掌握Scrapy框架,轻松实现网页自动化爬取
爬虫框架:Scrapy
01
爬虫框架:Scrapy
按照官方的说法,Scrapy是一个“为了爬取网站数据,提取结构性数据而编写的Python/ target=_blank class=infotextkey>Python应用框架,可以应用在包括数据挖掘、信息处理或存储历史数据等各种程序中”。Scrapy最初是为了网页抓取而设计的,也可以应用在获取API所返回的数据或者通用的网络爬虫开发之中。作为一个爬虫框架,可以根据自己的需求十分方便地使用Scrapy编写出自己的爬虫程序。毕竟要从使用Requests(请求)访问URL开始编写,把网页解析、元素定位等功能一行行写进去,再编写爬虫的循环抓取策略和数据处理机制等其他功能,这些流程做下来,工作量其实也是不小的。使用特定的框架有助于更高效地定制爬虫程序。作为可能是最流行的Python爬虫框架,掌握Scrapy爬虫编写是在爬虫开发中迈出的重要一步。从构件上看,Scrapy这个爬虫框架主要由以下组件组成。
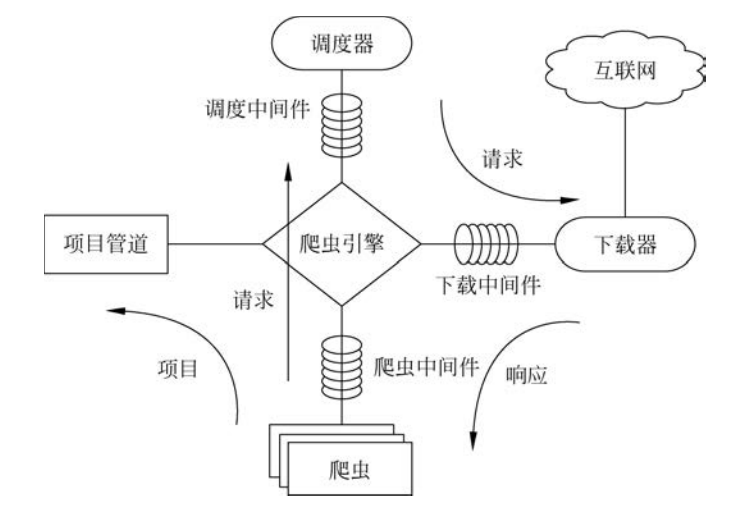
① 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务,是框架的核心。
② 调度器(Scheduler): 用来接收引擎发过来的请求, 将请求放入队列中, 并在引擎再次请求的时候返回。它决定下一个要抓取的网址, 同时担负着网址去重这一项重要工作。
③ 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给爬虫。下载器的基础是twisted,一个Python网络引擎框架。
④ 爬虫(Spiders): 用于从特定的网页中提取自己需要的信息, 即Scrapy中所谓的实体(Item)。也可以从中提取出链接,让Scrapy继续抓取下一个页面。
⑤ 管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化信息、验证实体的有效性、清洗信息等。
⑥ 下载器中间件(Downloader Middlewares): Scrapy引擎和下载器之间的框架,主要处理Scrapy引擎与下载器之间的请求及响应。
⑦ 爬虫中间件(Spider Middlewares): Scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。
⑧ 调度中间件(Scheduler Middewares): Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
它们之间的关系示意如图1-6所示。
■ 图1-6Scrapy架构
可以通过pip十分轻松地安装Scrapy,安装Scrapy首先要使用以下命令安装lxml库:pip install lxml。
如果已经安装lxml,那就可以直接安装Scrapy:pip install scrapy。
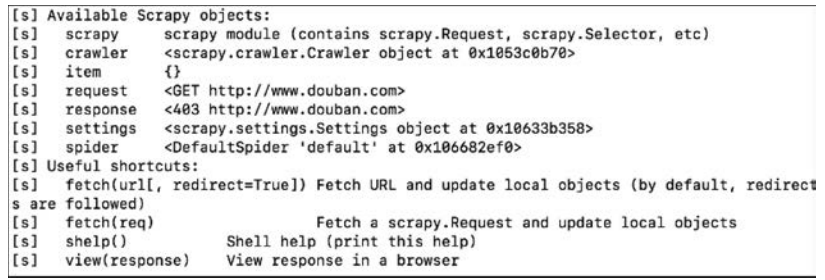
在终端中执行命令(后面的网址可以是其他域名,如www.bAIdu.com):scrapy shell www.douban.com。
可以看到Scrapy shell的反馈,如图1-7所示。
■ 图1-7Scrapy shell的反馈
为了在终端中创建一个Scrapy项目,首先进入自己想要存放项目的目录下,也可以直接新建一个目录(文件夹),这里在终端中使用命令创建一个新目录并进入:
之后执行Scrapy框架的对应命令:
会发现目录下多出了一个新的名为newcrawler的目录。其中items.py定义了爬虫的“实体”类,middlewares.py是中间件文件,pipelines.py是管道文件,spiders文件夹下是具体的爬虫,scrapy.cfg则是爬虫的配置文件。然后执行新建爬虫的命令:
输出为:
不难发现,genspider命令就是创建一个名为DoubanSpider的新爬虫脚本,这个爬虫对应的域名为douban.com。在输出中发现了一个名为basic的模板,这其实是Scrapy的爬虫模板。进入DoubanSpider.py中查看(见图1-8)。
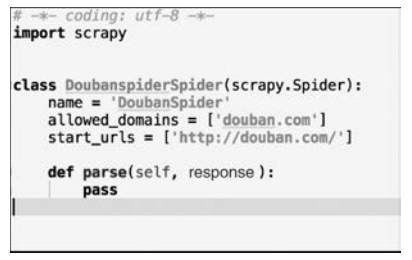
■ 图1-8DoubanSpider.py
可见它继承了 scrapy.Spider 类,其中还有一些类属性和方法。name用来标识爬虫。它在项目中是唯一的,每一个爬虫有一个独特的name。parse是一个处理 response 的方法,在Scrapy中,response 由每个 request 下载生成。作为parse方法的参数,response是一个 TextResponse 的实例,其中保存了页面的内容。start_urls列表是一个代替start_requests方法的捷径,所谓的start_requests方法,顾名思义,其任务就是从 url生成 scrapy.Request 对象,作为爬虫的初始请求。之后会遇到的Scrapy爬虫基本都有着类似这样的结构。
为了定制Scrapy爬虫,要根据自己的需求定义不同的Item,例如,创建一个针对页面中所有正文文字的爬虫,将Items.py中的内容改写为:
之后编写DoubanSpider.py:

这个爬虫会先进入start_urls列表中的页面(在这个例子中就是豆瓣网的首页),收集信息完毕后就会停止。response.xpath('//a/text').extract这行语句将从response(其中保存着网页信息)中使用xpath语句抽取出所有“a”标签的文字内容(text)。下一句会将它们逐一打印。
运行爬虫的命令是:
其中,spidername是爬虫的名称,即爬虫类中的name属性。
程序运行并进行爬取后,可以看到Scrapy爬取时的Log输出,通过Log内容可以看到爬取的进度以及结果。由于爬取目标网站的一些反爬措施,如限制USER_AGENT,因此在允信之前可能还需要在setting.py中修改一些配置,如USER_AGENT等。
值得一提的是,除了简单的scrapy.Spider,Scrapy还提供了诸如CrawlSpider、csvfeed等爬虫模板,其中CrawlSpider是最为常用的。另外,Scrapy的Pipeline和Middleware都支持扩展,配合主爬虫类使用将取得很流畅的抓取和调试体验。
当然,Python爬虫框架当然不止Scrapy一种,在其他诸多爬虫框架中,还值得一提的是PySpider、Portia等。PySpider是一个“国产”的框架,由国内开发者编写,拥有一个可视化的Web界面来编写调试脚本,使得用户可以进行诸多其他操作,如执行或停止程序、监控执行状态、查看活动历史等。除了Python,JAVA语言也常常用于爬虫的开发,比较常见的爬虫框架包括Nutch、Heritrix、WebMagic、Gecco等。爬虫框架流行的原因,就在于开发者需要“多、快、好、省”地完成一些任务,如爬虫的URL管理、线程池之类的模块,如果自己从零做起,势必需要一段时间的实验、调试和修改。爬虫框架将一些“底层”的事务预先做好,开发者只需要将注意力放在爬虫本身的业务逻辑和功能开发上。有兴趣的读者可以继续了解如PySpider这样的新框架。
02
参考书籍
↑ 点击图片官方旗舰店优惠购书 ↑
Python爬虫案例实战(微课视频版)
提供源码、380分钟视频,基础知识与丰富的Python爬虫实战案例相结合
吕云翔 韩延刚 张扬 主编
谢吉力 杨壮 王渌汀 王志鹏 杨瑞翌 副主编
定价:59.90元
ISBN:9787302633778
出版日期:2023.07.01
内容简介
本书将以Python语言为基础,由浅入深地探讨网络爬虫技术,同时,通过具体的程序编写和实践来帮助读者了解和学习Python爬虫。
本书共包含20个案例,从内容上分为四部分,分别代表不同的爬虫阶段及场景,包括了Python爬虫编写的基础知识,以及对爬虫数据的存储、深入处理和分析。
第一部分爬虫基础篇。该部分简单介绍了爬虫的基本知识,便于读者掌握相关知识,对爬虫有基本的认识。
第二部分实战基础篇(9个案例)。该部分既有简单、容易实现的入门案例,也有改进的进阶案例。丰富的内容包括爬虫常用的多种工具及方法,覆盖了爬虫的请求、解析、清洗、入库等全部常用流程,是入门实践的最佳选择。
第三部分框架应用篇(5个案例)。该部分内容从爬虫框架的角度出发,介绍了几个常用框架的案例,重点介绍了Scrapy框架,以及基于Python 3后的新特性的框架,如Gain和PySpider等,同时也对高并发应用场景下的异步爬虫做了案例解析,是不容错过的精彩内容。
第四部分爬虫应用场景及数据处理篇(6个案例)。该部分内容从实际应用的角度出发,通过不同的案例展示了爬虫爬取的数据的应用场景以及针对爬虫数据的数据分析,可以让读者体会到爬虫在不同场景上的应用,从另一个角度展示了爬虫的魅力,可以给读者带来一些新的思考。
这四部分由浅入深地介绍了爬虫常用的方法和工具,以及对爬虫数据处理的应用和实现。但需要注意的是,爬虫的技术栈不仅仅包含这几部分,而且在实际工作中的细分方法也不尽相同。本书只是对目前爬虫技术中最为常见的一些知识点,用案例的形式进行了分类和讲解,而更多的应用也值得读者在掌握一定的基础技能后进一步探索。