Kafka到底会不会丢数据?
那么 Kafka 到底会不会丢数据呢?如果丢数据,究竟该怎么解决呢?
只有掌握了这些, 我们才能处理好 Kafka 生产级的一些故障,从而更稳定地服务业务。
认真读完这篇文章,我相信你会对Kafka 如何解决丢数据问题,有更加深刻的理解。
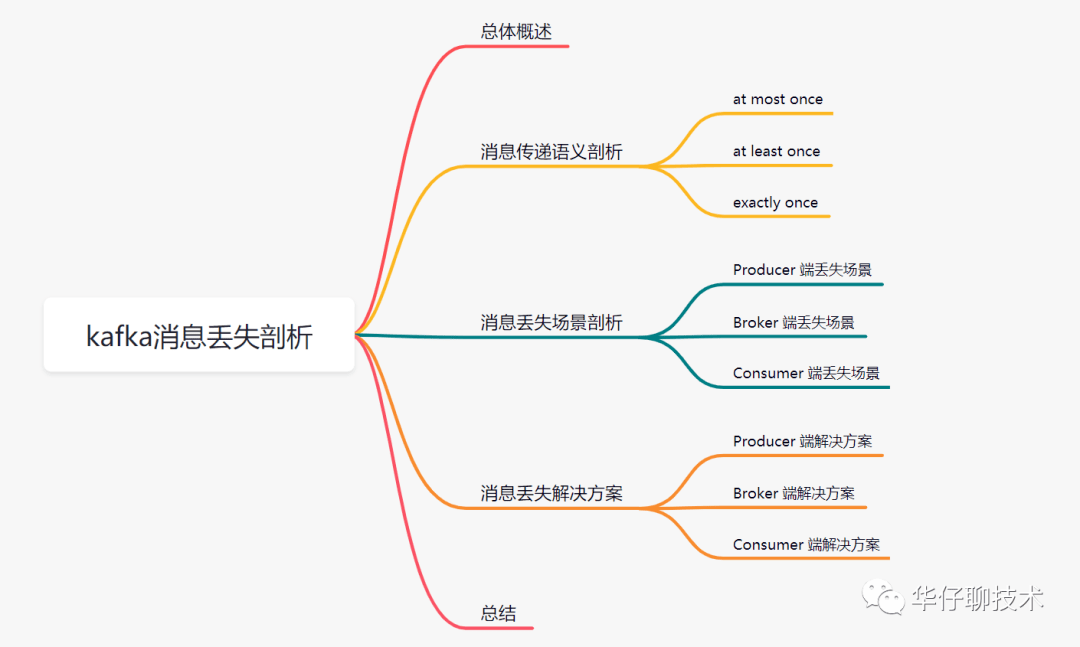
一、总体概述
越来越多的互联网公司使用消息队列来支撑自己的核心业务。由于是核心业务,一般都会要求消息传递过程中最大限度做到不丢失,如果中间环节出现数据丢失,就会引来用户的投诉,年底绩效就要背锅了。
那么使用 Kafka 到底会不会丢数据呢?如果丢数据了该怎么解决呢?为了避免类似情况发生,除了要做好补偿措施,我们更应该在系统设计的时候充分考虑系统中的各种异常情况,从而设计出一个稳定可靠的消息系统。
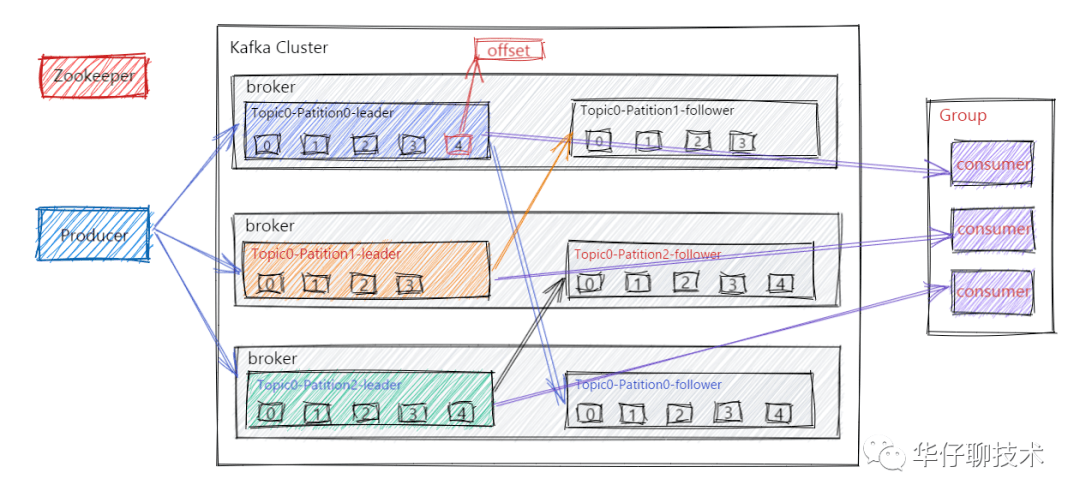
大家都知道 Kafka 的整个架构非常简洁,是分布式的架构,主要由 Producer、Broker、Consumer 三部分组成,后面剖析丢失场景会从这三部分入手来剖析。
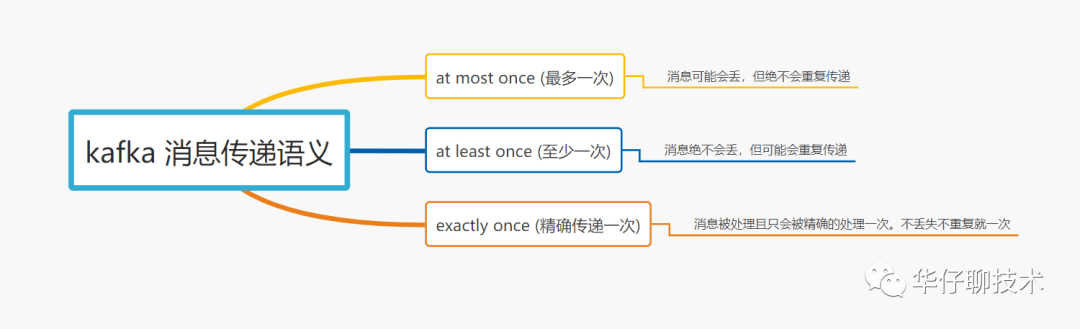
二、消息传递语义剖析
在深度剖析消息丢失场景之前,我们先来聊聊「消息传递语义」到底是个什么玩意?
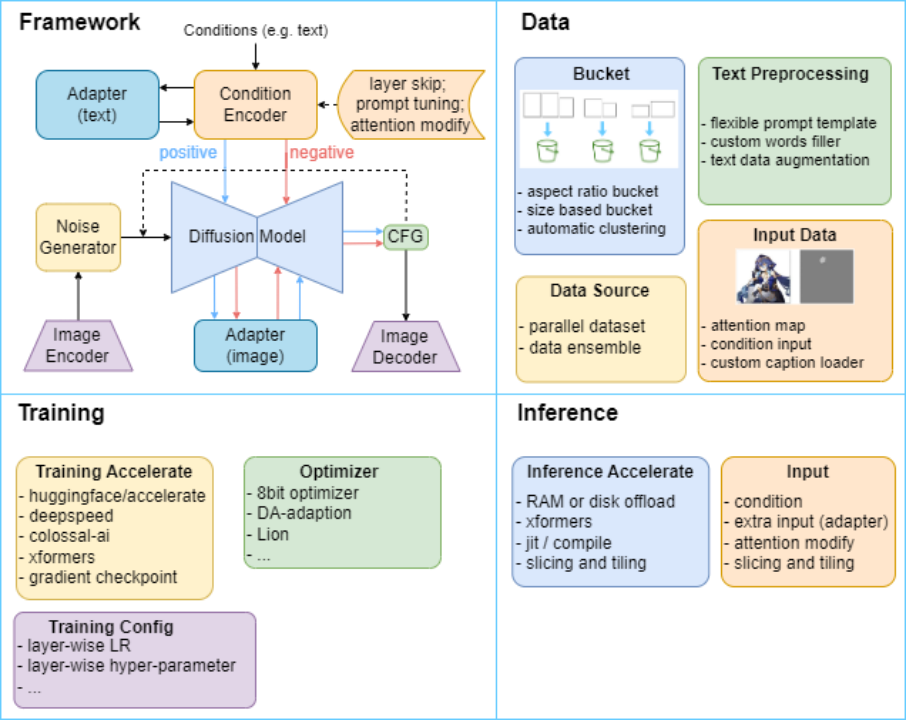
所谓的消息传递语义是 Kafka 提供的 Producer 和 Consumer 之间的消息传递过程中消息传递的保证性。主要分为三种, 如下图所示:
- 首先当 Producer 向 Broker 发送数据后,会进行 commit,如果 commit 成功,由于 Replica 副本机制的存在,则意味着消息不会丢失,但是 Producer 发送数据给 Broker 后,遇到网络问题而造成通信中断,那么 Producer 就无法准确判断该消息是否已经被提交(commit),这就可能造成 at least once 语义。
- 在 Kafka 0.11.0.0 之前, 如果 Producer 没有收到消息 commit 的响应结果,它只能重新发送消息,确保消息已经被正确的传输到 Broker,重新发送的时候会将消息再次写入日志中;而在 0.11.0.0 版本之后, Producer 支持幂等传递选项,保证重新发送不会导致消息在日志出现重复。为了实现这个, Broker 为 Producer 分配了一个ID,并通过每条消息的序列号进行去重。也支持了类似事务语义来保证将消息发送到多个 Topic 分区中,保证所有消息要么都写入成功,要么都失败,这个主要用在 Topic 之间的 exactly once 语义。
其中启用幂等传递的方法配置:enable.idempotence = true。
启用事务支持的方法配置:设置属性 transcational.id = "指定值"。
- 从 Consumer 角度来剖析, 我们知道 Offset 是由 Consumer 自己来维护的, 如果 Consumer 收到消息后更新 Offset, 这时 Consumer 异常 crash 掉, 那么新的 Consumer 接管后再次重启消费,就会造成 at most once 语义(消息会丢,但不重复)。
- 如果 Consumer 消费消息完成后, 再更新 Offset, 如果这时 Consumer crash 掉,那么新的 Consumer 接管后重新用这个 Offset 拉取消息, 这时就会造成 at least once 语义(消息不丢,但被多次重复处理)。
总结:默认 Kafka 提供 「at least once」语义的消息传递,允许用户通过在处理消息之前保存 Offset 的方式提供 「at most once」 语义。如果我们可以自己实现消费幂等,理想情况下这个系统的消息传递就是严格的「exactly once」, 也就是保证不丢失、且只会被精确的处理一次,但是这样是很难做到的。
从 Kafka 整体架构图我们可以得出有三次消息传递的过程:
- Producer 端发送消息给 Kafka Broker 端。
- Kafka Broker 将消息进行同步并持久化数据。
- Consumer 端从 Kafka Broker 将消息拉取并进行消费。
在以上这三步中每一步都可能会出现丢失数据的情况, 那么 Kafka 到底在什么情况下才能保证消息不丢失呢?
通过上面三步,我们可以得出:Kafka 只对 「已提交」的消息做「最大限度的持久化保证不丢失」。
怎么理解上面这句话呢?
- 首先是 「已提交」的消息,当 Kafka 中 N 个 Broker 成功收到一条消息并写入到日志文件后,它们会告诉 Producer 端这条消息已成功提交了,那么这时该消息在 Kafka 中就变成 "已提交消息" 了。
这里的 N 个 Broker 我们怎么理解呢?这主要取决于对 "已提交" 的定义, 这里可以选择只要一个 Broker 成功保存该消息就算已提交,也可以是所有 Broker 都成功保存该消息才算是已提交。
- 其次是 「最大限度的持久化保证不丢失」,也就是说 Kafka 并不能保证在任何情况下都能做到数据不丢失。即 Kafka 不丢失数据是有前提条件的。假如这时你的消息保存在 N 个 Broker 上,那么前提条件就是这 N 个 Broker 中至少有1个是存活的,就可以保证你的消息不丢失。
也就是说 Kafka 是能做到不丢失数据的, 只不过这些消息必须是 「已提交」的消息,且还要满足一定的条件才可以。
了解了 Kafka 消息传递语义以及什么情况下可以保证不丢失数据,下面我们来详细剖析每个环节为什么会丢数据,以及如何最大限度避免丢失数据。
三、消息丢失场景剖析
1.Producer 端丢失场景剖析
在剖析 Producer 端数据丢失之前,我们先来了解下 Producer 端发送消息的流程,对于不了解 Producer 的读者们,可以查看 聊聊 Kafka Producer 那点事。
消息发送流程如下:
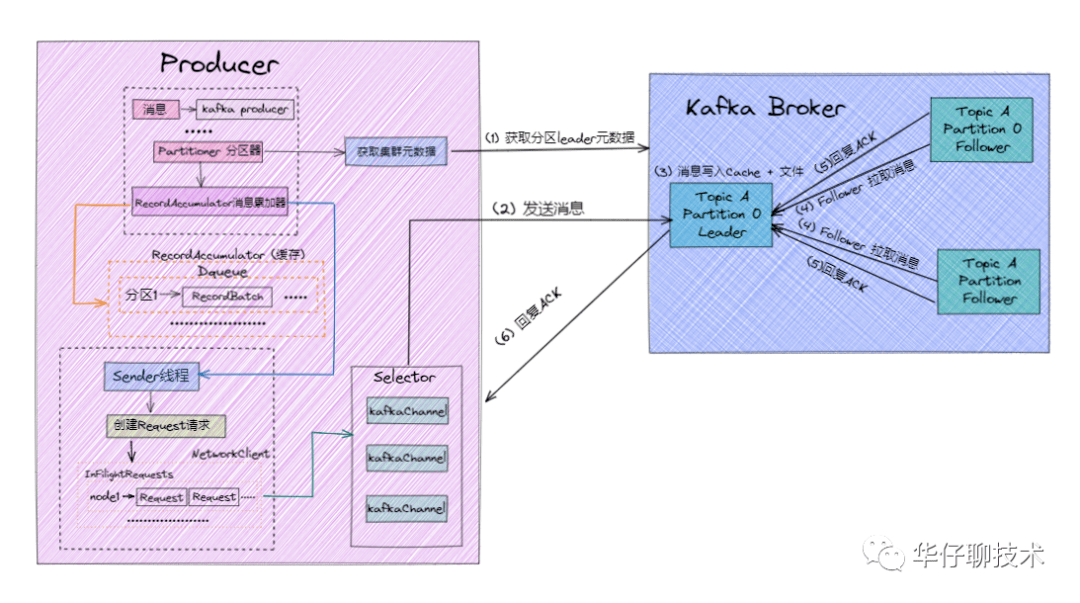
- 首先我们要知道一点就是 Producer 端是直接与 Broker 中的 Leader Partition 交互的,所以在 Producer 端初始化中就需要通过 Partitioner 分区器从 Kafka 集群中获取到相关 Topic 对应的 Leader Partition 的元数据 。
- 待获取到 Leader Partition 的元数据后直接将消息发送过去。
- Kafka Broker 对应的 Leader Partition 收到消息会先写入 Page Cache,定时刷盘进行持久化(顺序写入磁盘)。
- Follower Partition 拉取 Leader Partition 的消息并保持同 Leader Partition 数据一致,待消息拉取完毕后需要给 Leader Partition 回复 ACK 确认消息。
- 待 Kafka Leader 与 Follower Partition 同步完数据并收到所有 ISR 中的 Replica 副本的 ACK 后,Leader Partition 会给 Producer 回复 ACK 确认消息。
根据上图以及消息发送流程可以得出:Producer 端为了提升发送效率,减少IO操作,发送数据的时候是将多个请求合并成一个个 RecordBatch,并将其封装转换成 Request 请求「异步」将数据发送出去(也可以按时间间隔方式,达到时间间隔自动发送),所以 Producer 端消息丢失更多是因为消息根本就没有发送到 Kafka Broker 端。
导致 Producer 端消息没有发送成功有以下原因:
- 网络原因:由于网络抖动导致数据根本就没发送到 Broker 端。
- 数据原因:消息体太大超出 Broker 承受范围而导致 Broker 拒收消息。
另外 Kafka Producer 端也可以通过配置来确认消息是否生产成功:

在 Kafka Producer 端的 acks 默认配置为1, 默认级别是 at least once 语义, 并不能保证 exactly once 语义。
既然 Producer 端发送数据有 ACK 机制, 那么这里就可能会丢数据的!!!
- acks = 0:由于发送后就自认为发送成功,这时如果发生网络抖动, Producer 端并不会校验 ACK 自然也就丢了,且无法重试。
- acks = 1:消息发送 Leader Parition 接收成功就表示发送成功,这时只要 Leader Partition 不 Crash 掉,就可以保证 Leader Partition 不丢数据,但是如果 Leader Partition 异常 Crash 掉了, Follower Partition 还未同步完数据且没有 ACK,这时就会丢数据。
- acks = -1 或者 all: 消息发送需要等待 ISR 中 Leader Partition 和 所有的 Follower Partition 都确认收到消息才算发送成功, 可靠性最高, 但也不能保证不丢数据,比如当 ISR 中只剩下 Leader Partition 了, 这样就变成 acks = 1 的情况了。
2.Broker 端丢失场景剖析
接下来我们来看看 Broker 端持久化存储丢失场景, 对于不了解 Broker 的读者们,可以先看看 聊聊 Kafka Broker 那点事,数据存储过程如下图所示:
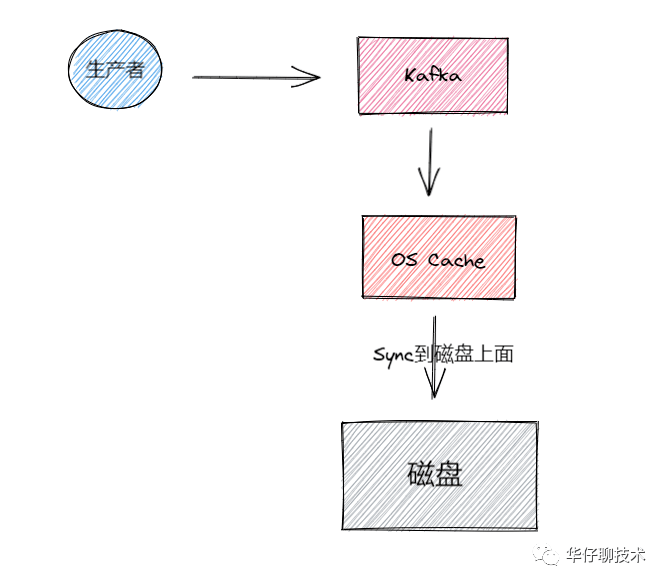
Kafka Broker 集群接收到数据后会将数据进行持久化存储到磁盘,为了提高吞吐量和性能,采用的是「异步批量刷盘的策略」,也就是说按照一定的消息量和间隔时间进行刷盘。首先会将数据存储到 「PageCache」 中,至于什么时候将 Cache 中的数据刷盘是由「操作系统」根据自己的策略决定或者调用 fsync 命令进行强制刷盘,如果此时 Broker 宕机 Crash 掉,且选举了一个落后 Leader Partition 很多的 Follower Partition 成为新的 Leader Partition,那么落后的消息数据就会丢失。
既然 Broker 端消息存储是通过异步批量刷盘的,那么这里就可能会丢数据的!!!
- 由于 Kafka 中并没有提供「同步刷盘」的方式,所以说从单个 Broker 来看还是很有可能丢失数据的。
- kafka 通过「多 Partition (分区)多 Replica(副本)机制」已经可以最大限度保证数据不丢失,如果数据已经写入 PageCache 中但是还没来得及刷写到磁盘,此时如果所在 Broker 突然宕机挂掉或者停电,极端情况还是会造成数据丢失。
3.Consumer 端丢失场景剖析
接下来我们来看看 Consumer 端消费数据丢失场景,对于不了解 Consumer 的读者们,可以先看看 聊聊 Kafka Consumer 那点事, 我们先来看看消费流程:
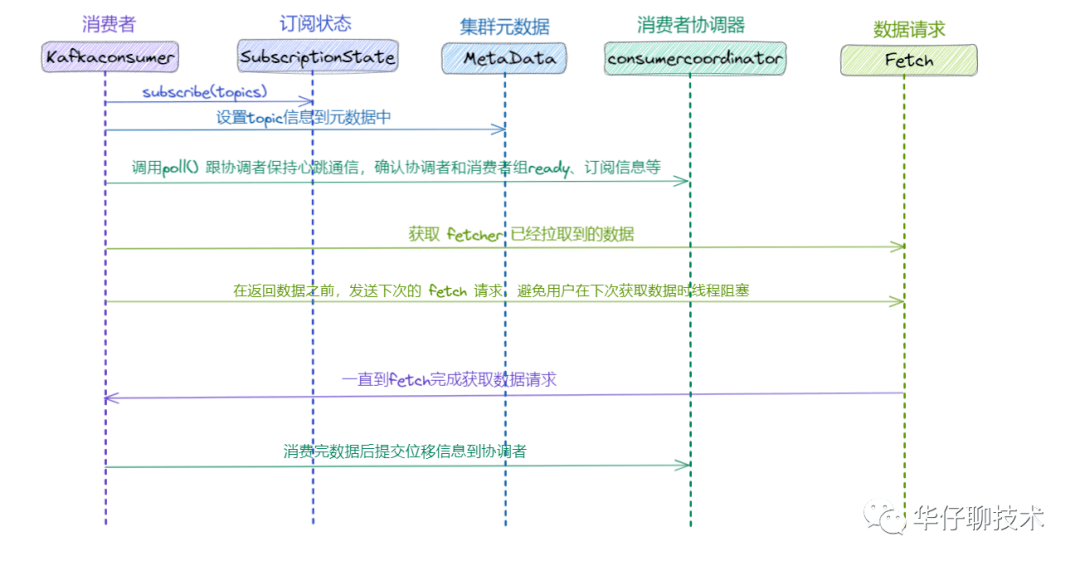
- Consumer 拉取数据之前跟 Producer 发送数据一样, 需要通过订阅关系获取到集群元数据, 找到相关 Topic 对应的 Leader Partition 的元数据。
- 然后 Consumer 通过 Pull 模式主动的去 Kafka 集群中拉取消息。
- 在这个过程中,有个消费者组的概念(不了解的可以看上面链接文章),多个 Consumer 可以组成一个消费者组即 Consumer Group,每个消费者组都有一个Group-Id。同一个 Consumer Group 中的 Consumer 可以消费同一个 Topic 下不同分区的数据,但是不会出现多个 Consumer 去消费同一个分区的数据。
- 拉取到消息后进行业务逻辑处理,待处理完成后,会进行 ACK 确认,即提交 Offset 消费位移进度记录。
- 最后 Offset 会被保存到 Kafka Broker 集群中的 __consumer_offsets 这个 Topic 中,且每个 Consumer 保存自己的 Offset 进度。
根据上图以及消息消费流程可以得出消费主要分为两个阶段:
- 获取元数据并从 Kafka Broker 集群拉取数据。
- 处理消息,并标记消息已经被消费,提交 Offset 记录。
既然 Consumer 拉取后消息最终是要提交 Offset, 那么这里就可能会丢数据的!!!
- 可能使用的「自动提交 Offset 方式」
- 拉取消息后「先提交 Offset,后处理消息」,如果此时处理消息的时候异常宕机,由于 Offset 已经提交了, 待 Consumer 重启后,会从之前已提交的 Offset 下一个位置重新开始消费, 之前未处理完成的消息不会被再次处理,对于该 Consumer 来说消息就丢失了。
- 拉取消息后「先处理消息,再进行提交 Offset」, 如果此时在提交之前发生异常宕机,由于没有提交成功 Offset, 待下次 Consumer 重启后还会从上次的 Offset 重新拉取消息,不会出现消息丢失的情况, 但是会出现重复消费的情况,这里只能业务自己保证幂等性。
四、消息丢失解决方案
上面带你从 Producer、Broker、Consumer 三端剖析了可能丢失数据的场景,下面我们就来看看如何解决才能最大限度保证消息不丢失。
1.Producer 端解决方案
在剖析 Producer 端丢失场景的时候, 我们得出其是通过「异步」方式进行发送的,所以如果此时是使用「发后即焚」的方式发送,即调用 Producer.send(msg) 会立即返回,由于没有回调,可能因网络原因导致 Broker 并没有收到消息,此时就丢失了。
因此我们可以从以下几方面进行解决 Producer 端消息丢失问题:
1)更换调用方式:
弃用调用发后即焚的方式,使用带回调通知函数的方法进行发送消息,即 Producer.send(msg, callback), 这样一旦发现发送失败, 就可以做针对性处理。
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
- 网络抖动导致消息丢失,Producer 端可以进行重试。
- 消息大小不合格,可以进行适当调整,符合 Broker 承受范围再发送。
通过以上方式可以保证最大限度消息可以发送成功。
2)ACK 确认机制:
该参数代表了对"已提交"消息的定义。
需要将 request.required.acks 设置为 -1/ all,-1/all 表示有多少个副本 Broker 全部收到消息,才认为是消息提交成功的标识。
针对 acks = -1/ all , 这里有两种非常典型的情况:
- 数据发送到 Leader Partition, 且所有的 ISR 成员全部同步完数据, 此时,Leader Partition 异常 Crash 掉,那么会选举新的 Leader Partition,数据不会丢失, 如下图所示:

- 数据发送到 Leader Partition,部分 ISR 成员同步完成,此时 Leader Partition 异常 Crash, 剩下的 Follower Partition 都可能被选举成新的 Leader Partition,会给 Producer 端发送失败标识, 后续会重新发送数据,数据可能会重复, 如下图所示:
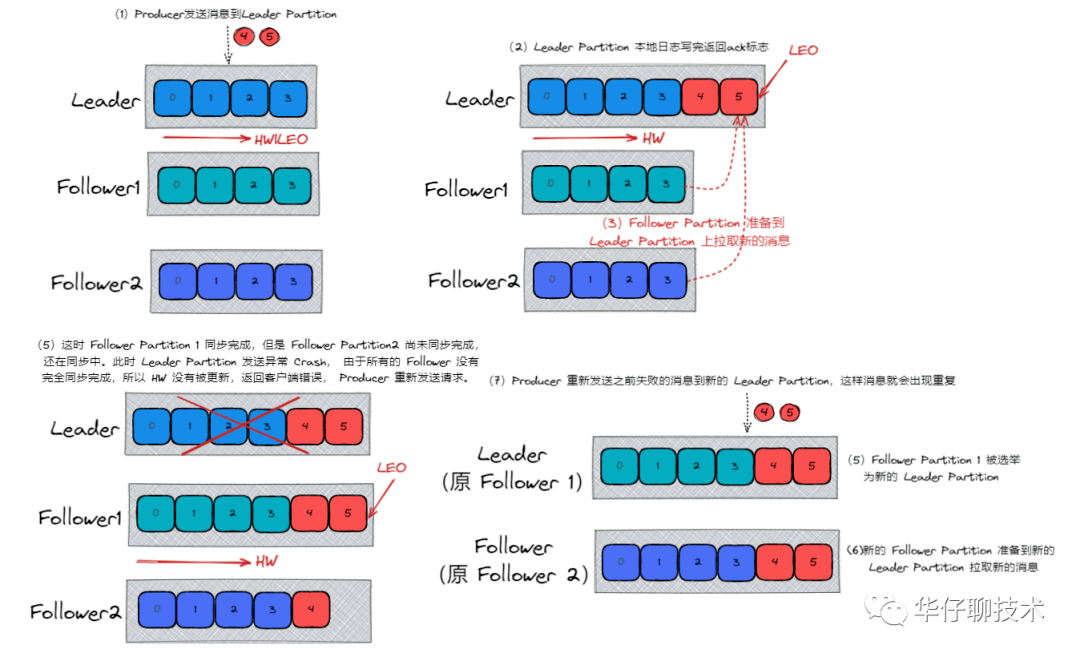
因此通过上面分析,我们还需要通过其他参数配置来进行保证:
replication.factor >= 2
min.insync.replicas > 1
这是 Broker 端的配置,下面会详细介绍。
3)重试次数 retries:
该参数表示 Producer 端发送消息的重试次数。
需要将 retries 设置为大于0的数, 在 Kafka 2.4 版本中默认设置为Integer.MAX_VALUE。另外如果需要保证发送消息的顺序性,配置如下:
retries = Integer.MAX_VALUE
max.in.flight.requests.per.connection = 1
这样 Producer 端就会一直进行重试直到 Broker 端返回 ACK 标识,同时只有一个连接向 Broker 发送数据保证了消息的顺序性。
4)重试时间 retry.backoff.ms:
该参数表示消息发送超时后两次重试之间的间隔时间,避免无效的频繁重试,默认值为100ms, 推荐设置为300ms。
2.Broker 端解决方案
在剖析 Broker 端丢失场景的时候, 我们得出其是通过「异步批量刷盘」的策略,先将数据存储到 「PageCache」,再进行异步刷盘, 由于没有提供 「同步刷盘」策略, 因此 Kafka 是通过「多分区多副本」的方式来最大限度保证数据不丢失。
我们可以通过以下参数配合来保证:
1)unclean.leader.election.enable:
该参数表示有哪些 Follower 可以有资格被选举为 Leader , 如果一个 Follower 的数据落后 Leader 太多,那么一旦它被选举为新的 Leader, 数据就会丢失,因此我们要将其设置为false,防止此类情况发生。
2)replication.factor:
该参数表示分区副本的个数。建议设置 replication.factor >=3, 这样如果 Leader 副本异常 Crash 掉,Follower 副本会被选举为新的 Leader 副本继续提供服务。
3)min.insync.replicas:
该参数表示消息至少要被写入成功到 ISR 多少个副本才算"已提交",建议设置min.insync.replicas > 1, 这样才可以提升消息持久性,保证数据不丢失。
另外我们还需要确保一下 replication.factor > min.insync.replicas, 如果相等,只要有一个副本异常 Crash 掉,整个分区就无法正常工作了,因此推荐设置成: replication.factor = min.insync.replicas +1, 最大限度保证系统可用性。
3.Consumer 端解决方案
在剖析 Consumer 端丢失场景的时候,我们得出其拉取完消息后是需要提交 Offset 位移信息的,因此为了不丢数据,正确的做法是:拉取数据、业务逻辑处理、提交消费 Offset 位移信息。
我们还需要设置参数 enable.auto.commit = false, 采用手动提交位移的方式。
另外对于消费消息重复的情况,业务自己保证幂等性, 保证只成功消费一次即可。
五、总结
至此,我们一起来总结一下这篇文章的重点。
- 从 Kafka 整体架构上概述了可能发生数据丢失的环节。
- 带你剖析了「消息传递语义」的概念, 确定了 Kafka 只对「已提交」的消息做「最大限度持久化保证不丢失」。
- 带你剖析了 Producer、Broker、Consumer 三端可能导致数据丢失的场景以及具体的高可靠解决方案。
作者丨王江华
来源丨公众号:华仔聊技术(ID:gh_97b8de4b5b34)