一次生产环境P0级事故分析
事件背景
作者所在的公司核心业务是做政府信息化软件的,就是为政府部门开发信息化系统。其中有一款信息化软件是客户每天需要使用的,并且他们面向的客户就是老百姓。
某年某月,某地区信息化系统,周末升级系统以后,后面连续一周,持续出现系统不稳定、宕机、服务假死、数据库锁表等事件。甚至星期五下午,出现三个多小时无法恢复系统,造成恶劣影响。
系统整体运行架构

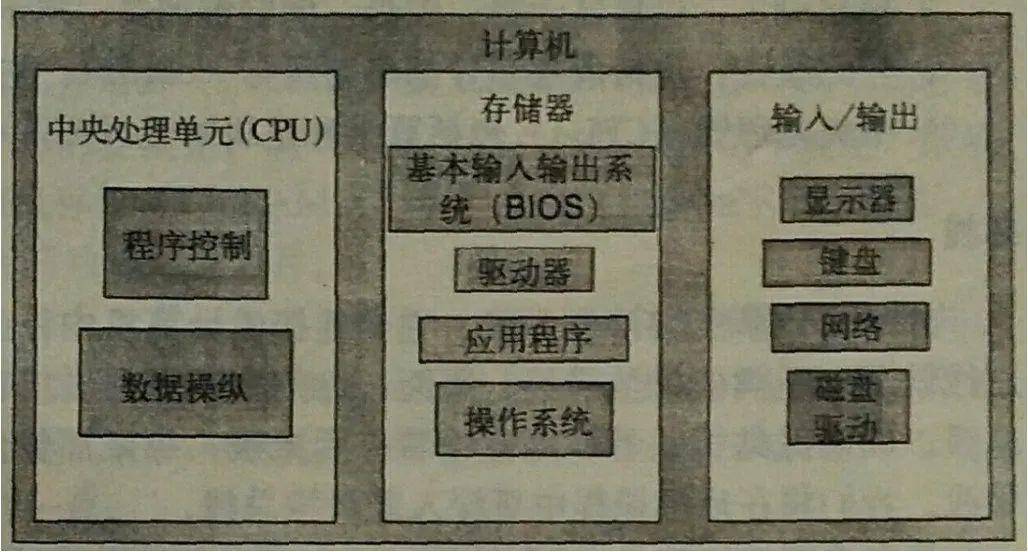
相对传统的一个负载均衡运行架构。系统建设时间比较早(2016年),没有分布式框架,就是传统的SpringMVC+MyBatis架构,并且服务器都是基于windows Server 2008的。
这套架构是出问题之前的架构,存在比较大的问题,在后续负载均衡章节会详细说明。事件过程
事件持续了一周左右,出现了好几类的严重问题。

事件造成的影响
- 公司口碑受到重大影响,此次事件公司常务副总、研发中心经理、主管全部出动,去安抚客户和解决问题(系统所在地区是沿海省会级城市,面向百姓,影响比较大)。
- 出严重问题当天,刚好有督查组来访问,碰到这个事件,机构年度考核扣了好多分。
- 后续行机构收到了大量投诉,影响了很多人考评。
9.21日上午,系统出现大面积服务假死,访问长时间没有响应。服务器网络延迟也非常严重。
分析过程
- 查看服务器发现CPU异常飙高;
- 通过jstack发现大量服务在等待中(当时时间紧迫,不允许做太多的操作,要马上恢复)。直接重启了其中一台服务器上的所有服务。
- 发现没有变化,新来的请求还是直接挂起,推测不是服务的问题;
- 检查网络状态,发现服务器的网络延迟非常严重,开始怀疑是否是网络出现问题,联系网络管理员排查发现只有我们系统所在服务器出现延迟,其他服务器都正常,并且本身服务器CPU也异常,基本排除了网络引起的原因(为什么网络会大面积延迟,后面会提起);
- 马上去查看数据库监控,发现数据库CPU和IO异常(数据库由第三方公司管理,我们前期无法直接查看,联系他们以后给的监控报告)
- 通过DBA查询数据库挂起的脚本,发现有个update请求把数据库资源全部占用了,导致其他数据库请求无法进来或者响应非常慢,从而导致服务都假死了。
经查询,发现此次操作是一个名为更新“数据实例”功能,每次升级版本需要手动操作下此功能(情况比较复杂,无法做成自动处理)。所有的历史实例数据都会存在这个表,发生事故的时候,这张表大概有1亿3千多万的数据(Oracle比较能抗,数据量不算太大),更新实例这个功能又包含了表结构调整、索引重建、数据更新等功能(业务场景需要,原则上属于每次升级操作一次就可以),所以操作的时候会锁全表。
本来这个操作是要在系统升级完成以后操作的,但是升级的时候现场人员是新人不太熟悉情况,运行过程中客户发现数据有问题,经沟通后发现少了更新实例的操作,客户催的比较急,就直接在上线期间去操作了这个功能。因为这张表是核心表,所有业务都会走这张表的,就造成所有服务都卡死了。
后来是直接重启了数据库服务器(那时候DBA已经无法干掉进程,重启服务也失败,时间比较紧迫,经过沟通以后直接重启服务器), 之后系统恢复了,整个过程大约持续了30分钟。
解决措施
- 系统优化,原来实例表是单表,数据量后续也会越来越大,就对程序做了改造,针对这张表做了分表功能(按照时间点建立分表,程序自动处理数据,自动建立分表,相应的查询统计等都做了调整);
- 增加了权限控制,更新实例功能只允许管理员角色操作;
- 强化现场实施人员培训,哪些操作是决不允许在上线期限操作的;
因为系统所在区域的业务量还算是比较庞大的,数据积累很快,所以很久以前的一些架构设计其实是存在问题的,后续针对类似这些数据表都做了相同的处理。
本来想改整体业务架构的,但是发现带来的代价太大,不仅仅涉及本身系统修改,还涉及一系列供应链上系统的修改,所以就放弃了这个方案。事件二之Tomcat内存溢出崩溃
9.21日下午,发现两个核心服务会不定时出现内存溢出,然后tomcat直接崩溃, 9.22日下午,发现另外一个服务不定期出现tomcat内存溢出问题,同样造成tomcat崩溃
做过软件的都知道,虽然异常表象是一样的,但是实际产生的原因可能是完全不一样的。分析过程
因为涉及到tomcat崩溃,在tomcat目录下产生了hs_err_pid.log日志,所以原因相对比较容易找,结合业务日志反查分析以后,就定位到了问题所在。
原因追溯死循环
9.21下午出现的两个核心服务不定时出现内存溢出,查询日志发现出问题时间段内会出现大量的服务访问日志,经过追溯代码以后,发现前端的判断逻辑存在问题,会造成服务死循环访问,即A-->B,A-->B,.....
历史原因,部分业务逻辑代码在前端进行处理,本来服务A访问成功以后,会继续访问B服务,然后B服务访问成功以后就结束了。但是这里的代码在特定条件下逻辑判断不严谨,会触发刷新服务,会一直重复访问A,B服务。模糊查询
9.22下午出现的另外一个服务内存溢出,经过同样的分析以后,发现是一个模糊查询的请求出现异常了,正常看代码没什么问题,但是分析日志以后发现,都是一些模糊条件比较简单的请求,初步怀疑是数据没做过滤,当时数据全部加载到内存里了。
因为分析的时候是上线期间,防止系统出现问题,没有直接抓出原请求去复现问题。后面是让DBA,基于查询的SQL语句,去数据库日志里查询当时的执行记录,发现这几个请求平均返回的记录数都在200万以上。至此基本上知道造成内存溢出的原因,程序里不仅仅是加载数据,还有进行数据处理的计算。
解决措施
- 第一个问题比较容易处理,程序修复就行,后续对这段代码逻辑重新进行了审计,最大限度排除逻辑上的缺陷。这些情况也整理了相应的测试用例,后续纳入常规测试计划里。
- 第二个问题处理过程比较简单,对模糊查询做了数据量返回限制,以当时的业务场景,限制返回1000条,找不到记录再输入更精确的查询条件,并简化了代码里面的逻辑运算,大部分场景移到数据库计算(不影响整体性能)。但是这个程序本身出现的问题其实比较低级,当时审计过程也存在问题,这种问题不应该出现
后面问过当事人,为什么要这么查询,一问发现还是我们自己的问题(设计不合理)。这个版本上线增加了回车查询的功能,然后客户在一个词输完以后,习惯性地会敲回车,然后触发了查询,就造成了前面的事故。比如要查询XXXX省的某个坐落门牌号,然后在输入XXXX省以后输入按了回车,就变成把全部的XXXX省数据都查询出来了。
事后公司内部小组内也进行了案例分析,其实很多开发人员对这种问题不以为然,认为不是太大的问题,就改两句代码就行。但是实际造成的后果可以对标互联网的P0级事故,这个带来的可不是人力成本上的损失,还有很多看不见的诸如口碑,信任等损失。负载均衡问题
21号-24号中间出现几次问题,其实大部分时候都是某一台服务器上的服务出现问题,但是发现负载均衡没有发挥任何作用,服务都挂掉了,请求也一直过来。
刚好周五下午也出现了更重大的事故,所以在后面就把整体策略调整了。负载均衡设备的问题也算是为我们周五的大事故转移了一些视线吧,压力相对减轻了一些
原先的运行架构图

存在的问题
- 负载均衡监测策略不对,只是针对端口做了类似te.NET测试,只要端口能访问就行,服务假死的时候,端口还是可以访问的,所以他认为服务还是正常的,请求照样过来。
- 负载均衡访问策略也不是很合理,事故前设置的按照IP哈希的方式(经询问,原先是为了会话保持,设备的访问策略也很少,只有两三种方式),当中间一台下线,请求转到另外一台以后,后续另外一台重启起来,请求就不会过来了。所以很多时候,监测会发现,两台服务器的压力差异非常大。
- 整体负载均衡方案也有问题,只做了服务器负载,系统整体架构是A-->B-->C这种形式的,如上图,策略只针对两台服务器的服务1所在端口做了负载,就是如果服务1端口没有问题,服务都会一直过来。如上图链路上服务2,服务3不管出现什么问题,请求还是照样会过来的。
厂商其实是个小代理商,设备也比较low,前期的时候也比较拽,上面的几个问题据说前期都是沟通过的,但是人不配合。做过政府信息化软件的都清楚,内部会涉及多方博弈,有时候很多问题不是技术能解决的。
这次事故也算是一件好事,至少让甲方意识到设备是有问题的,叫上了设备供应商对负载均衡各项内容进行了调整;对我们来说,甲方的炮火也适当转移了一部分,我们的压力也减轻了。解决措施
- 增加了服务监测(原来的端口监测保留,也增加其他服务的端口监测),为了不影响系统运行,我们针对每个服务额外编写了一个监测服务接口,专门用于设备配置服务监测。(因为老系统是基于jsp运行的,所以不能是html页面,需要jsp页面,返回200表示正常,其他就是异常
- 访问策略修改成轮询策略,平衡分布请求流量
- 调整程序配置,支持服务之间负载(类似分布式架构)
服务和端口监测场景

服务访问场景

所有内部服务访问都通过负载去转发,做到每个服务都高可用。
需要承担的风险:
1、高度依赖负载均衡设备的稳定性,以前请求较少,现在请求都会经过。(后面出现过一次负载扛不住压力,系统全面崩盘的情况)。
2、会话保持需要依赖于软件架构的设计,如果会话保持无法做到,此套架构无法使用
当时负载均衡策略根据上述的方式做了调整,效现场果还是不行。
当时设置完成以后,厂商才告诉我们,老的设备监测有问题了,要10分钟才会切换(好像是老设备的问题),需要更换新的设备才行。 10分钟对业务来说太长了,这种效果根本没用。
回到当时内部的多方博弈,业务部门要求换,信息部门要求我们软件供应商写一个保证,更换设备以后,系统100%不出问题。这种说法就是耍流氓了,我敢说没有一家软件公司敢说自己产品100%没有Bug,再说硬件负载切换更换,为什么要软件公司来保障。后来这个事情就不了了之了。
网上经常说的那句话,“往往最朴素的方法就是最有效的方法”,甲方后来也知道他们硬件设备不行,采用了重启大法,他们会定期(差不多一个月)的样子,重启下所有设备,后面确实没发生什么大问题了。
后来我们在公司内部完全模拟了现场的情况,采用了国内知名硬件厂商的负载均衡设备(不打品牌了,有打广告的嫌疑), 发现效果非常理想,可以达到预期的切换的效果。说明说做的策略没有任何问题。系统宕机,无法恢复
9.25下午开始,那就是灾难性的了,也是那天,所有领导齐聚现场,安抚客户。 这天出现了将近三个小时无法恢复系统,业务直接停摆。
黑色的一个星期五,我也是在这天到现场的,前面都是远程指挥的(开发负责人在现场)

整个事件莫名其妙来,莫名其妙走,从星期五晚上开始(通宵了两晚),一直到星期六半夜里吧,经过多人的头脑风暴以后,才基本确定了问题的所在。
真的找到问题以后发现过程很可笑,但是代价太惨痛
前面我们是一直在怀疑是中午12:00左右更新的代码引起的问题,因为从各种现象来说,就是更新了以后出现的问题,但是经过一个多小时的反复验证和讨论,直接排除这方面的原因,那时候就直接开玩笑说了,敢用脑袋担保新加的代码是没问题的。
后面开始翻看各种本地日志,那时候日志文件很大,好几百兆(其实这个文件大小就是有问题了,只是所有人都没意识到,为了排查方便,是每天备份清理日志的,正常业务不应该产生这么大的日志,况且这天下午基本没有业务办理,只是那时候我刚到,不了解情况,也没多想),日志非常大,加载又慢,看了一大堆无用的运行日志,没发现任何有价值的信息
快到天亮的时候,翻看了很多代码和日志,也是毫无头绪。真的是毫无头绪,连疑似的原因都找不到,本来说让性能测试组过来,看能不能复现,但是源头都没有,性能测试总不可能一个个场景压过去去找问题吧。
白天休息了一个多小时吧,起来继续工作了。
因为我属于被拉过去的,正儿八经排查代码是有其他开发负责人在的,前面我大部分时间就是跟他们头脑风暴,然后翻翻日志文件什么的。那时候潜意识也是认为应该跟代码没什么关系,还是跟环境有关系。所以第二天一早,我开始查看服务器上的部署文件,算是漫无目的吧,因为根本没头绪。
细节决定成败, 我在翻看配置文件的时候,发现同级目录下的log4j.properties文件的修改时间不正常,是25号下午17:03分,这个时间差不多就是我们最后一次重启的时间,那时候本能的反应就是这个和这次事故有关系。打开文件看了下内容,看起来很正常,日志级别也是ERROR的(我们要求生产环境不允许开启debug日志的),但是这个修改时间表明当时这个文件被覆盖过或者修改过。那时候真的,一下子来了精神,看到曙光了。
我叫上相关的所有人,开始反推当时从12:00更新开始的全过程,也把当时更新服务器的开发人员叫上,努力回想当时干了什么事情。经过将近两个多小时左右的回溯和头脑风暴,终于把事情理清楚了。
- 星期五中午的时候,开发人员更新了几个文件,其中就有log4j.properties,他自己也没注意到,然后覆盖上去的文件,是开启日志模式为Debug的。当时下午大家一团闹哄哄,他潜意识也压根联想不到这块,后来也是明确定位到这个文件,他才想起来。
- 我们重新把配置文件修改成Debug模式,然后启动服务,果然出现了当时的情况,两台服务器CPU飚高了,但是大概10几分钟以后恢复下来了,所以中午重启完以后,我们都去吃饭了,也没管服务器,那时候应该也是CPU异常,只是后续自动恢复了。(这个也很郁闷,到时如果我们能多等一会,可能就不会造成这么大的事故了)。
- 分析了下,为什么开启Debug以后会造成CPU异常,原因就是系统启动的时候tomcat控制台疯狂刷日志,导致控制台假死,进而导致服务器CPU异常系统假死(为什么会这样,后面会详细描述)。
- 而导致控制台疯狂刷日志的原因是因为会话同步的功能,因为架构比较老,并且是负载均衡,需要保持会话一直,所以采用的是Shiro+Ehcache缓存来管理会话,然后通过Ehcache来实现两台服务器的会话同步。因为会话是做了持久化+超期时间的方式,所以后续每次启动的时候都会执行会话同步的功能。
- 本来这个事情也没什么关系,但是因为业务场景需要,会话里是存了用户大部分的信息,其中就包括指纹特征码(系统支持指纹登录),然后指纹特征码是一串Base64编码的字符串,非常长,所以同步的过程中日志都输出了,在控制台疯狂滚屏,就造成了第4步描述的局面。后面关掉会话同步的功能,程序就启动正常了,不会假死,也印证了我们的猜想(单台服务启动,不一会儿也会假死,也是这个会话同步造成的)。
- 然后就是下午14:00的时候,上班高峰期为什么也会造成系统崩溃,那时候会话同步已经结束了,因为知道tomcat控制台疯狂刷日志,所以反向分析,当时应该是大量登录的场景,所以我们找了客户端打开系统,登录了下,果然发现问题了,只要一打开系统,控制台就开始疯狂刷新日志,CPU也逐渐上去了,那时候几百个客户端差不多时间登录,那就造成系统崩溃了
- 查看日志以后发现也是在刷用户信息(同会话同步),进一步排查代码以后是指纹登录功能引起的。 指纹登录的设备是甲方自己采购的,当时设备没有提供JAVA的SDK,只有JS的SDK,也就是不支持后台比对指纹,所以当时的做法是把所有用户(大几百个)的指纹信息输出到前端,然后前端根据指纹特征码循环去比较,匹配以后,找到指纹对应的用户,在进行系统登录。(客户要求直接按指纹就登录,而不是先用用户名登录,然后再指纹二次登录,所以用了比较傻瓜的方式,指纹特征码也不能直接Base64字符串比较,要根据匹配程度,然后有一套算法去匹配的。也得亏系统在内网,带宽高,不然这种玩法,老早挂了)
到此为止,基本上已经分析清楚了造成问题的原因,也一步步复现了当时系统所有的异常现象。
为什么控制台刷日志会造成CPU异常
但是最关键的问题来了,为什么控制台刷日志会造成CPU异常,这个也是阻碍我们排查问题的最大原因,我们也在自己笔记本上做了大量模拟,包括通过JMeter做压测,都没发现控制台刷日志会造成CPU异常。
其实解决过程很简单,关闭debug日志,系统基本就是正常了,但是本着刨根究底的态度,这个问题卡在这里很难受,这类问题也就独此一家吧。
因为那天甲方人也在,硬件公司也来了,聊天的过程中终于发现了问题所在。

你看的没错,运行了系统这么久的服务器居然是两台VM虚拟机。
用过虚拟机的都知道,虚拟机是公用主机的内存和CPU,是通过动态计算分配出来的,经过和专业人士交流以后,虚拟机内部很多操作都是通过软件模拟出来的,比如网络。这也解释了9.21号服务器CPU异常以后,造成网络大面积延迟。
大概的过程基本就是CMD封装刷日志-->CPU异常-->进而挂起了其他所有操作(包括网络等),等待CMD日志刷完,释放CPU以后,又恢复正常了。
因为对操作系统原理其实不是特别了解,所以也一直分析不到到底是什么情况,到时cmd刷日志占用了所有的CPU,也不给我们权限去查看VM服务端相关的日志,这个属于硬件公司管辖范围
硬件公司死活不承认VM虚拟化做服务器是有问题的,但是从我的角度看,单单就是CPU飙高,网络会出现大面积延迟就是有问题的。可能硬件公司知道猫腻吧,所以也不给我们看服务端日志,他们一直强调服务器是没问题的。
前面也讲到,回公司以后,我们搭建过一套一模一样的环境(实体机),就是怎么也复现不了控制台疯狂刷日志,造成CPU异常,系统假死的情况。总结
人的习惯就是这样,第一印象把问题都会甩给“异常输出的平台”,所以这个事件基本上由我们软件平台全部背锅了,我们事后还写了很大一份“事故总结报告”,各种“保证书”等等。
事件总结
- 工艺流程不规范,有现场操作的工艺流程,比如在不该操作的时候进行操作;质量管理流程不规范,比如代码审计不足,环境模拟不充分(模糊查询问题,公司只有几千条数据),公司没有搭建负载均衡环境测试等等;分析设计不充分,比如模糊查询的问题。
- 老系统日志系统比较欠缺,很多问题都是靠人工查看控制台或者翻阅本地log4j日志,也浪费了大量的时间。
- 突发危机处理能力不够,比如当时多等待10分钟就没问题了, 单台服务器其实可以使用的(那时候已经没有登录场景了,都已经登录过了)等等。那时候很多人堆在一起,闹哄哄七嘴八舌的,也没有冷静下来思考,导致事态严重化了。
- 应急方案没有,系统挂了就没有第二套方案去应急。
这是一次典型事件,碰到了我职业生涯没碰到过的异常,又积累了一笔经验。
大家喜欢可以关注我,每天只分享Java干货! 链接:https://juejin.cn/post/7152449257700589576