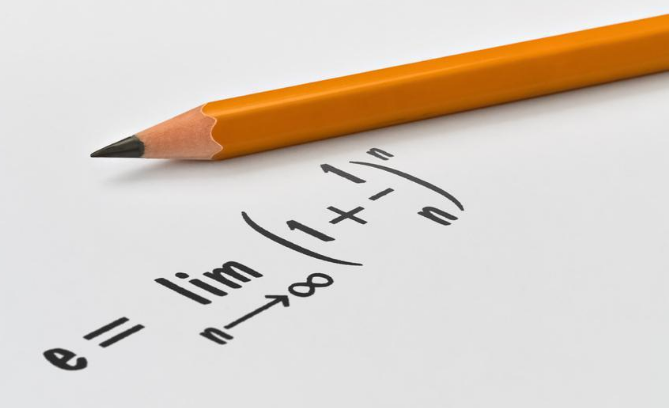如何从 Kafka 看 时间轮 算法设计
前言
Kafka 中有很多延时操作,比如对于耗时的网络请求(比如 Produce 是等待 ISR 副本复制成功)会被封装成 DelayOperation 进行延迟处理操作,防止阻塞 Kafka请求处理线程。
Kafka 没有使用 JDK 自带的 Timer 和 DelayQueue 实现。因为时间复杂度上这两者插入和删除操作都是 O(logn),不能满足 Kafka 的高性能要求。
冷知识:JDK Timer 和 DelayQueue 底层都是个优先队列,即采用了 minHeap 的数据结构,最快需要执行的任务排在队列第一个,不一样的是 Timer 中有个线程去拉取任务执行,DelayQueue 其实就是个容器,需要配合其他线程工作。
ScheduledThreadPoolExecutor 是 JDK 的定时任务实现的一种方式,其实也就是 DelayQueue + 池化是线程的一个实现。
Kafka 基于时间轮实现了延时操作,时间轮算法的插入删除操作都是 O(1) 的时间复杂度,满足了 Kafka 对于性能的要求。除了 Kafka 以外,像.NETty 、ZooKeepr、Dubbo 这样的开源项目都有使用到时间轮的实现。
那么时间轮回算法是怎么样的,算法思想是什么?Kafka 中又是怎么实现它的。
Kafka 时间轮算法
时间轮回的算法思想可以通过我们日常生活中的钟表来理解。
Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
图中的几个参数:
- tickMs: 时间跨度
- wheelSize: 时间轮回 bucket 的个数
- startMs: 开始时间
- interval:时间轮的整体时间跨度 = tickMs * wheelSize
- currentTime: tickMs 的整数倍,代表时间轮当前所处的时间
- currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimerTaskList中的所有任务
整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间。
现在你可能会有疑问,这个抽象的 currentTime 怎么推进呢,别急着看下文
那么如何支持大跨度的定时任务呢?
如果要支持几十万毫秒的定时任务,难不成要扩容时间轮的那个数组?实际上这里有两种解决方案:
- 使用增加轮次/圈数的概念(Netty 的 HashedWheelTimer )
- 举例来说,比如目前是 "0-7" 8个槽,41 % 8 + 1 = 2,即应该放在槽位是 2,下标是 1 的位置。然后 ( 41 - 1 ) / 8 = 5,即轮数记为 5。也就是说当循环 5 打开之后扫到下标的 1 的这个槽位会触发这个任务。
- 具体实现细节这里不详述
- 使用多层时间轮回的概念 (Kafka 的 TimingWheel)
- 相较于上个方案,层级时间轮能更好控制时间粒度,可以应对更加复杂的定时任务处理场景,适用的范围更广;
多层时间轮回就更像我们钟表的概念了。秒针走的一圈、分针走的一圈和时针走的一圈就形成了一个多层时间轮的关系。
第N层时间轮走了一圈,等于 N+1 层时间轮走一格。即高一层时间轮的时间跨度等于当前时间轮的整体跨度。
在任务插入时,如果第一层时间轮不满足条件,就尝试插入到高一层的时间轮,以此类推。
随着时间推进,也会有一个时间轮降级的操作,原本延时较长的任务会从高一层时间轮重新提交到时间轮中,然后会被放在合适的低层次的时间轮当中等待处理;
在 Kafka 中时间轮之间如何关联呢,如果展现这种高一层的时间轮关系?
其实很简单就是一个内部对象的指针,指向自己高一层的时间轮对象。
另外还有一个问题,如何推进时间轮的前进,让时间轮的时间往前走。
- Netty 中的时间轮是通过工作线程按照固定的时间间隔 tickDuration 推进的
- 如果长时间没有到期任务,这种方案会带来推进的问题,从而造成一定的性能损耗;
- Kafka 则是通过 DelayQueue 来推进,是一种空间换时间的思想;
- DelayQueue 中保存着所有的 TimerTaskList 对象,根据时间来排序,这样延时越小的任务排在越前面。
- 外部通过一个线程(叫做ExpiredOperationReaper)从 DelayQueue 获取超时的任务列表 TimerTaskList,然后根据 TimerTaskList 的 过期时间来精确推进时间轮的时间 ,这样就不会存在空推进的问题啦。
其实 Kafka 采用的是一种权衡的策略,把 DelayQueue 用在了合适的地方。DelayQueue 只存放了 TimerTaskList,并不是所有的 TimerTask,数量并不多,相比空推进带来的影响是利大于弊的。
总结
- Kafka 使用时间轮来实现延时队列,因为其底层是任务的添加和删除是基于链表实现的,是 O(1) 的时间复杂度,满足高性能的要求;
- 对于时间跨度大的延时任务,Kafka 引入了层级时间轮,能更好控制时间粒度,可以应对更加复杂的定时任务处理场景;
- 对于如何实现时间轮的推进和避免空推进影响性能,Kafka 采用空间换时间的思想,通过 DelayQueue 来推进时间轮,算是一个经典的 trade off。
本文通过 Kafka 来讲述了时间轮的算法设计思想,其中还提到了 Netty 时间轮算法的实现,可能会比较偏向理论,推荐去阅读一下 Kafka 和 Netty 时间轮实现的源码,并不是特别难,对比起来看会更有收获。
原文
https://ricstudio.top/archives/timewheel-in-kafka