明显的缺点,如上所述,对于偶发性、周期性的数据没有良好的抵抗力,很容易就形成缓存的污染,影响命中率,所以衍生出了不少的LRU算法的变种,用以处理这种偶发冷数据突增的场景,好比:LRU-K、Two Queues等,目的就是当判别数据为偶发或周期的冷数据时,不会存入空间内,从而下降热数据的淘汰率。
下图展现了LRU-K的简单工做过程,简单理解,LRU中的K是指数据被访问K次,传统LRU与此对比则能够认为传统LRU是LRU-1。能够看到LRU-K有两个队列,新来的元素先进入到历史访问队列中,该队列用于记录元素的访问次数,采用的淘汰策略是LRU或者FIFO,当历史队列中的元素访问次数达到K的时候,才会进入缓存队列。

下图展现了Two Queues的工做过程,与LRU-K相比,他也一样是两个队列,不一样之处在于,他的队列一个是缓存队列,一个是FIFO队列,当新元素进来的时候,首先进入FIFO队列,当该队列中的元素被访问的时候,会进入LRU队列,过程以下:

LFU
LFU(The Least Frequently Used)最近不多使用算法,与LRU的区别在于LRU是以时间衡量,LFU是以时间段内的次数
- 算法:若是一个数据在必定时间内被访问的次数很低,那么被认为在将来被访问的几率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰时间段内访问次数最低的数据。
- 优势:LFU也能够有效的保护缓存,相对场景来说,比LRU有更好的缓存命中率。由于是以次数为基准,因此更加准确,天然能有效的保证和提升命中率。
- 缺点:由于LFU须要记录数据的访问频率,所以需要额外的空间;当访问模式改变的时候,算法命中率会急剧降低,这也是他最大弊端。。
下面描述了LFU的简单工做过程,首先是访问元素增长元素的访问次数,从而提升元素在队列中的位置,下降淘汰优先级,后面是插入新元素的时候,由于队列已经满了,因此优先淘汰在必定时间间隔内访问频率最低的元素。

W-TinyLFU
W-TinyLFU(Window Tiny Least Frequently Used)是对LFU的的优化和增强。
- 算法:当一个数据进来的时候,会进行筛选比较,进入W-LRU窗口队列,以此应对流量突增,通过淘汰后进入过滤器,通过访问频率判决是否进入缓存。若是一个数据最近被访问的次数很低,那么被认为在将来被访问的几率也是最低的,当规定空间用尽的时候,会优先淘汰最近访问次数很低的数据;
- 优势:使用Count-Min Sketch算法存储访问频率,极大的节省空间;按期衰减操做,应对访问模式变化;而且使用window-lru机制可以尽量避免缓存污染的发生,在过滤器内部会进行筛选处理,避免低频数据置换高频数据。
- 缺点:是由谷歌工程师发明的一种算法,目前已知应用于Caffeine Cache组件里。
关于Count-Min Sketch算法,能够看做是布隆过滤器的同源的算法,假如咱们用一个hashmap来存储每一个元素的访问次数,那这个量级是比较大的,而且hash冲突的时候须要作必定处理,不然数据会产生很大的偏差,Count-Min Sketch算法将一个hash操做,扩增为多个hash,这样原来hash冲突的几率就下降了几个等级,且当多个hash取得数据的时候,取最低值,也就是Count Min的含义所在。
下图展现了Count-Min Sketch算法简单的工做原理:
- 假设有四个hash函数,每当元素被访问时,将进行次数加1;
- 此时会按照约定好的四个hash函数进行hash计算找到对应的位置,相应的位置进行+1操做;
- 当获取元素的频率时,一样根据hash计算找到4个索引位置;
- 取得四个位置的频率信息,而后根据Count Min取得最低值做为本次元素的频率值返回,即Min(Count);