代码原来是这样被CPU跑起来的
CPU对我们来说既熟悉又陌生,熟悉的是我们知道代码是被CPU执行的,当我们的线上服务出现问题时可能首先会查看CPU负载情况。陌生的是我们并不知道CPU是如何执行代码的,它对我们的代码做了什么。本文意在简单解释我们代码的生命周期,以及代码是如何在CPU上跑起来的。
编译-让计算机认识我
一个漂亮 control+c 加上一个漂亮的 control+v,啪~,我们愉快的写下了代码,当代码被保存后,它就被存在我们磁盘的某个地方,它可能是像JAVA或者Python/ target=_blank class=infotextkey>Python这些高级语言写的,也可能是像c这种古老语言写的,但是现在它肯定没法被运行,因为计算机不认识它们,计算机只认识0、1这样的二进制,简称机器码,那为什么我们不直接写机器码?如果你有这样的思考,我只能呵呵了,请你帮我翻译下以下机器码:
001010100101001001001
100100101000101010101
复制代码
很明显作为高质量人类的我们也无法识别出这段代码写的是什么,于是出现类似java这样的高级语言,它们给机器码穿上了一层外衣,然后交给伟大的程序员来创造未来。
所以反过来我们的代码需要被替换成机器码,这样才能被计算机认识,计算机才能帮我们干事。这个转换的过程我们通常叫编译。
#include <studio.h>
int main()
{
printf("Hello Worldn");
return 0;
}
复制代码
这是一段应该每个程序员都写过的代码(hello.c),在linux下,当我们使用GCC来编译Hello World程序时,只需要最简单的命令:
gcc hello.c
./hello
# Hello World
复制代码
看似很简单的一行,但是其实编译的过程很复杂,并不是我们想象中的编译,真实是分为4个步骤,分别是预处理(Prepressing)、编译(Compliation)、汇编(Assertmbly)和链接(Linking)。
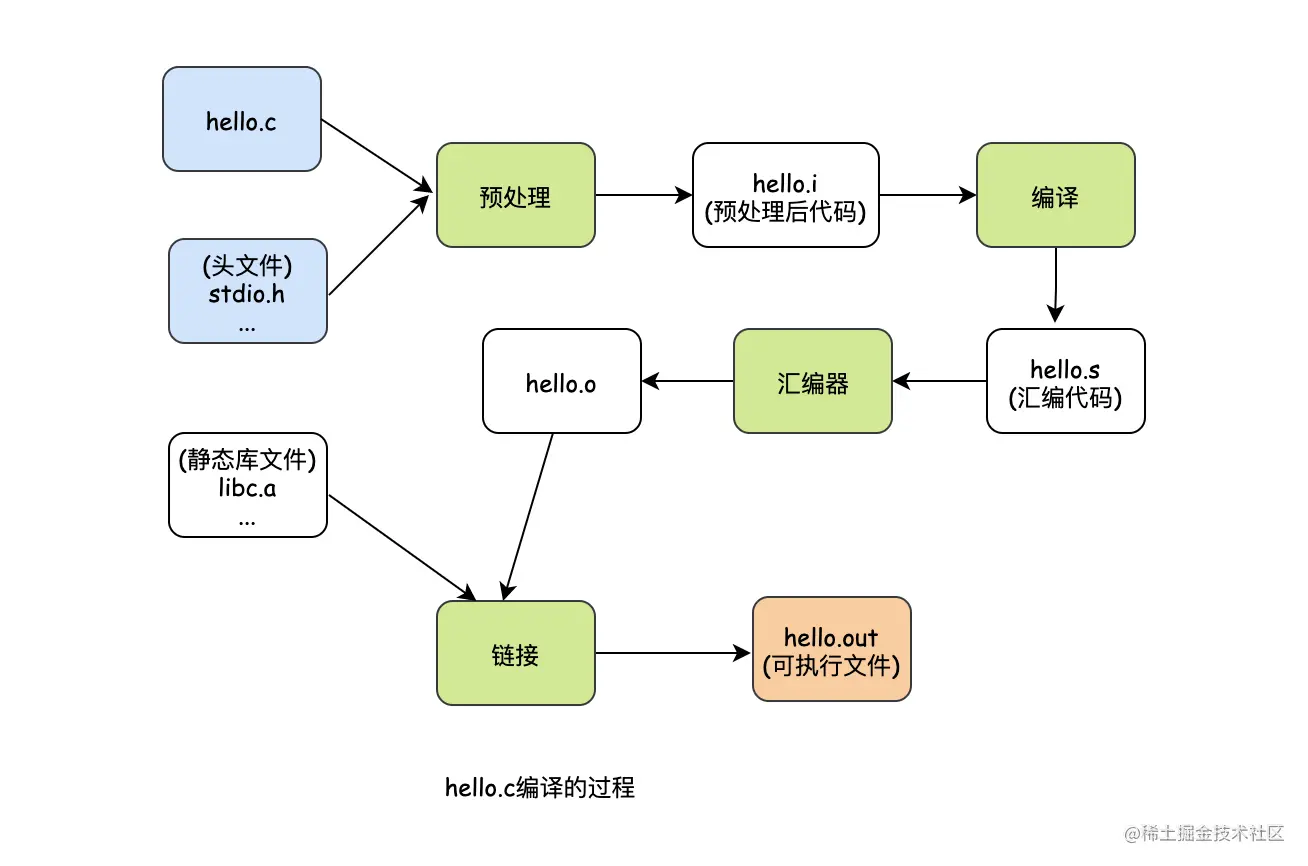
- 预编译:这个过程主要是处理源代码中以“#”开始的预编译指令,比如“#include”、“define”等。
- 编译:这个过程就是把预处理完的文件进行词法分析、语法分析、语义分析及优化后生产成相应的汇编代码,这个过程是最复杂的。
- 汇编:这个过程就是将汇编代码转换成机器码,也就是上图的目标文件hello.o
- 链接:我们的代码程序经常是由多个代码文件组成的,当每个文件都被汇编成“.o”文件时,需要一套机制将它们组装在一起,这个过程就叫做链接。
好吧,原来编译是这么回事,通过这一整套的编译操作,我们代码终于能执行了,我们简简单单的运行./hello.out即可输出Hello World。等等,这个简简单单的过程发生了什么?
连接-中转站和高速公路
ok,ok,通过编译,我们的程序终于能执行了,接下来让我们站在CPU的视角来看看Hello World是如何被打印出来的。
首先编译好的文件是存在磁盘上的,得先加载到内存中,这里你可能会问:为什么CPU不能直接读取磁盘的程序运行而要经过内存?答案是慢,缓慢的磁盘会影响我们程序执行的速度,因此需要更加快速、离CPU更近的存储,那就是内存。
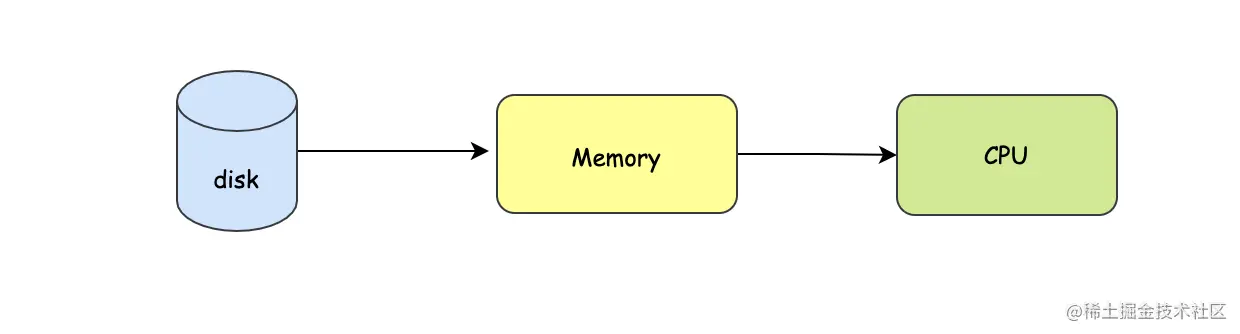
内存是一大块存储空间,可以存储很多数据信息,那么如何找到我们要写的程序呢?答案是地址,其实每个字节在内存中都有一个地址,这样当CPU去内存中读我们的程序时,只需要根据对应的地址就可以知道我们程序的具体内容。
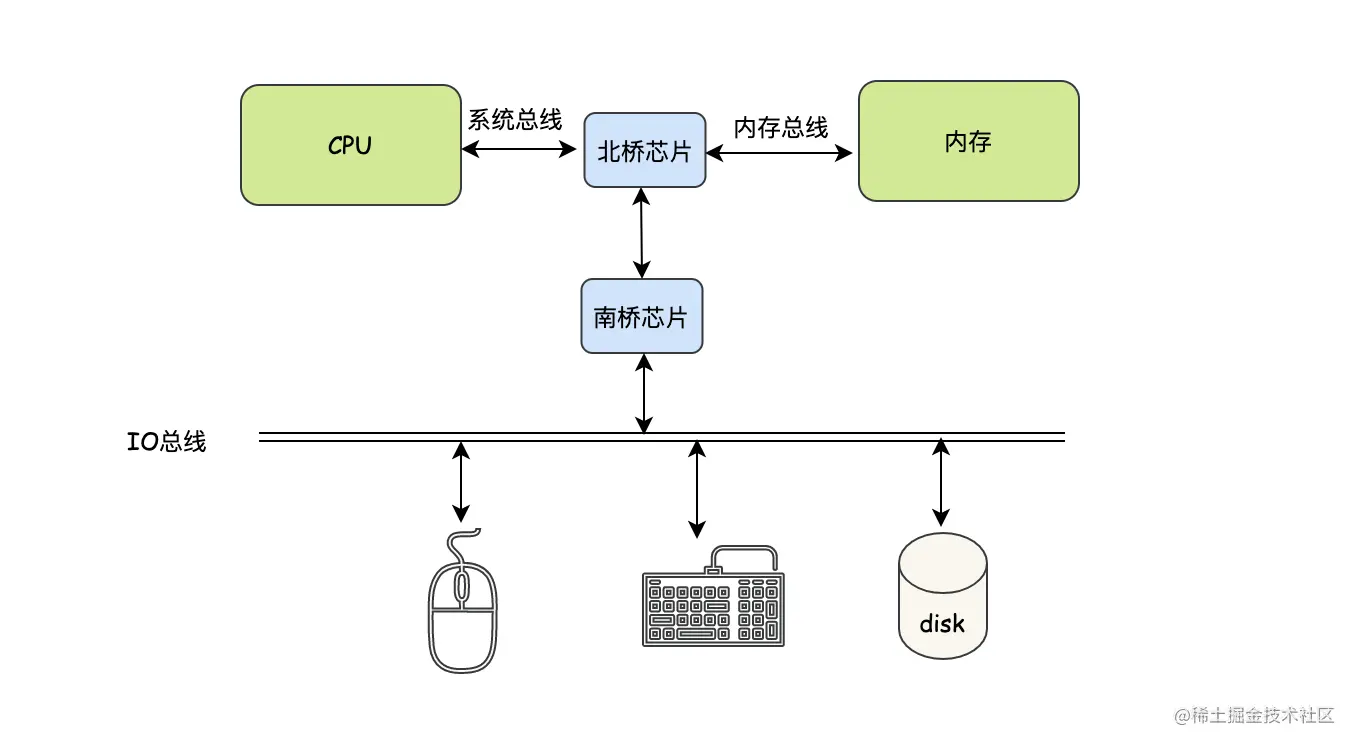
等等...,这里似乎又有个问题,CPU是如何与我们的内存、磁盘通信的?应该有个媒介之类的吧。没错,这个媒介就是主板上的总线和芯片组,总线好理解,就像高速公路,数据信息可以通过这条高速公路传递到CPU中,这个芯片组是个什么玩意?电脑主板上芯片很多,这里说的主要是南桥芯片和北桥芯片。先来个解释:
- 北桥芯片:北桥负责高速设备和CPU之间的沟通,主要就是CPU和内存、显卡之间的通信,但是随着技术的迭代,主板上的北桥芯片已经被内置到了CPU里了。
- 南桥芯片:南桥负责低速设备和北桥之间的通信,主要负责I/O总线之间的通信,如USB、LAN、ATA、SATA、音频控制器、键盘控制器、实时时钟控制器、高级电源管理等。
嗯... 为什么CPU与高速设备、低速设备之间的通信需要这两个芯片?CPU自己不能干吗?这里还是类似拆分任务的功能,如果把所有的任务都交给CPU来处理,CPU会太忙了,还有比较重要的一点,如果南桥芯片坏了,那么我们可以直接更换南桥,而不用换掉整个CPU。
终于CPU通过总线和芯片打通了磁盘、内存之间的通信了,接下来的一切开始交给CPU。
CPU-最强大脑
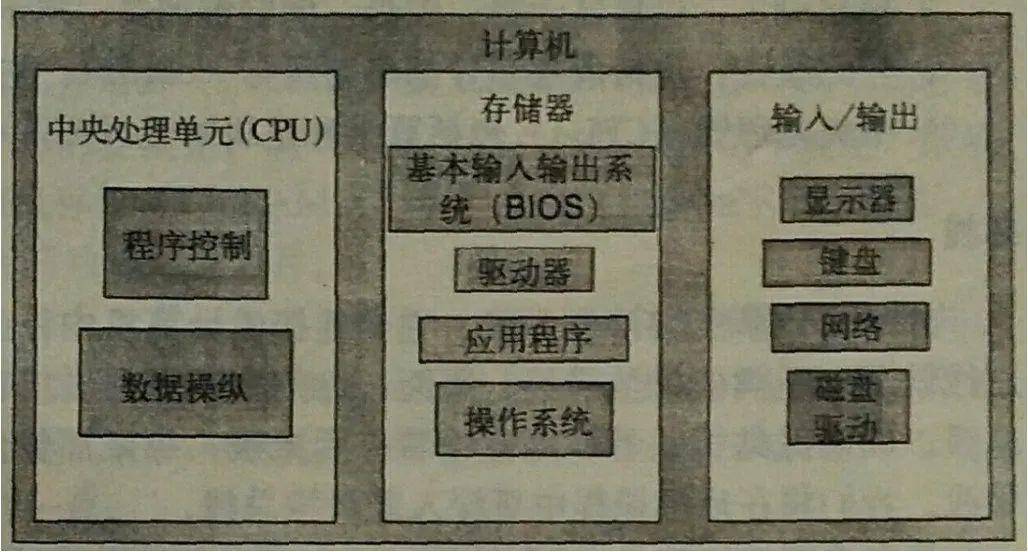
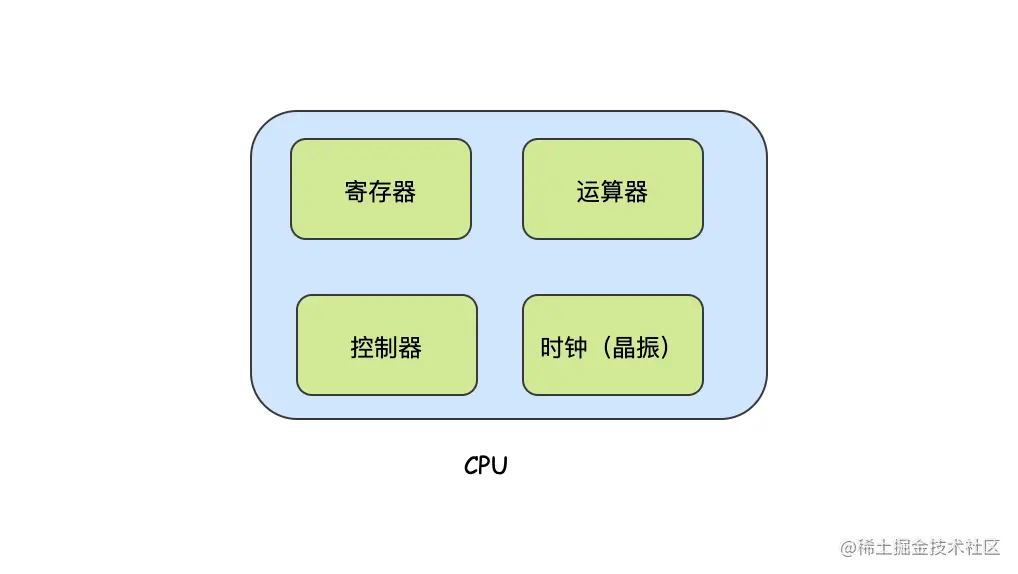
CPU全称是Central Processing Unit,即中央处理单元,它的本质就是一块超大规模的集成电路。从逻辑上来分,它的内部是由寄存器、控制器、运算器和时钟组成的,下面来解释下各个组成是干什么的。
- 寄存器:CPU内部其实有很多类型的寄存器,我们只需了解寄存器就是暂存数据、指令等信息的,它的本质是临时存储,由于是直接集成在CPU内部,所以读写它们的速度很快,一般一个CPU内部会有20-100个寄存器,这里给大家列举下常用寄存器与其功能。 累加寄存器:存储执行运算的数据和运算后的数据 标志寄存器:存储运算处理后的CPU的状态 程序计数器:存储下一条指令所在内存的地址 基址寄存器:存储数据内存的起始地址 变址寄存器:存储基址寄存器的相对地址 通用寄存器:存储任意数据 指令寄存器:存储指令,CPU内部使用,程序员无法通过程序对该寄存器进行读写操作 栈寄存器:存储栈区域的起始地址
- 控制器:控制器负责把数据读出或者写入寄存器,并根据指令的结果来控制计算机。
- 运算器:从名字就可以猜出来,运算器的主要工作就是运算,运算从内存读入寄存器的值
- 时钟:它并不是我们见的钟表概念,它代表了你的CPU的工作频率,频率越高说明你的CPU处理的速度越快,但是越快就会带来另一个问题:散热。
综上所述,CPU的大致工作流程如下:在时钟信号到来的时候,就开始工作,通过控制器把内存的数据读到各个寄存器中,然后如果有计算相关的逻辑,就交给运算器。发现没有,CPU的工作其实挺简单的,本质就是不停的读指令、执行指令。但是CPU是如何读到我们的代码指令的,以及我们的代码里面的if else、函数调用都是如何执行分支判断、函数跳转的,我们来看个例子:
a = 1 #0x0010
b = 2 #0x0011
if a > b { #0x0012
printf("%s","a") #0x0013
} else {
add(a,b) #0x0014
}
printf("%s","end") #0x0017
func add(int a,int b) { #0x0020
return a+b
}
复制代码
这是段非常简单的伪代码,有分支判断、有函数跳转。我们来从CPU的角度看看它是如何执行的:
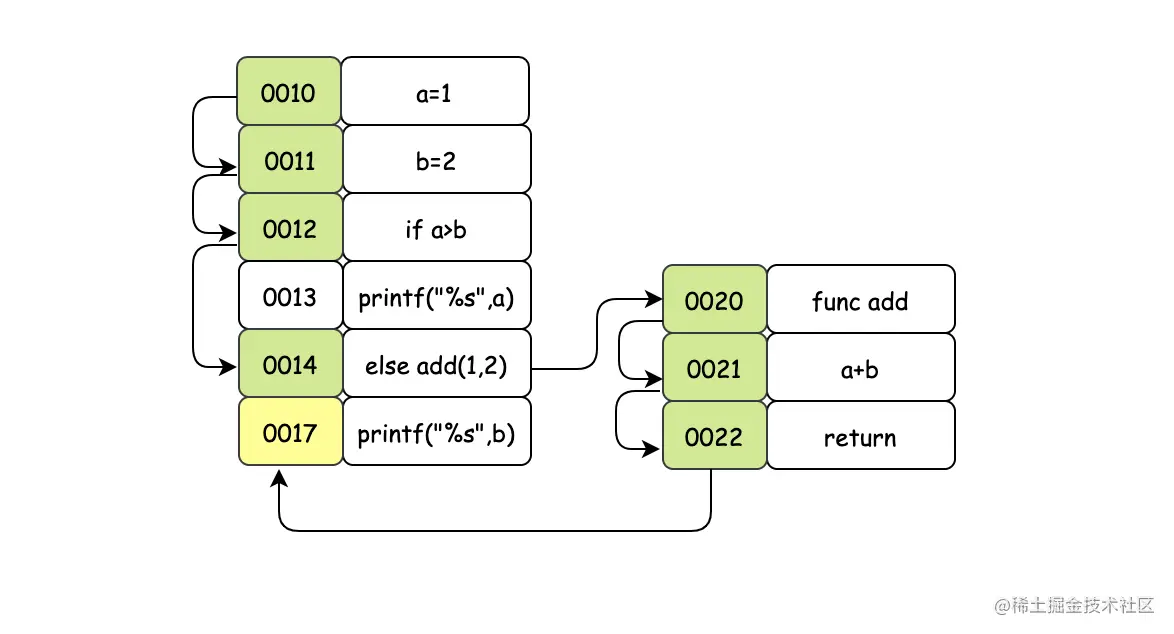
- 首先每段程序都有个开始的地址0x0010,也就是CPU读取程序的入口
- 把a=1这个数字读入通用寄存器中,程序计数器(PC寄存器)自动加1,即指向下一条指令 0x0011
- 指令寄存器拿到程序计数器的指令地址,把b=2这个数字读入通用寄存器中,程序计数器(PC寄存器)自动加1,即指向下一条指令0x0012
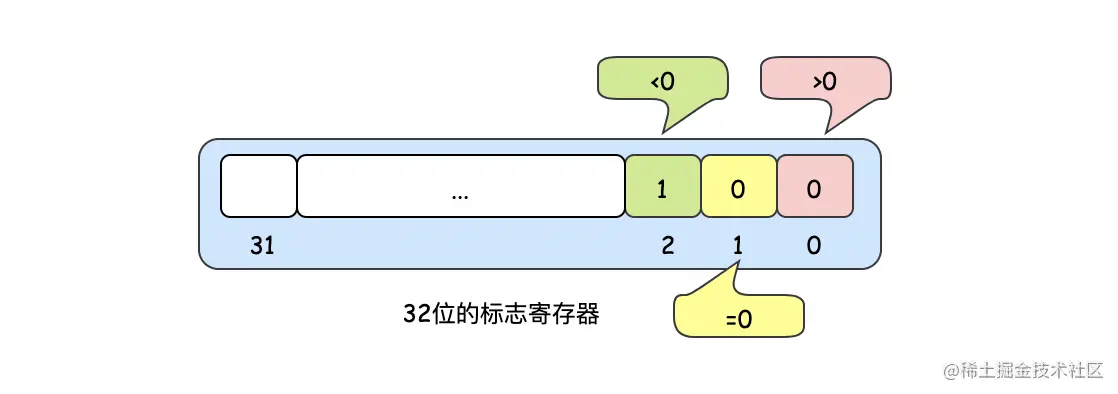
- 指令寄存器发现此处是比较逻辑,会执行a-b,此时可能会有三个结果分别是大于0,等于0,小于0,然后把这个结果存到标志寄存器里,这里有个小知识,我们经常说的是CPU是64位或者32位,其实也表示了标志寄存器的长度
- 很明显,a是小于b的,CPU根据标志寄存器的状态值应该跳转到else里面,注意这时程序计数器的值不是加1,而是设置成else的地址 0x0014,当执行到0x0015的时候,需要发生函数跳转,程序计数器会被设置成 0x0020,但是这里并不是简单的函数跳转(专业术语叫做call),因为在函数执行完毕之后,还要返回,也就是程序计数器需要从0x0020再变成0x0017。call执行的时候会把后续要执行的指令地址0x0017存到栈中。
- 当我们的add函数执行完毕之后,会有个return,return的时候会把上一步骤存入栈中的地址0x0017写入程序计数器中
- 指令寄存器根据程序计数器当前的地址执行最后的打印(end),结束。
顺序执行的指令代码,程序计数器会自动累加(当然不一定累加的是1),然后找到下一条要执行的指令。
分支判断的时候,程序计数器不是简单的累加地址,需要地址的跳转。
函数调用不仅仅需要跳转地址,还要把函数执行完毕之后要执行的地址存下来,方便折回继续执行。
其实还有个循环执行,也就是我们代码中的for、while之类的,这时程序计数器会不停的在某些地址之间来回切换。
作者:假装懂编程
链接:
https://juejin.cn/post/7022800866788950029
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。