一文精通递归算法

一、什么是递归?
自己调用自己,当业务逻辑符合以下三个条件的时候,就可以考虑使用递归来实现。
- 一个问题可以分解为多个子问题;
- 当前问题与其子问题除了数据规模不同外,求解思路完全一样;
- 存在递归终止条件;
二、为什么要使用递归?
理论上,任何递归代码都可以使用非递归的方式进行实现,那么为什么还要使用递归呢?
递归求解本质上是使用系统提供的栈来实现的,由系统为我们自动递归求解;如果改成非递归的方式,那么我们其实就是在手动递归,本质上这两种方式没有任何区别。但是相同的逻辑,两份代码,递归实现明显更加地简洁,更加有利系统的维护。
三、如何使用递归?
我们以一个实际的例子来演示如何使用递归。
假设,有n个台阶,我们一步可以跨一个台阶,也可以一步跨两个台阶,那么这n个台阶总共有多少种跨法?
我们按照递归使用的三个条件来分析下:
- 是否可以分解为子问题?
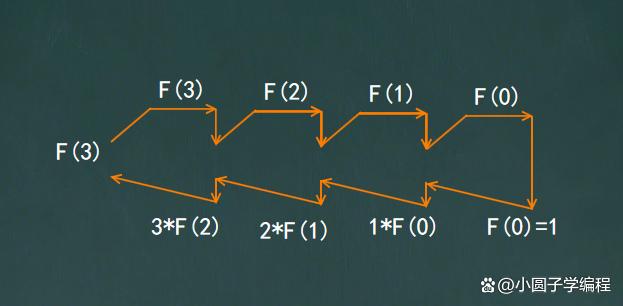
- 是的,我们跨上第n阶台阶时,要么是一步一个跨上去的,要么就是一步两个跨上去的,所以问题就分解为“跨上n-1个台阶有多少种跨法”+“跨上n-2个台阶有多少种跨法”,递推公式可以表示为f(n)=f(n-1)+f(n-2);
- 当前问题和子问题的求解思路是否一样?
- 是的
- 是否存在终止条件?
- 是的,当n为1的时候,就一种跨法,当n为2的时候有两种跨法,当n为3或者4的时候,可以拆解为子问题,所以终止条件就是f(1)=1,f(2)=2;
分析完之后,我们就得到了带终止条件的递推公式,再转换为代码即可:
int countSteps(int n){
if(n == 1) {
return 1;
}
if(n == 2) {
return 2;
}
return f(n-1) + f(n-2);
}
递归的求解过程确实很难一下子就理解清楚,这是由于我们人脑的机制造成的,谁都会感觉这样。
我们应该假设子问题f(n-1)和f(n-2)已经得到求解,然后在此基础上去求解当前的问题f(n),得到一个递推公式,如此只思考两层之间的关联关系会简单很多,千万不要试图去分解和理解每个递归层次的过程。
四、使用递归需要注意什么?
4.1 堆栈溢出
当递归调用深度过深的时候,就很容易出现栈溢出的问题,此时最好的方法就是根据业务场景逻辑和JVM的栈大小确定一个合理的最大递归深度,当超过该深度值的时候,程序抛出异常;
4.2 重复计算
子问题的子问题可能会出现重复的问题,比如f(6)=f(5)+f(4),其中,f(5)和f(4)都会有子问题f(3),那么f(3)应该是不需要重复计算的。
我们可以将求解过的问题结果保存到散列表中,当递归调用执行时,先检查该问题是否已经求解过了,如果是那么直接从散列表中获取结果返回即可,只有没有求解过的问题,才继续递归调用;
int countSteps(int n){
if(n == 1) {
return 1;
}
if(n == 2) {
return 2;
}
// 先从散列表中检查是否已经对f(n)求解过了
if(resultMap.get(n) != null){
return resultMap.get(n);
}
int result = f(n-1) + f(n-2);
// 将当前问题f(n)结果保存到散列表
resultMap.put(n,result);
return result;
}
4.3 时空复杂度
空间复杂度方面,因为递归深度决定着栈的使用程度,所以空间复杂度为O(n);
时间复杂度上面,虽然入栈和出栈都是O(1),但是如果递归深度较大的话,函数上下文切换等造成的时间开销也会比较可观;
4.4 递归环
有时候,可能由于脏数据的问题,会导致递归环的存在,比如在找原始推荐人的时候,A推荐了B,B推荐了C,C推荐了D,然后有一条脏数据,导致A的推荐人是D,那么在递归寻找原始推荐人的时候,就会陷入环中,可以设置一个最大递归深度来解决这个问题。