强过AutoGPT!微软重磅研究提出APO算法,「自动提示」淘汰提示工程师

新智元报道
编辑:桃子
【新智元导读】手写提示既费时又费力,微软研究人员的APO算法提供了一种自动化的解决方案。无需调整超参数或模型训练,APO可以显著提高提示的性能,并具有可解释性。
模型调教得好不好,提示(prompt)最重要。
在优化和改进提示工程的过程中,提示变得越来越精巧、复杂。

据google Trends,提示工程在过去的6个月受欢迎程度急剧上升,到处都是关于提示的教程和指南。
比如,一个在网上爆火的提示工程指南Github已经狂澜28.5k星。
然而,完全用试错法开发提示可能不是最有效的策略。
为了解决这个问题,微软研究人员开发了一种全新提示优化方法,称为自动提示优化(APO)。

论文地址:https://arxiv.org/pdf/2305.03495.pdf
手写提示省了
近来,各种迹象表明,在大规模网络文本中训练的大型语言模型在跨越各种NLP任务中有时表现不佳。
这些LLMs都是通过提示来遵循人的指令。然而,编写这些自然语言提示仍然是一个手工试错的过程,需要人们付出巨大努力,甚至还得具备专业知识。
因此,还得需要自动,或半自动的程序来帮助程序员写出最好的提示。

最近的一些研究,通过训练辅助模型,或对提示进行可微表示来研究这个问题。
然而,这些工作假定可以访问到LLM的内部状态变量,而实操的人通常通过API与LLM进行交流。
其他的工作则通过强化学习或LLM基础反馈对提示进行离散操做。
这些算法也可能需要对LLM的低级访问,还会产生不可理解的输出,或依赖于无方向蒙特卡罗搜索(monte-carlo search)的语义空间上的提示。
对此,微软研究人员提出了自动提示优化(APO),一个通用的和非参数提示优化算法。
APO是一种受数值梯度下降(numerical gradient descent)启发的通用非参数提示优化算法,旨在自动化和改进LLM的快速开发过程。

APO算法的整体框架
这一算法建立在现有的自动化方法的基础上,包括训练辅助模型,或提示的可微表示,以及使用强化学习或基于LLM的反馈进行离散操作。
与以前的方法不同,APO通过在基于文本的苏格拉底对话(Socratic dialogue)中使用梯度下降法来解决离散优化的障碍。
它用LLM反馈代替了差异,用LLM编辑代替了反向传播。
更具体来讲,该算法首先利用小批量的训练数据获得自然语言「梯度」,以描述给定提示中缺陷的。
这些梯度指导编辑过程,在梯度的相反语义方向上编辑当前提示符。
然后,再进行更广泛的集束搜索(beam search),以扩大提示的搜索空间,将提示最佳化问题转化为集束候选的选择问题。
非参数「梯度下降」的离散提示优化
自动提示优化框架假设可以访问由输入和输出文本对(数字、类别、汇总等)组成的初始提示

和
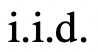
训练数据:。
要注意的是,所有提示p都是从相干自然语言的空间中提取的。
研究人员假设访问了一个黑盒LLM API,,它返回由连接p和x组成的提示符可能的文本延续y (例如,少样本提示符和输入示例,或Chatbot角色和对话历史)。
在这种情况下,APO算法迭代精化了提示
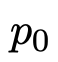
以产生,对于某些度量函数

和域内测试或开发数据

,这是最佳提示的一个近似。
梯度下降
在研究的设置中,梯度下降法是指 (1) 用一批数据评估提示符的过程,(2) 创建一个局部丢失信号,其中包含关于如何改进当前提示符的信息,然后 (3) 在开始下一次迭代之前,在梯度的相反语义方向编辑提示符。
在此,研究人员使用一对静态LLM提示来完成这个过程,如图所示。
第一个提示是创建丢失信号「梯度」,叫做

。
虽然特定的内容可能会有所不同,但是

必须始终考虑当前提示

,以及

在一小批数据(特别是错误数据集)上的行为,并生成缺陷的自然语言摘要。这个摘要变成了梯度。
就像传统的梯度一样,梯度表示参数空间中的一个方向,这会使模型用当前提示描述缺陷的自然语言空间变得更糟糕。
第二个提示符叫做
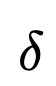
,虽然这个提示符也是变化的,但它必须始终采用梯度和当前提示符,然后在与相反的语义方向上对执行编辑,即修复指示的问题。
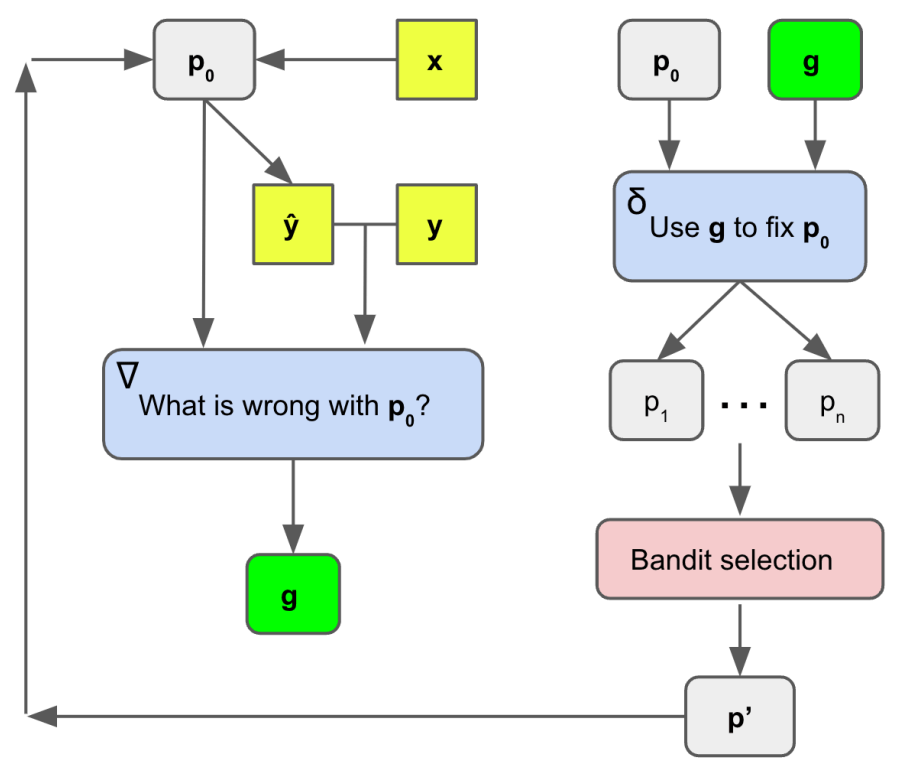
与传统的机器学习设置不同,研究人员并没有生成一个单一的梯度或编辑,而是生成了一些方向,可以改善当前的提示。
集束搜索
接下来,研究者描述了梯度下降用于指导集束搜索在提示符空间上的运行。这个集束搜索是提示训练算法的外部循环。

集束搜索是一个迭代优化过程,在每次迭代中,当前提示符用于生成许多新的候选提示符。
接下来,一个选择过程就是用来决定哪些提示,值得继续进行到下一次迭代。这个循环允许对多个提示符候选进行增量改进和探索。
实验评估
为了评估 APO 的有效性,微软研究小组将其与三种最先进的NLP任务即时学习基线进行了比较,包括越狱检测、仇恨语音检测、假新闻检测和讽刺检测。
APO在所有四个任务中都持续超越基线,在蒙特卡洛(MC)和强化学习(RL)基线上取得了显著的进步。
平均而言,APO比MC和RL基线分别提高了3.9%和8.2% ,比原始提示

提高了15.3% ,比AutoGPT提高了15.2%。
结果表明,提出的算法可以提高初始提示输入31%的性能,超过最先进的提示学习基线平均4-8% ,而依赖较少的LLM API调用。
此外,研究人员还展示了优化过程的可解释性,并调查了算法的缺点。
值得注意的是,这些改进是在没有额外的模型训练或超参数优化的情况下完成的,这表明了APO如何有效改进了LLM的提示。
对于提示工程来说,APO的出现是非常兴奋的。
APO通过使用梯度下降法和集束搜索自动化快速优化提示过程,减少了快速开发所需的人力和时间。
实证结果表明,该模型能够在一系列自然语言处理任务中迅速提高质量。

越狱是一项新的任务,目标是确定用户对LLM的输入是否代表越狱攻击。我们将越狱攻击定义为一种用户互动策略,旨在让AI打破自己的规则。
发现微软研究员带来的改变游戏规则的自动提示优化(APO)!一个强大的通用框架,用于优化LLM提示。
参考资料:
https://arxiv.org/pdf/2305.03495.pdf