GPT太「奢侈」,平替大汇总来了,再也不用担心部署大难题
近年来,生成式预训练模型(如 GPT)的兴起彻底颠覆了自然语言处理领域,其影响甚至已经延伸到其他多种模态。然而,像 ChatGPT 和 GPT-4 这样的模型,由于其巨大的模型规模与计算复杂度、复杂的部署方式以及未开源的训练模型,这些因素都限制了他们在学术界和工业界的推广与应用。因此,易于计算和部署的语言模型成为了人们关注的焦点。

- 论文地址:http://arxiv.org/abs/2308.14149
- 项目地址:https://Github.com/GPT-Alternatives/gpt_alternatives
本文将从以下几个方面,对 GPT 的平替模型进行研究,从多个维度出发,进行大量实验验证,只为得到更全面更真实的模型测评结果,帮助研究者和从业者更加深入地理解这些模型的基本原理、发展趋势和主要的挑战,并且根据不同需求选择合适的模型。
2. 梳理了现有的公开数据集并分析了预训练数据源、数据质量、数量、多样性、微调数据(包括指令数据、对齐数据),以及特定领域数据的特点;
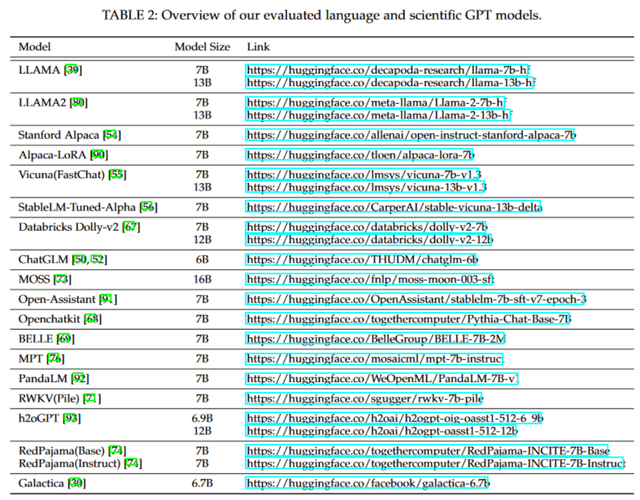
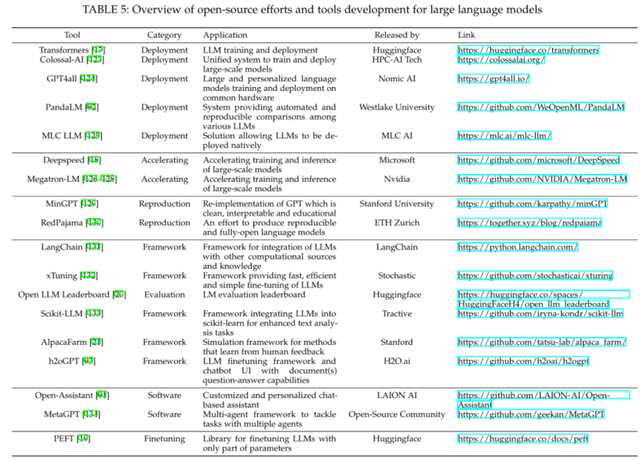
3. 介绍了高效训练与部署大规模语言模型的方式,并总结了现有的开源平替模型;
4. 评测了不同平替模型在多个常用基准数据集上的效果;
5. 设计了人工评测任务,并在不同平替模型上进行了人工评估;
6. 讨论和评测了大规模语言模型在图文多模态领域的研究现状及模型表现;
7. 评测了各个平替模型在科学研究领域的基准数据集上的性能。
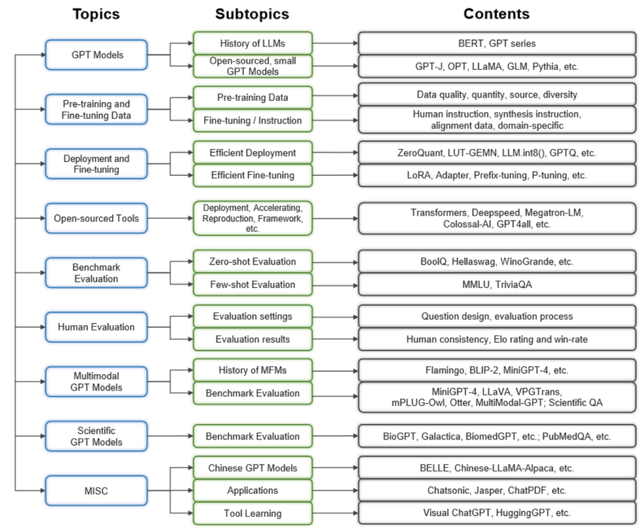
大规模语言模型发展历程
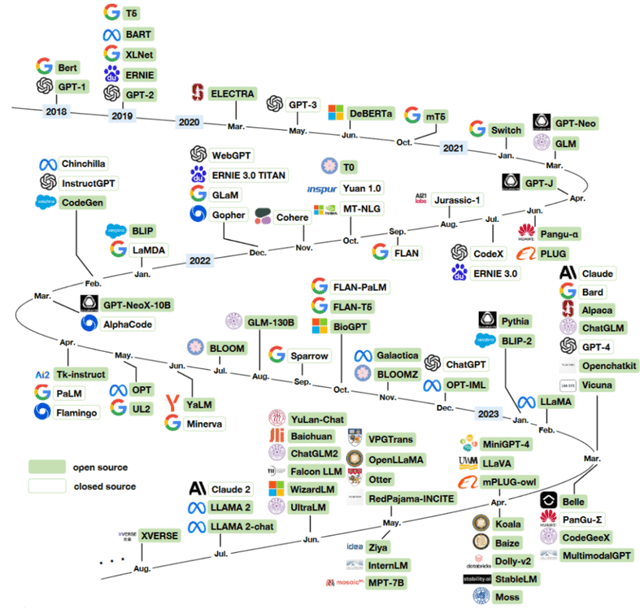
GPT 的平替模型
持续更新在 github……
开源工具
近年来,深度学习的飞速发展与开源社区的繁荣息息相关。本节中,我们整理了大规模语言模型相关的开源工具库,这些工具库包含了训练、部署、加速、模型评测等方面。
基准数据集评测
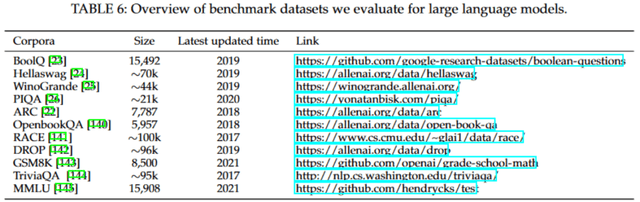
为了全面评估各种语言模型在不同任务上的性能,我们首先从不同角度在多个常用的测试基准上进行了详尽的评估。选定的任务旨在测试模型的常识推理、信息抽取、文本理解、数学解题以及跨学科知识的能力。
评测方式
我们采用了两种评测方式:
1.Zero-shot 方式。该方式主要关注模型在未见过的新任务上的性能,即 zero-shot 学习。在没有给定与任务相关的训练样本的情况下,模型需要依赖其在大规模语料库中学到的知识和理解,来给出准确的答案。这种方式对模型的归纳、推理以及泛化能力都提出了很高的挑战。
2.Few-shot 方式。小样本学习方式要求模型在仅给定少数示例答案的情况下,能够产生合适的回答。这种评估方式主要测试模型的迁移和泛化能力。在实际应用中,这种能力尤为重要,因为它允许模型在数据稀缺的情境中仍然表现出色。
评测数据集
在 Zero-Shot 设定下,我们测试了 BoolQ, Hellaswag, WinoGrande, PIQA, ARC, OpenbookQA, RACE, DROP 和 GSM8K 数据集。在 Few-Shot 设定下,我们测试了 MMLU 和 TriviaQA 数据集。
实验结果
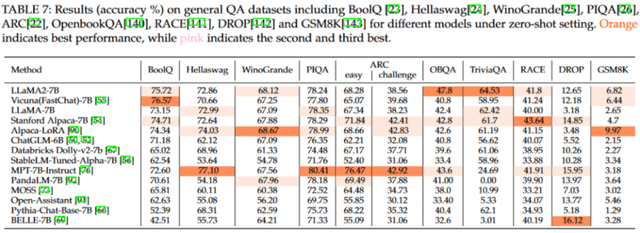
上图展示了不同语言模型在 zero-shot 设定下的测试结果。值得注意的是,尽管本研究分析的许多模型都基于 LLaMA-7B 架构,但它们的个体性能差异显著。这些模型之间的性能差异主要归因于它们在开发过程中采用的调优方法,这凸显了调优策略在决定模型性能上的核心作用。此外,这些结果也揭示了语言模型在不同任务中的效能差异。没有单一模型可以在所有数据集和任务上完全占优。另外,这些语言模型在涉及带有选项的任务中表现得相对较好,但在生成任务中则有所不及。这种差异是可以理解的,因为生成连贯、与上下文相符的内容远比简单的分类任务更为挑战,它需要模型具备更深入的语言和上下文理解能力。
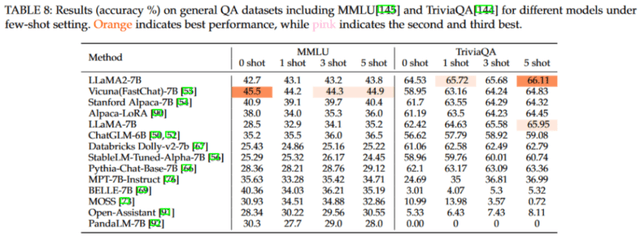
该图为我们呈现了模型在 few-shot 设置下的表现。从表格中,我们可以观察到几个显著的特点。首先,这些语言模型的性能并没有随着示例数量的增加而明显上升。这可以归因于模型相对较小的规模以及其有限地利用样本学习的能力,导致模型难以从所给示例中充分吸取知识。其次,模型在不同的示例设置下的性能相对稳定。因此,如果某模型在 zero-shot 设置下已经表现得很好,那么在其他设置下,它很可能也能保持这种优势。
不过,需要承认的是,部分经过测试的语言模型并未达到最佳表现。这些模型可能需要更合适的提示或进一步的微调来获取必要的知识并提高其整体性能。
人工评测
现有的基准数据集通常用于评估传统的语言模型,但它们往往只专注于某一特定的任务或主题。与此同时,大规模语言模型展现出的多样化能力,很难仅通过这些基准数据集来进行全面的评价。为了更深入地了解这些模型的性能,我们继续对现有的平替模型进行了人工评测。
评测方式
人工评价模型性能的关键在于评测问题的选择与评测人员的客观性。为此,我们采用常见的两两对比的方式来评测模型的表现。与直接打分或排序相比,两两对比的方式降低了参与测试人员的评测难度,从而提高了评测结果的客观性和准确性。我们设计了 50 个问题,涵盖了 9 个不同的方面,包括:日常问答、书面能力、推理、编程、数学、物理、化学、生物和有害内容检测。在 16 个模型上进行了这些问题的评估,并采用 Elo 评分系统对测试结果进行了最终的模型得分计算。

评测结果
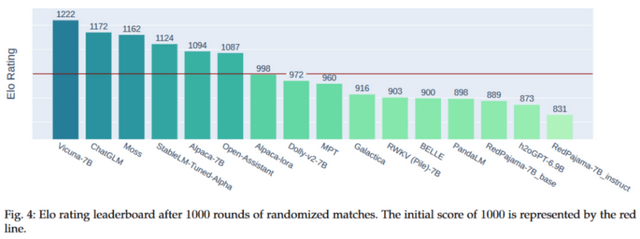
上图展示了各个模型的 Elo 得分,所有模型的初始 Elo 分数均为 1000,且我们采用了 K 因子为 16 来控制评分的最大波动。在这 16 个模型中,Vicuna-7B 位列榜首,其 Elo 得分高达 1222。ChatGLM 和 Moss 分别位居第二和第三。值得注意的是,从第 7 名到第 15 名的模型,它们的表现相差无几,都非常接近。从另一个角度看,Elo 评分系统确实具有显著的区分能力,这意味着各模型在性能上存在着明显的层次差异。
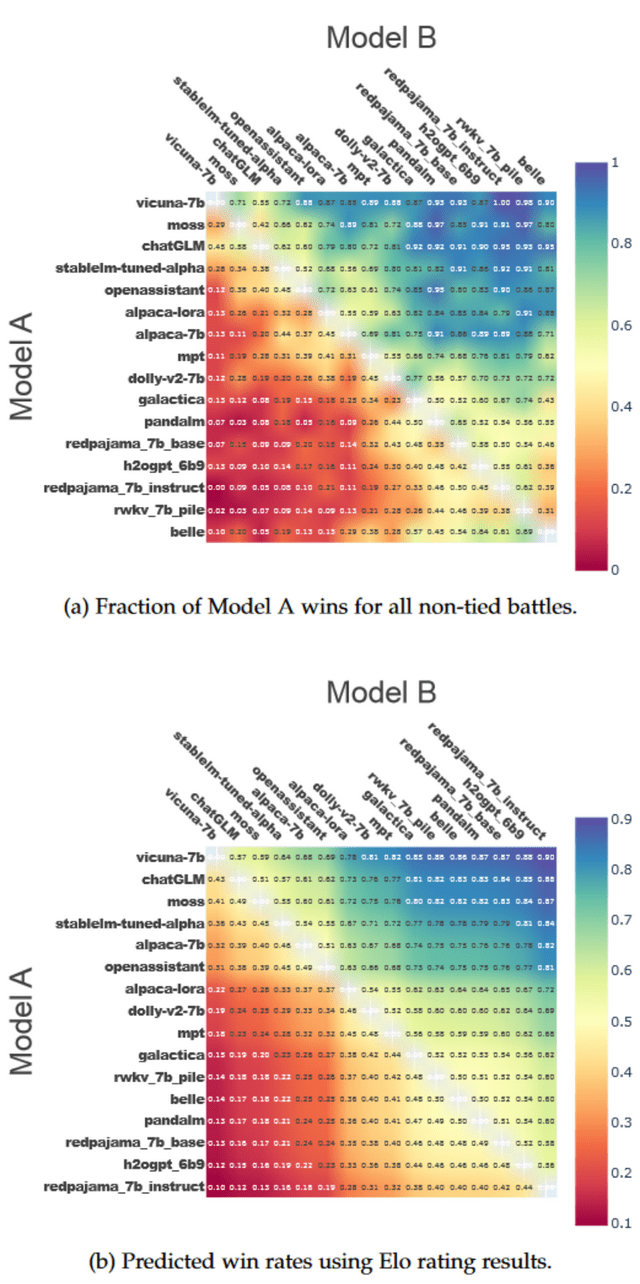
我们还可以利用 Elo 分数来预测模型两两之间的胜率。在一定的区间内,Elo 分数每相差 10 分,胜率就会有大约 1.5% 的变化。因此,我们基于 Elo 分数绘制了一对一胜率的热图,如图(b)所示。同时,图(a)展示了代表各模型间实际胜率的热图。显然,Elo 分数能够很好地反映模型之间的性能差异。例如,Vicuna-7B 与 ChatGLM 之间大约有 50 分的 Elo 分数差距,而 Vicuna-7B 对 ChatGLM 的胜率为 57%。这与实际胜率 55% 非常接近。

我们展示了不同模型在书写任务上的例子,排名最高的 Vicuna-7B 无论是在内容上还是在格式上都要显著地优于其他的方法。为了确认不同评测人员之间回答的一致性,我们随机选取了 20 个问题进行了人工一致性评测(Human Consistency)。评测指标为 tie-discounted 准确率:当两名评测人员的答案完全相同时,得 1 分;若其中一名评测人员给出的答案为 tie,则得 0.5 分;两者答案完全不同则得 0 分。经过评测,我们获得了 80.02 的一致性得分,这表明不同的评测人员之间的评估标准是大体一致的。
图文多模态模型
随着大规模语言模型在自然语言处理领域的大放光彩,越来越多的研究开始探索如何将这些模型与多模态信息融合。在本节中,我们将探讨并评估近期一些图文多模态大语言模型在常见基准上的性能。
模型简介
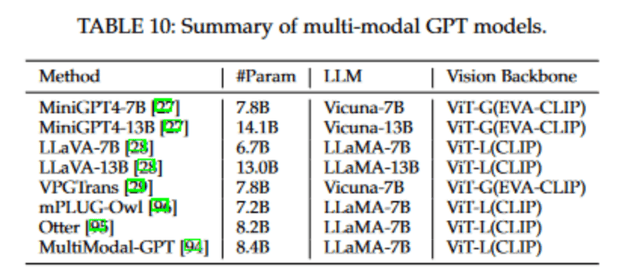
常见的多模态大语言模型一般由三部分组成:视觉编码器(Vision Encoder)、视觉 - 语言转换器(Vision-to-Language Converter)和大规模语言模型。视觉编码器旨在从图像中提取视觉信息,它通常采用如 CLIP 和 Flamingo 这类视觉 - 语言预训练模型初始化的 ViT 结构。视觉 - 语言转换器的作用是将视觉嵌入映射到语言嵌入空间,其设计目的是最大程度地减少视觉和语言之间的模态差异。而大规模语言模型则利用从视觉和语言两个模态中获得的信息来生成最终的答案。
评测方式
本节中,我们采用 ScienceQA 数据集来评测多模态模型在科学领域的推理能力。ScienceQA 数据集包含约 2 万道选择题,覆盖了丰富的学科领域。同时,大多数问题提供了相应的知识背景(Context),有助于模型进行思维链式推理。评测方式上,我们采用 2-Shot 的实验设置,即给定两个示例回答,要求模型根据示例回答给出最终答案。每个问答中,我们给出了问题文本(Q)、背景知识(C)和多个选项内容(M),要求模型给出答案(A)。
实验结果
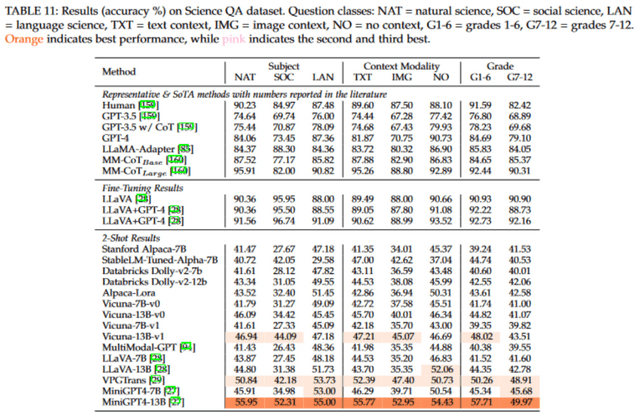
首先,我们对纯语言模型和多模态模型在整个测试集上的准确率进行了评估。结果显示,Vicuna 模型及其微调版本 MiniGPT4 在各自的领域中取得了最好的成果。
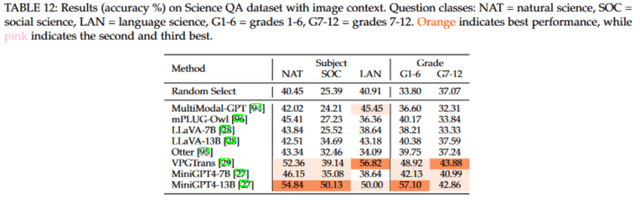
针对测试集中包含图片的样本,我们进一步测试了多模态模型的表现。在这方面,基于 Vicuna 的 MiniGPT4 和 VPGTrans 模型在各自的评价指标上分别取得了最好的成绩。
科学领域模型
如何将 AI 技术与科学研究相结合是研究的热点之一。近年来,通过对大规模自然语言模型在特定科学数据集上进行微调,使其更加适应科学研究的需求,已逐渐成为研究的新趋势,尤其在药物发现和材料设计等领域。在本节,我们将深入研究 GPT 平替模型在科学研究中的表现,并对其性能进行评估。
评测方式
我们对大规模语言模型在 MedQA、MedMCQA、PubMedQA、NLPEC 和 SciQ 等数据集上进行了评估。特别地,对于 MedQA 数据集,我们还考虑了不同的 few-shot 设置以及不同语言的数据。评估结果主要以准确率为指标进行展示。
在这里,为了探究提示指令对模型性能的影响,我们使用了标准提示指令 “Results with standard prompts” 和模型默认系统指令 “Results with specific system meta instructions” 两种方式对模型进行了评估。
实验结果
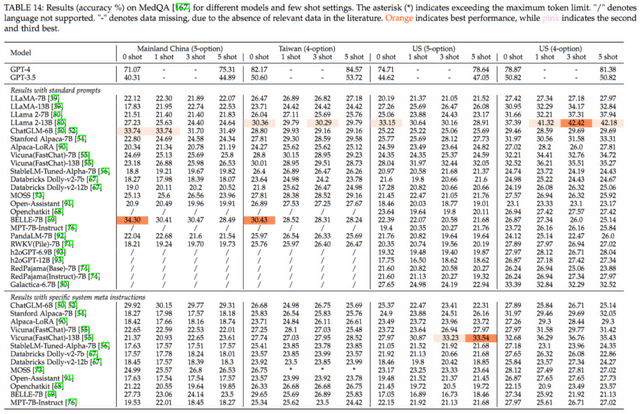
上表展示了各模型在 MedQA 数据集上的表现。得益于数据集的多语言支持,我们对模型在英文、简体中文和繁体中文三种语言上的性能进行了评估。在中文数据集评测中,ChatGLM-6B 和 BELLE-7B 的表现优于其他模型,其中在 “ 简体中文(5-Shot)” 和 “ 繁体中文(4-Shot)” 的测试中,准确率分别达到了约 34% 和 30%。这表明,这两款专为中文语料设计的模型在处理中文问题时具有明显的优势。而在英文数据集的评测中,LLaMA 2-13B 的性能尤为突出,其在 “ 英文(5-Shot)” 和 “ 英文(4-Shot)” 的测试中,准确率分别高达约 33% 和 42%。
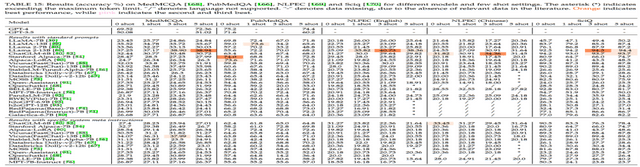
如上表所示,我们使用相同的模型在其他科学领域的数据集上也进行了评估。在 MedMCQA 数据集中,LLaMA 2-13B 和 Vicuna (FastChat)-13B 的表现超过了其他模型。而在 PubMedQA 数据集上,Stanford Alpaca-7B 和 Alpaca-LoRA 的性能尤为突出。在 NLPEC(英语 / 中文)和 SciQ 数据集上,LLama 2-13B 和 ChatGLM-6B 均展现了出色的性能。值得注意的是,在不同的 few-shot 设置中,部分模型的表现有所上升,但也有部分出现了下降,这说明:(1)并非所有模型在与 few-shot 的设置相结合时都一定会有更好的表现;(2) 性能并不一定会随着 few-shot 实例数量的增加而提高。
此外,对比两种提示词设置的结果,我们发现,在使用模型默认系统指令时,某些模型如 Stanford Alpaca-7B、Vicuna (FastChat) 13B、StableLM-Tuned-Alpha-7B 和 Databricks Dolly-v2-7B 展现了更佳的性能。这些模型对指令提示非常敏感,并能有效地利用这些指令优化输出。然而,也有如 BELLE-7B 这样的模型,在此设置下并未获得明显的性能提升,甚至可能有所下降。
从实验结果中,我们可以清晰地看到,尽管规模较小的模型(如 6B、7B、13B)在某些任务上表现不错,但它们在整体数据集上的表现仍然有限,距离达到 100% 或 50% 的准确率还有很长的路要走。这些模型的一个主要限制因素是其参数数量,这直接影响了它们的处理能力和泛化性能。
主要挑战与发展方向
根据上述的整体调研,以及我们大量的实验验证,我们也提出了未来值得注意的发展方向。
1. 实现模型规模与性能之间的平衡,比如探索更高效的模型架构以及轻量化方法;
2. 提高数据的利用效率以减少数据收集和标注的成本;
3. 增强模型的可解释性;
4. 提高模型的安全性与隐私性;
5. 更加详细且用户友好的使用说明。