RabbitMQ的开发应用
RabbitMQ 介绍
RabbitMQ 是一个由erlang语言编写的、开源的、在AMQP基础上完整的、可复用的企业消息系统。支持多种语言,包括JAVA、Python/ target=_blank class=infotextkey>Python、ruby、php、C/C++等。
1.1.AMQP模型
AMQP:advanced message queuing protocol ,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递的消息并不受客户端/中间件不同产品、不同开发语言等条件的限制。
AMQP模型图
1.1.1.工作过程
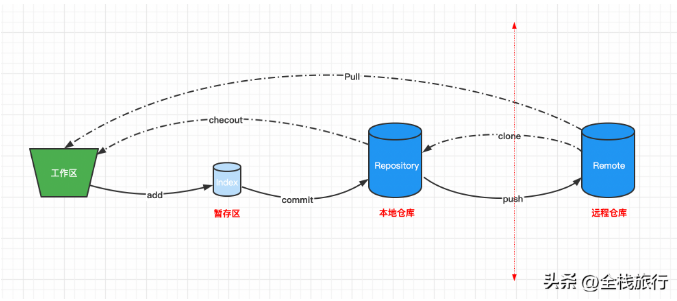
发布者(Publisher)发布消息(Message),经由交换机(Exchange)。
交换机根据路由规则将收到的消息分发给与该交换机绑定的队列(Queue)。
最后 AMQP 代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取。
1、发布者、交换机、队列、消费者都可以有多个。同时因为 AMQP 是一个网络协议,所以这个过程中的发布者,消费者,消息代理 可以分别存在于不同的设备上。
2、发布者发布消息时可以给消息指定各种消息属性(Message Meta-data)。有些属性有可能会被消息代理(Brokers)使用,然而其他的属性则是完全不透明的,它们只能被接收消息的应用所使用。
3、从安全角度考虑,网络是不可靠的,又或是消费者在处理消息的过程中意外挂掉,这样没有处理成功的消息就会丢失。基于此原因,AMQP 模块包含了一个消息确认(Message Acknowledgements)机制:当一个消息从队列中投递给消费者后,不会立即从队列中删除,直到它收到来自消费者的确认回执(Acknowledgement)后,才完全从队列中删除。
4、在某些情况下,例如当一个消息无法被成功路由时(无法从交换机分发到队列),消息或许会被返回给发布者并被丢弃。或者,如果消息代理执行了延期操作,消息会被放入一个所谓的死信队列中。此时,消息发布者可以选择某些参数来处理这些特殊情况。
1.1.2.Excharge交换机
交换机是用来发送消息的 AMQP 实体。交换机拿到一个消息之后将它路由给一个或零个队列。它使用哪种路由算法是由交换机类型和绑定(Bindings)规则所决定的。常见的交换机有如下几种:
1. direct 直连交换机:Routing Key==Binding Key,严格匹配。
2. fanout 扇形交换机:把发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中。
3. topic 主题交换机:Routing Key==Binding Key,模糊匹配。
4. headers 头交换机:根据发送的消息内容中的 headers 属性进行匹配。
具体有关这五种交换机的说明和用法,后续会有章节详细介绍。
1.1.3.Queue队列
AMQP 中的队列(queue)跟其他消息队列或任务队列中的队列是很相似的:它们存储着即将被应用消费掉的消息。队列跟交换机共享某些属性,但是队列也有一些另外的属性。
· Durable(消息代理重启后,队列依旧存在)
· Exclusive(只被一个连接(connection)使用,而且当连接关闭后队列即被删除)
· Auto-delete(当最后一个消费者退订后即被删除)
· Arguments(一些消息代理用它来完成类似与 TTL 的某些额外功能)
1.2.rabbitmq和kafka对比
rabbitmq遵循AMQP协议,用在实时的对可靠性要求比较高的消息传递上。kafka主要用于处理活跃的流式数据,大数据量的数据处理上。主要体现在:
1.2.1.架构
1. rabbitmq:RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心。
2. kafka:kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据。
1.2.2.消息确认
1. rabbitmq:有消息确认机制。
2. kafka:无消息确认机制。
1.2.3.吞吐量
1. rabbitmq:rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
2. kafka:kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
(备注:kafka零拷贝,通过sendfile方式。(1)普通数据读取:磁盘->内核缓冲区(页缓存 PageCache)->用户缓冲区->内核缓冲区->网卡输出;(2)kafka的数据读取:磁盘->内核缓冲区(页缓存 PageCache)->网卡输出。
1.2.4.可用性
1. rabbitmq:(1)普通集群:在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据。完了你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。(2)镜像集群:跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。这样的话,好处在于,一个机器宕机了,没事儿,别的机器都可以用。坏处在于,第一,这个性能开销太大了,消息同步所有机器,导致网络带宽压力和消耗很重。第二,这么玩儿,就没有扩展性可言了,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue
2. kafka:kafka是由多个broker组成,每个broker是一个节点;每创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。这就是天然的分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。每个partition的数据都会同步到其他机器上,形成自己的多个replica副本,然后所有replica会选举一个leader出来,主从结构。
1.2.5.集群负载均衡
1. rabbitmq:rabbitMQ的负载均衡需要单独的loadbalancer进行支持,如HAProxy和Keepalived等。
2. kafka:kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
2.结构
2.1.交换机模式
RabbitMQ常用的Exchange Type有fanout、direct、topic、headers这四种。
2.1.1.Direct Exchange
direct类型的Exchange路由规则很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中。
2.1.2.Topic Exchange
前面讲到direct类型的Exchange路由规则是完全匹配binding key与routing key,但这种严格的匹配方式在很多情况下不能满足实际业务需求。topic类型的Exchange与direct类型的Exchage相似,也是将消息路由到binding key与routing key相匹配的Queue中,但支持模糊匹配:
· routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”
· binding key与routing key一样也是句点号“. ”分隔的字符串
· binding key中可以存在两种特殊字符"*"与“#”,用于做模糊匹配,其中" * "用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
2.1.3.Fanout Exchange
fanout类型的Exchange路由规则非常简单,它会把所有发送到fanout Exchange的消息都会被转发到与该Exchange 绑定(Binding)的所有Queue上。
Fanout Exchange 不需要处理RouteKey 。只需要简单地将队列绑定到exchange 上。这样发送到exchange的消息都会被转发到与该交换机绑定的所有队列上。类似子网广播,每台子网内的主机都获得了一份复制的消息。所以,Fanout Exchange 转发消息是最快的。
2.1.4.Headers Exchange
headers类型的Exchange也不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定Queue与Exchange时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。
2.1.5.Default Exchange 默认
严格来说,Default Exchange 并不应该和上面四个交换机在一起,因为它不属于独立的一种交换机类型,而是属于Direct Exchange 直连交换机。
默认交换机(default exchange)实际上是一个由消息代理预先声明好的没有名字(名字为空字符串)的直连交换机(direct exchange)。
它有一个特殊的属性使得它对于简单应用特别有用处:那就是每个新建队列(queue)都会自动绑定到默认交换机上,绑定的路由键(routing key)名称与队列名称相同。
举个例子:当你声明了一个名为 “search-indexing-online” 的队列,AMQP 代理会自动将其绑定到默认交换机上,绑定(binding)的路由键名称也是为 “search-indexing-online”。所以当你希望将消息投递给“search-indexing-online”的队列时,指定投递信息包括:交换机名称为空字符串,路由键为“search-indexing-online”即可。
因此 direct exchange 中的 default exchange 用法,体现出了消息队列的 point to point,感觉像是直接投递消息给指定名字的队列。
2.2.持久化
虽然我们要避免系统宕机,但是这种“不可抗力”总会有可能发生。rabbitmq如果宕机了,再启动便是了,大不了有短暂时间不可用。但如果你启动起来后,发现这个rabbitmq服务器像是被重置了,以前的exchange,queue和message数据都没了,那就太令人崩溃了。不光业务系统因为无对应exchange和queue受影响,丢失的很多message数据更是致命的。所以如何保证rabbitmq的持久化,在服务使用前必须得考虑到位。
持久化可以提高RabbitMQ的可靠性,以防在异常情况(重启、关闭、宕机等)下的数据丢失。RabbitMQ的持久化分为三个部分:交换器的持久化、队列的持久化和消息的持久化。
2.2.1.exchange持久化
exchange交换器的持久化是在声明交换器的时候,将durable设置为true。
如果交换器不设置持久化,那么在RabbitMQ交换器服务重启之后,相关的交换器信息会丢失,不过消息不会丢失,但是不能将消息发送到这个交换器。
spring中创建exchange时,构造方法默认设置为持久化。
2.2.2.queue持久化
队列的持久化在声明队列的时候,将durable设置为true。
如果队列不设置持久化,那么RabbitMQ交换器服务重启之后,相关的队列信息会丢失,同时队列中的消息也会丢失。
exchange和queue,如果一个是非持久化,另一个是持久化,中bind时会报错。
spring中创建exchange时,构造方法默认设置为持久化。
2.2.3.message持久化
要确保消息不会丢失,除了设置队列的持久化,还需要将消息设置为持久化。通过将消息的投递模式(BasicProperties中的deliveryMode属性)设置为2即可实现消息的持久化。
· 持久化的消息在到达队列时就被写入到磁盘,并且如果可以,持久化的消息也会在内存中保存一份备份,这样可以提高一定的性能,只有在内存吃紧的时候才会从内存中清除。
· 非持久化的消息一般只保存在内存中,在内存吃紧的时候会被换入到磁盘中,以节省内存空间。
如果将所有的消息都进行持久化操作,这样会影响RabbitMQ的性能。写入磁盘的速度比写入内存的速度慢很,所以要在可靠性和吞吐量之间做权衡。
在spring中,BasicProperties中的deliveryMode属性,对应的是MessageProperties中的deliveryMode。平时使用的
RabbitTemplate.convertAndSend()方法默认设置为持久化,deliveryMode=2。如果需要设置非持久化发送消息,需要手动设置:
messageProperties.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT);
2.2.4.完整方案
一、exchange、queue、message
要保证消息的持久化,在rabbitmq本身的结构上需要实现下面这些:
exchange交换机的durable设置为true。
queue队列的durable设置为true。
message消息的投递模式deliveryMode设置为2。
二、发布确认
前面是保证了消息在投递到rabbitmq中,如何保证rabbit中消息的持久化。
那么还需要保证生产者能成功发布消息,如交换机名字写错了等等。可以在发布消息时设置投递成功的回调,确定消息能成功投递到目标队列中。
三、接收确认
对于消费者来说,如果在订阅消息的时候,将autoAck设置为true,那么消费者接收到消息后,还没有处理,就出现了异常挂掉了,此时,队列中已经将消息删除,消费者不能够在收到消息。
这种情况可以将autoAck设置为false,进行手动确认。
四、镜像队列集群
在持久化后的消息存入RabbitMQ之后,还需要一段时间才能存入磁盘。RabbitMQ并不会为每条消息都进行同步存盘,可能仅仅是保存到操作系统缓存之中而不是物理磁盘。如果在这段时间,服务器宕机或者重启,消息还没来得及保存到磁盘当中,从而丢失。对于这种情况,可以引入RabiitMQ镜像队列机制。
这里强调是镜像队列集群,而非普通集群。因为出于同步效率考虑,普通集群只会同步队列的元数据,而不会同步队列中的消息。只有升级成镜像队列集群后,才能也同步消息。
每个镜像队列由一个master和一个或多个mirrors组成。主节点位于一个通常称为master的节点上。每个队列都有自己的主节点。给定队列的所有操作首先应用于队列的主节点,然后传播到镜像。这包括队列发布(enqueueing publishes)、向消费者传递消息、跟踪消费者的确认等等。
发布到队列的消息将复制到所有镜像。不管消费者连接到哪个节点,都会连接到master,镜像会删除在master上已确认的消息。因此,队列镜像提高了可用性,但不会在节点之间分配负载。 如果承载队列master的节点出现故障,则最旧的镜像将升级为新的master,只要它已同步。根据队列镜像参数,也可以升级为同步的镜像。