oneAPI用于大规模图计算异构加速框架设计
南开大学的李世阳、彭钰婷以《基于oneAPI大规模图计算异构加速框架设计》为题,分享了基于oneAPI设计的oneGRAPH在图计算领域带来的性能提升。
以下内容根据李世阳、彭钰婷演讲内容梳理
一、背景、挑战与动机
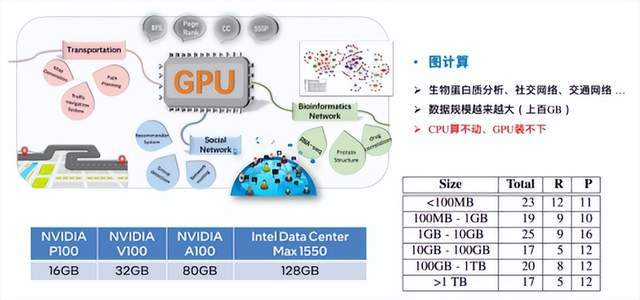
图计算已经在越来越多的场景中发挥重要的作用。近年来,图数据的爆炸式增长成为了明显的趋势。左下的表格展示了一些主流GPU的最大选择容量,而右边的表格是近期一项针对学术界和工业界所使用的图数据规模大小的调查结果。可以看到,双方都大量使用了上百GB乃至TB级别的大规模图数据。如此庞大的数据规模对算力和存储都提出了很高的要求。单独的CPU系统无法满足算力的需求,而GPU又没有足够的显存容量。因此,我们通常需要使用基于CPU-GPU的异构系统来解决out of memory GRAPH computing的问题。
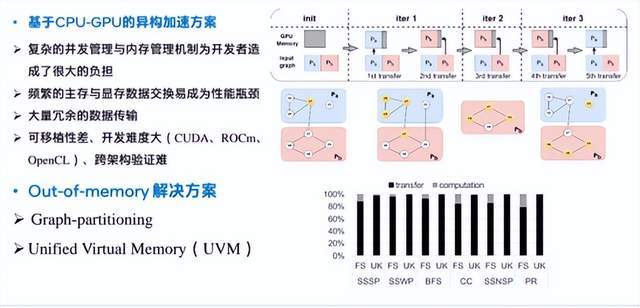
之前的一些基于CPU-GPU的异构加速方案通常存在以下的通病。主流的out of memory的解决方案有两种:第一种是基于GRAPH partitioning的方案,第二种是基于统一虚拟内存也就是UVM的方案。右图展示了一个经典的GRAPH partitioning方案的事例。实验结果表明,在这种传统方案中,数据传输占据大部分程序运行时间,造成严重的性能瓶颈。

这个图是目前最先进的graph partition方案(subway)。他通过系列组的划分,每一轮迭代需要访问的数据尽可能减少了数据传输。而基于统一虚拟内存的方案虽然不再需要我们手动控制数据的传输,但此时程序需要花费大量时间等待GPU驱动和操作系统处理显存中的page fault。
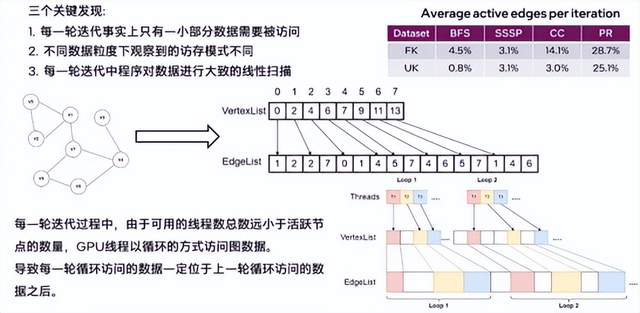
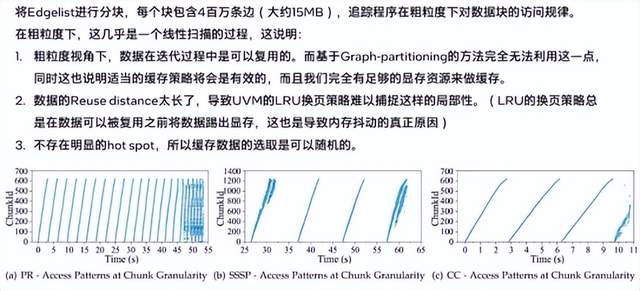
我们在粗粒度视角下进行了进一步的观察和验证。由此,我们得到了几个重要结论:数据在迭代过程中是可以复用的,数据的Reuse distance太长导致UVM的LRU换页策略难以捕捉这样的局部性,以及不存在明显的热点区域,因此,缓存数据的选取是可以随机的。

oneAPI在这个场景中带来了三大机会。首先是它的编程模型,它非常易于上手,尤其对于C++程序员。其次,它提供了便捷的设备并发管理和内存管理机制。最后,oneAPI的跨架构移植性意味着我们在新硬件平台上不再需要重写软件。
二、OneGraph与基于oneAPI的实现
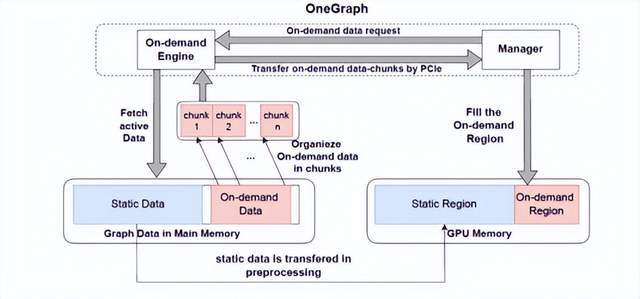
1.GPU显存的划分:
Static Region: 用于存储可能被重用的数据,其内容会在图计算迭代开始前被填充。
On Demand Region: 存储Static Region未包含但是当前迭代需要的数据。
2.控制器:
GPU端 Manager: 负责加载和计算数据,并根据需要发出Ondemand region的数据请求。
CPU端 On Demand Region Controller: 负责准备和组织On Demand Region的数据。
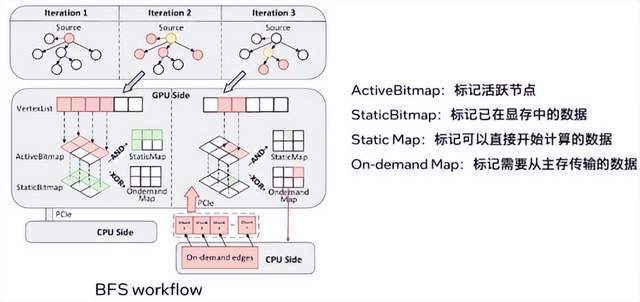
3.Bitmap设计:
ActiveBitmap: 标记本轮迭代需要访问的数据。
StaticBitmap: 记录已经存储在显存中的数据。
通过与操作和异或操作可以得到Static Map和On Demand Map,这些操作在GPU上并行进行,降低data lookup的overhead。
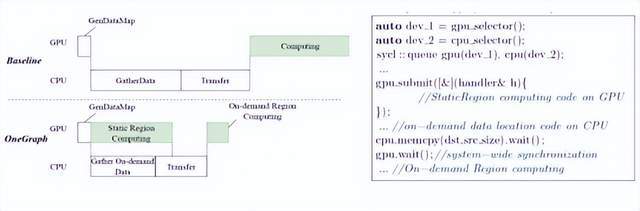
4.数据计算与传输:
利用oneAPI的设备并发管理机制,将数据计算和传输的延迟隐藏起来,通过不同的任务队列提交给CPU和GPU来实现。
三、实验效果与性能测试
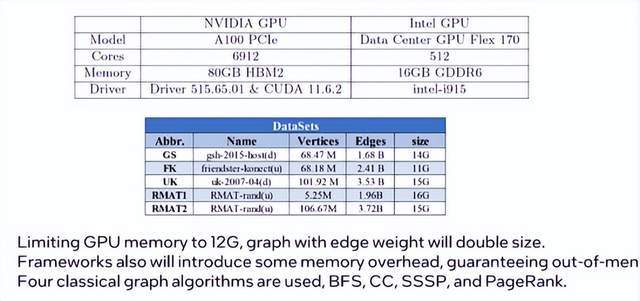
实验平台: Nvidia A100 和 Intel Flex 170 GPU。
数据集: 包括四个真实世界数据集和两个人工生成的数据集。
性能衡量算法: BFS、CC、SSSP和PageRank。
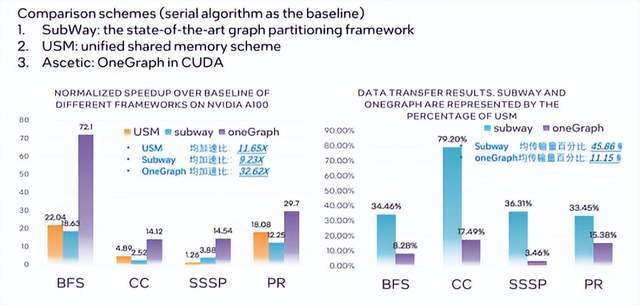
性能对比:
对比对象包括 Subway (基于GRAPH partition的方案), USM (oneAPI中的统一虚拟内存解决方案) 和 Ascetic (one GRAPH的CUDA版本)。
one GRAPH 相比 Subway 和 USM 在性能上均有显著提升。
在数据传输量方面,one GRAPH的数据传输量相对低,这主要归因于Static Region的数据重用效果。
结论
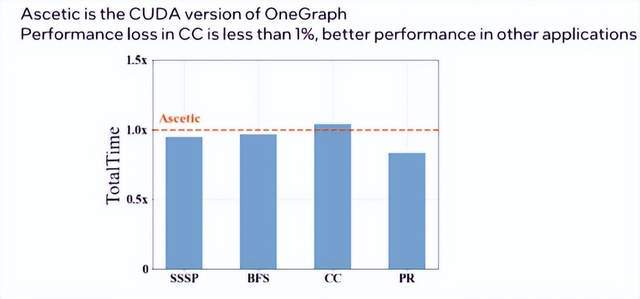
oneAPI 在图计算领域展现了强大的潜力,既提供了出色的跨平台性,又没有损失性能。one GRAPH 与其CUDA版本 Ascetic 相比,只在CC算法上存在不到1%的性能损失,其他算法表现甚至更好。
这再次验证了oneAPI的优势,即提供了跨平台性,同时还能保持良好的性能,在CPU上进行扩展测试和评估。