大脑如何储存长期记忆、检索回忆、做决策?这些大脑的运行机制值得AI学习

图片来源@视觉中国
文 | 追问NextQuestion
大脑是宇宙中已知的,也可能是唯一的“智能机器”。
在行为学层面,人与动物的大脑能执行精细的、高水平的认知任务,包括灵活学习、长时程记忆、开放式环境决策等。在结构层面,认知与计算神经科学揭示了大脑通过极其复杂而精细的网络实现其功能。北京大学心理与认知科学学院吴思教授与清华大学社会科学院心理学系的刘嘉教授等人在今年1月发表的“AI of Brain and Cognitive Sciences: From the Perspective of First Principles”一文中提到,随着人类对大脑的结构与功能的认识不断深化,大脑的基本原理为改进人工智能提供了最重要的参考。这些基本原理指大脑提取、表征、处理、检索信息的规则,它们指引着大脑的运行,是大脑执行其他更高级认知功能的基础。
论文作者们将大脑的基本原理概括为:吸引子网络、临界性、随机网络、稀疏编码、关系记忆、感知学习。解读这些原理,并将其灵活用于人工智能,可能是使人工智能更“像”人类智能,并在性能上获得进一步提升的关键。
本次追问邀请了四位认知神经科学领域的青年学者基于这篇重要论文对“人工智能如何向人类智能学习?”的话题进行了解读。本次解读将分上中下三篇,从以上六个方面与您一起揭秘大脑的基本原理。

▷图 1:论文封面
吸引子动力学:神经信息处理的规范模型
大脑由大量神经元组成,神经元之间通过突触形成各种网络。单个神经元的计算相当简单,而神经网络的动态变化才是完成大脑功能的关键。简单地说,神经网络接收来自外部世界和其他脑区的输入,其状态不断变化,从而进行信息处理。因此,动态系统理论是量化大脑如何通过网络进行计算的重要数学工具。
在动力学系统中,不同的状态演化规则和多样的外部输入可以产生各种动态学现象。在一个神经网络里,如果一个状态向量(state vector)的所有邻近状态都汇聚于它,那么这个状态向量就被称为稳定吸引子(stable attractor)。拥有稳定吸引子的网络被称为吸引子网络(attractor.NETwork),它们构成了大脑信息表征、处理和检索的基本构建模块。具有稳定状态的吸引子网络可分为两种类型,即离散吸引子网络(discrete attractor network)和连续吸引子网络(continuous attractor network)。在神经网络中,吸引子对应网络的能量空间中的局部最小值,所有邻近状态的能量都高于它,所以会被“吸引”到这里(图1)。
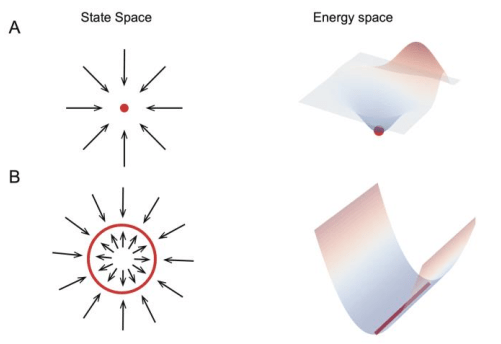
▷图 1:离散吸引子网络和连续吸引子网络示意图。图源:参考文献1
在离散吸引子网络中,每个吸引子都有自己的吸引区域。如果以随机状态开始,网络的动态性会驱动随机状态向其邻近吸引子状态变化,这个过程也伴随着网络的能量降低。离散吸引子的这种特性使得网络能够纠正输入噪声并检索记忆表征。现在,离散吸引子网络经常用于模拟工作记忆、长期记忆和决策等。
与离散吸引子网络不同,在连续吸引子神经网络(continuous attractor neural networks,CANN)中,吸引子在状态空间中连续分布,形成一个平滑的流形。这个特性使得CANN中的吸引子状态能够迅速转变。它为CANN带来了许多潜在的利用价值,如路径积分、证据累积、预测性跟踪等。
已经有很多实验研究证明大脑中存在吸引子动力学,并且吸引子网络常被用于描述一些高级认知功能的潜在机制,这有赖于其在信息表征中的基本特性。
- 特征一:吸引子网络稳健的信息表征2
在离散吸引子网络中,记忆信息被存储为一个吸引子状态。在给定部分或有噪声线索的情况下,网络会动态演化到一个吸引子状态,并且相应的记忆会被检索出来。不同的吸引子对应于不同的局部能量最小值,并且有着各自的吸引域。如果噪声扰动不足以将网络状态推出吸引域,那么吸引子状态就是稳定的,所以记忆信息被稳健地编码。
与离散吸引子网络不同,在连续吸引子网络中,吸引子在网络状态空间中形成一个平坦的流形,并且它们对噪声有部分的稳健性。如果噪声扰动与流形正交,网络状态在吸引子动力学作用下是稳定的。然而,如果噪声扰动沿着流形方向,网络状态将在吸引子流形上扩散,从一个吸引子移动到附近的吸引子。
- 特征二:吸引子网络的记忆容量
记忆容量指的是能够可靠地存储在吸引子网络中的记忆数量。吸引子网络的记忆容量受到几个因素的影响。其一是噪声,当网络中存储了过多的记忆时,每个吸引子的吸引域会缩小,从而降低了吸引子对噪声的容忍度。另一个因素是记忆相关性,当记忆模式高度相关时,它们会相互干扰,破坏记忆的检索。为了增加吸引子网络的记忆容量,人们已经提出了许多方法,从学习规则到网络结构,如基于新奇性的赫布规则(Hebbian rule)3和模块化霍普菲尔德网络(Hopfield network)4。
- 特征三:吸引子网络的信息检索
除了具有大容量的记忆能力外,一个优秀的信息处理系统还需要高效的信息搜索能力。在吸引子网络中,记忆通常以内容寻址方式进行检索,即网络通过吸引子动态执行相似性计算,检索出与线索最相似的记忆。
在大容量网络中,从众多吸引子中找到正确的一个是具有挑战性的。例如,在一个自由记忆检索任务中,参与者需要尽可能多地搜索和回忆动物的名称。一个良好的回忆策略是在局部记忆搜索与记忆空间大跳跃之间合适地组合,表现出莱维飞行行为*。董行思等人证明,在一个带有噪声神经适应的CANN中,网络状态的动态显示出交替的局部布朗运动和长跳跃运动,呈现出莱维飞行的最佳信息搜索行为5。
*编辑注:莱维飞行行为(Levy flight behavior)是一种随机行为模式,其中个体在一定时间内以不规则的方式移动,具有长尾分布的步长。这种行为模式以法国数学家Paul Lévy的名字命名。莱维飞行行为与传统的随机行走模型(如布朗运动)不同,后者通常假设步长是固定的,而莱维飞行行为中的步长是从长尾分布中随机抽取的,因此具有更大的变化范围。
- 特征四:吸引子网络间的信息整合
吸引子网络还可以相互交互,实现信息整合。张文昊等人研究了如何通过相互连接的CANN来实现多感官信息处理6, 7。在他们的模型中,每个模块包含两组神经元,每组神经元形成一个CANN,这些神经元的调谐函数相对于模态输入要么是一致的,要么是相反的。该研究证明,具有一致神经元的耦合CANN可以实现信息整合,而具有相反神经元的耦合CANN可以实现信息分离,它们之间的相互作用能够有效地实现多感官整合和分离。这项研究表明,相互连接的吸引子网络可以支持不同脑区之间的信息传递。
最近,在全球范围内的技术进步和大型脑项目的推动下,大量关于脑结构细节和神经活动的数据正在涌现,现在是建立大规模网络模型来模拟更高级认知功能的时机。作为神经信息处理的规范模型,吸引子网络成为人们开展这一任务的基本构建模块,人工智能也可以借助这一基本模块,在信息处理和表征方面受到一些启发。
根据全局工作空间理论(global neuronal workspace theory)*,大脑分为一个共享的全局处理模块和许多分布式的专门处理模块8。每个独特的模块处理来自一个模态(如视觉、听觉、嗅觉或运动系统)的信息。相反,全局模块接收并整合来自所有专门模块的信息,并将整合后的信息“广播”回这些局部模态。为了实现这个目标,需要一个抽象的信息表示接口,允许不同模块之间进行通信。从这个意义上说,已经在实验和理论研究中被证明是规范模型的CANN,自然地成为了在模块之间表示、转换、整合和广播信息的统一框架。在未来的研究中,探索这个问题将是非常有趣的。
*编辑注:全局工作空间理论或全局工作空间模型是1988年心灵哲学家巴尔斯(B. J. Baars)首次提出的运用语境论解释意识运行的基本规则的模型。假设意识与一个全局“广播系统”相联系,该系统在整个大脑中发布信息,包括三个部分:专门处理器、全局工作空间和语境。专门处理器是无意识的,可能是一个单一的神经元,也可能是整个神经网络。
临界性:为大脑和人工智能带来新的视角
临界性(criticality)的框架是理解和分析复杂系统的强大工具,因为许多物理和自然系统处于临界状态。在过去的20年里,研究人员发现大脑中的生物神经网络的运行接近临界状态,这为研究脑部动态提供了新的视角。已知临界状态对脑部的活动/功能非常重要,因为它优化了信息传输、存储和处理的许多方面。在人工智能领域,临界状态的框架被用于分析和指导深度神经网络的结构设计和权重初始化,表明运行接近临界状态可被视为神经网络计算的基本原则之一。
在统计物理学中,一个具有相同物理和化学特性的材料系统中的均质状态被称为相(phase)。例如,水可以处于固相、液相或气相。当温度变化时,水可以从一个相变为另一个相,这被称为相变(phase transition)。临界状态表明系统正在从有序相向无序相转变。在有序和无序的边缘,或者称为“混沌边缘”,临界状态表现出许多特殊的属性。

▷图 2:蒙特卡洛模拟伊辛模型。图源:参考文献9
图2通过伊辛模型的模拟展示了铁磁材料的相变过程和临界状态9。在伊辛模型中,自旋相互作用和热运动的竞争导致了有序相和无序相。图2a和2c分别显示了低温下的有序相和高温下的无序相。在相变边缘的温度下,如图2b所示,有序和无序处于平衡状态,两者都无法主导整个系统。在这个温度下,系统变得极其复杂,处于所谓的临界状态。
在有序相或无序相中,领域大小的分布集中在较大或较小的尺寸上,而在临界状态下,领域大小几乎分布在所有尺寸上。而且不同尺度上的分布是自相似的,这意味着这些分布是分形和无标度的。这种自相似分布在数学上可形式化为幂律(power law)10:
![]()
。如果使用对数-对数坐标系,分布将呈现为一条直线。幂律分布是临界状态的一个重要特征。
除了通过精确调节伊辛模型中的温度或其他系统中的控制参数来达到临界状态外,有些系统还能自发地达到临界状态,这被称为自组织临界性(self-organized criticality,SOC)。在过去的二十年中,通过记录体外培养的脑组织或体内完整大脑的神经元活动,许多实验表明大脑皮层网络也能够自组织成临界状态。
在大脑的皮层网络中,每个神经元通过突触连接接收来自大量周围神经元的输入。当输入达到其阈值时,将产生动作电位,该电位将传递给其他神经元,导致其他神经元发放动作电位。Beggs和Plenz通过多电极阵列记录大脑组织的活动首次确认了关于临界大脑的猜测11。他们发现神经元雪崩的大小和持续时间都服从幂律分布,这是临界状态的一个重要特征。随后,其他研究人员记录了不同物种的不同脑皮层在清醒和麻醉状态下的神经元活动,都再次证实了在网络的自发活动中神经元雪崩呈幂律分布12。这表明,大脑网络在临界状态附近运行是一个普遍特征,而兴奋性和抑制性的平衡在维持临界状态方面起着关键作用。
鉴于临界状态在包括神经系统在内的许多复杂系统分析中的成功应用,一些研究人员还尝试将临界状态应用于研究人工神经网络,例如,改进储层计算和增强深度神经网络的性能。
储层计算(reservoir computing,RC)通常指的是递归神经网络(recurrent neural network,RNN)的一种特殊计算框架,其中可训练的参数仅存在于最终的输出层,即非递归的输出层,而所有其他参数则是随机初始化并在后续计算中保持固定状态。目前,RC模型已成功应用于许多计算问题,例如时序模式分类、识别、预测和动作序列控制等任务。RC模型仅在网络处于临界状态时表现良好,有时也被称为“回声状态(echo state)”。受生物神经网络中的短时突触可塑性(short-term synaptic plasticity,STP)的启发,曾冠雄等人在RC模型中实现了一种SOC方案,通过短时抑制(short-term depression,STD)来调整RNN的状态,使其接近临界状态13。STD大大增强了神经网络的稳健性,使其能够适应长期的突触变化,同时保持由临界状态赋予的最佳性能。它还提示了大脑在不同时间尺度上组织可塑性的潜在机制,在允许用于学习和记忆所需的内部结构变化的同时,维持信息处理的最佳状态(临界状态)。
除此之外,临界状态对于增强深度神经网络的性能也有启示作用。深度神经网络相较于浅层网络取得了巨大的成功。为了在理论上解释这一现象,Poole等人将黎曼几何与高维混沌的均场理论相结合,揭示出深度随机网络中逐渐增加的深度与混沌状态(临界状态)的瞬时变化之间存在指数级表达能力的关系14。此外,他们证明这个特性在浅层网络中是不存在的。这一发现对网络的结构设计具有重要意义,为现有深度神经网络的卓越性能提供了理论基础。但是,目前关于临界状态是否总是有益的问题仍然是一个未解之谜。
临界状态为人们研究生物和人工神经网络提供了一种全新的视角。目前,临界性的框架不仅被用于理解神经动态和脑部疾病,还被用于分析深度神经网络的运行并指导进一步的改进设计。在更好地理解应用于人工神经网络的约束条件,以及设计更好的体系结构和动态规则来提高人工神经网络在复杂信息处理中的性能方面,临界性的框架将发挥更加重要的作用。
未完待续......
参考文献:
- 1. Luyao Chen, Z.C., Longsheng Jiang, Xiang Liu, Linlu Xu, Bo Zhang, Xiaolong Zou, Jinying Gao, Yu Zhu, Xizi Gong, Shan Yu, Sen Song, Liangyi Chen, Fang Fang, Si Wu, Jia Liu, AI of Brain and Cognitive Sciences: From the Perspective of First Principles. arXiv, 2023. 2301.08382.
- 2. Lim, S. and M.S. Goldman, Balanced cortical microcircuitry for maintaining information in working memory. Nat Neurosci, 2013. 16(9): p. 1306-14.
- 3. Blumenfeld, B., et al., Dynamics of memory representations in networks with novelty-facilitated synaptic plasticity. Neuron, 2006. 52(2): p. 383-94.
- 4. Liu, X., et al., Neural feedback facilitates rough-to-fine information retrieval. Neural Netw, 2022. 151: p. 349-364.
- 5. Xingsi Dong, T.C., Tiejun Huang, Zilong Ji, Si Wu, Noisy Adaptation Generates Lévy Flights in Attractor Neural Networks. Advances in Neural Information Processing Systems, 2021. Dec 6;34:16791-804.
- 6. Zhang, W.H., et al., Decentralized Multisensory Information Integration in Neural Systems. J Neurosci, 2016. 36(2): p. 532-47.
- 7. Zhang, W.H., et al., Complementary congruent and opposite neurons achieve concurrent multisensory integration and segregation. Elife, 2019. 8.
- 8. Mashour, G.A., et al., Conscious Processing and the Global Neuronal Workspace Hypothesis. Neuron, 2020. 105(5): p. 776-798.
- 9. Mcmillan, W.L., Monte-Carlo Simulation of the Two-Dimensional Random (+/-J) Ising-Model. Physical Review B, 1983. 28(9): p. 5216-5220.
- 10. Clauset, A., C.R. Shalizi, and M.E.J. Newman, Power-Law Distributions in Empirical Data. Siam Review, 2009. 51(4): p. 661-703.
- 11. Beggs, J.M. and D. Plenz, Neuronal avalanches in neocortical circuits. Journal of Neuroscience, 2003. 23(35): p. 11167-11177.
- 12. Shew, W.L., et al., Neuronal Avalanches Imply Maximum Dynamic Range in Cortical Networks at Criticality. Journal of Neuroscience, 2009. 29(49): p. 15595-15600.
- 13. Zeng, G.X., et al., Short-term synaptic plasticity expands the operational range of long-term synaptic changes in neural networks. Neural Networks, 2019. 118: p. 140-147.
- 14. Poole, B., et al., Exponential expressivity in deep neural networks through transient chaos. Advances in Neural Information Processing Systems 29 (Nips 2016), 2016. 29.