一个真实世界机器学习系统的架构
本文是机器学习平台系列的第2部分。它由数字弹射器和 PAPIs支持。
在「机器学习」机器学习(ML)开发平台概述 ,我概述了ML开发平台,它们的工作是帮助创建和打包ML模型。模型构建只是ML系统所需的众多功能中的一项。在这篇文章的最后,我提到了其他类型的ML平台以及构建现实世界ML系统时的限制。在我们能够讨论这些之前,我们需要回顾这些系统的所有组件,以及它们是如何相互连接的。

上面的图表关注的是“监督学习”系统(例如分类和回归)的客户机-服务器架构,其中预测由客户机请求,在服务器上进行。(旁注:在某些系统中,最好有客户端预测;其他的甚至可能鼓励客户端模型培训,但是在工业ML应用程序中使其高效的工具还不存在。)
ML系统组件的概述
在进一步研究之前,我建议下载上面的图表,并分割屏幕,以便在阅读本文其余部分的同时可以看到图表。
让我们假设“数据库”在创建ML系统之前就已经存在了。深灰色和紫色的组件将是新的组件被建立。那些应用ML模型进行预测的用紫色表示。矩形用于表示有望提供微服务的组件,这些组件通常通过具象状态传输(representational state transfer, REST) api访问并在无服务器平台上运行。
ML系统有两个“入口点”:请求预测的客户端和创建/更新模型的协调器。客户端代表将从ML系统获益的最终用户使用的应用程序。这可以是你用来订晚餐的智能手机应用程序,例如UberEats请求预定的交货时间——这在COVID-19封锁期间是一个大用例!

封锁前的照片,维基百科提供。有一个复杂的ML系统可以预测这个家伙什么时候到达他的目的地,每天成千上万次,在世界上数以百计的城市!希望这个系统使用的模型在过去几周内得到了更新……
协调器通常是由调度程序调用的程序(以便模型可以定期更新,例如每周更新),或者通过API调用(以便它可以成为持续集成/持续交付管道的一部分)。它负责在一个保密的测试数据集上评估模型构建器创建的模型。为此,它将测试预测发送给求值器。如果一个模型被认为足够好,那么它将被传递到模型服务器,通过API使其可用。这个API可以直接公开给客户端软件,但是通常需要在前端中实现特定于领域的逻辑。
假设有一个或多个(基线)模型可以作为api使用,但还没有集成到最终的应用程序中,您将通过跟踪生产数据的性能并通过监视器可视化来决定要集成哪个模型(以及它是否安全)。在我们的晚餐递送示例中,它将让您比较一个模型的ETD与刚刚交付的订单的实际交货时间。当新的模型版本可用时,客户端对预测的请求将通过前端逐步定向到新模型的API。这将为越来越多的终端用户完成,同时监视性能并检查新模型是否“破坏”了任何东西。ML系统的所有者和客户机应用程序的所有者将定期访问监视器的仪表板。
让我们以列表的形式重述一下上图中的所有组件:
- 事实(Ground-truth)收集器
- 数据贴标机
- 评估者
- 性能监视器
- Featurizer(特征化器)
- 协调器
- 模型构建器
- 模型服务器
- 前端
我们已经简单地提到了第3、4、6、7、8和9条。现在让我们提供更多的信息,复习一下#1、# 2和# 5!
# 1:事实收集器
在现实世界中,关键是能够不断获取新的数据供机器学习。有一种数据特别重要:地面真实数据。这与您希望ML模型预测的内容相对应,例如房地产的销售价格、与客户相关的事件(例如客户流失)或分配给输入对象的标签(例如传入消息中的“spam”)。有时候,你观察一个输入对象,你只需要等待一段时间来观察你想预测的对象;例如,您等待房产被出售,等待客户续订或取消订阅,等待用户与收件箱中的电子邮件交互。您可能希望用户在ML系统预测错误时让您知道(参见下面的插图)。如果您想让您的用户能够提供这种反馈,您将需要一个微服务来将其发送到其中。

# 2:数据贴标机
有时,您可以访问大量的输入数据,但是您需要手动创建相关的ground-truth数据。构建垃圾邮件检测器或从图像构建对象检测器时就是这样。有现成的和开源的web应用来简化数据标注(如Label Studio),也有专门的外包手工标注数据的服务(如图8和谷歌的数据标注服务)。

飞机分类:标签工作室在行动
# 3:评估者
当您有了供机器学习的初始数据集时,在开始构建任何ML模型之前,定义如何评估计划的ML系统是很重要的。除了测量预测精度,还需要通过特定于应用程序的性能指标和系统指标(如延迟和吞吐量)来评估短期和长期的影响。
模型评估有两个重要的目标:比较模型,以及决定将模型集成到应用程序中是否安全。评估可以在一组预先确定的测试用例上执行,因为它是已知的预测应该是什么(即基本事实)。可以检查错误分布,并将错误聚合到性能指标中。为此,评估者需要访问测试集的ground truth,这样当它在输入中得到预测时,它就可以计算预测错误并返回性能指标。
我建议在构建ML模型之前优先实现这个求值器。评估基线模型所作的预测,以提供参考。基线通常是基于输入特征(也就是特性)的启发式方法。它们可以是超级简单的、手工制作的规则……
- 对于流失预测,你的基线可以说,如果一个客户在过去30天内登录少于3次,他们很可能会流失;
- 对于食物送餐时间的预测,你的基线可以是上周所点餐餐厅和乘客的平均送餐时间。
在明天开发复杂的ML模型之前,看看你的基线今天是否能创造价值!
# 4: 性能监视器
决定是否可以将(基线)模型集成到应用程序中的下一步是在生产中遇到的输入(称为“生产数据”)上使用它,在类似于生产的设置中,并通过时间监控它的性能。
计算和监控生产数据的性能指标需要在数据库中获取和存储生产输入、基本事实和预测。性能监视器将由一个从数据库读取数据、调用评估器的程序和一个显示性能指标如何随时间发展的仪表板组成。一般来说,我们希望检查模型是否随时间运行良好,以及它们是否持续对集成它们的应用程序产生积极影响。还可以使用显示生产数据分布的数据可视化小部件对监视器进行增强,这样我们就可以确保它们符合预期,或者我们可以监视漂移和异常情况。
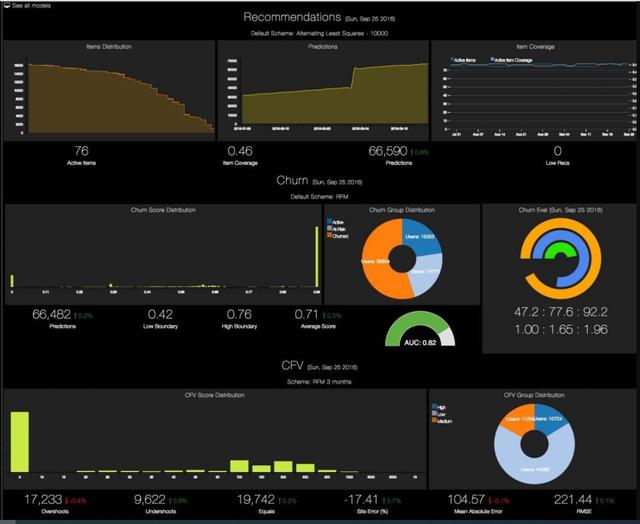
搅和模型的监视仪表板(源)
# 5: FEATURIZER(特征化机器)
在设计预测API时,需要决定API应该采用什么作为输入。例如,在对客户进行预测时,输入应该是客户的全部特性表示,还是仅仅是客户id?
在任何情况下,完整的数字表示都是很常见的(就像文本或图像输入一样),但是在传递给模型之前必须对其进行计算。对于客户输入,有些特性已经存储在数据库中(例如,出生日期),而其他特性则需要进行计算。这可能是描述客户在某段时间内如何与产品交互的行为特性的情况:它们将通过查询和聚合记录客户与产品交互的数据来计算。
如果特性本质上不经常变化,则可以批量计算它们。但在ML用例中,比如UberEats的预期交付时间,我们可能会有快速变化的“热点”特性,需要实时计算;例如,某家餐厅在过去X分钟内的平均送餐时间。
这需要创建至少一个特性化微服务,它将根据输入的id为一批输入提取特性。您可能还需要一个实时的特性化微服务,但是这会增加ML系统的复杂性。
功能分析器可以查询各种数据库,并对查询的数据执行各种聚合和处理。它们可能具有参数(如上面示例中的分钟数X),这些参数可能会对模型的性能产生影响。
# 6 协调器
工作流
协调器位于ML系统的核心,并与许多其他组件交互。下面是它的工作流/管道中的步骤:
- 提取-转换-加载和分割(原始)数据到训练,验证,测试集
- 发送功能饱和化的培训/验证/测试集(如果有的话)
- 准备专用的训练/验证/测试集
- 将准备好的训练/验证集的uri以及要优化的指标发送到模型构建器
- 得到最优模型,应用于测试集,并将预测发送给评估者
- 获取性能值并决定是否可以将模型推到服务器(例如,用于对生产数据的卡纳塔测试)。
关于步骤3(“准备专用培训/验证/测试集”)的更多细节:
- 增强训练数据(例如,过采样/过采样,或旋转/翻转/裁剪图像)
- 预处理训练/验证/测试集,包括数据消毒(以便可以安全地用于建模或预测)和针对特定问题的准备(例如,图像去饱和和调整大小)。
运行工作流的方法
整个工作流可以手动执行,但是要频繁地更新模型,或者联合调优建模器和建模器的超参数,就必须实现自动化。这个工作流可以实现为一个简单的脚本并在单个线程上运行,但是通过并行运行可以提高计算效率。端到端ML平台允许这样做,并且可以提供一个环境来定义和运行完整的ML管道。与谷歌AI平台,例如,你可以使用谷歌云数据产品,如Dataprep (Trifacta争吵工具提供的数据),数据流(一个简化的流和批量数据处理工具),BigQuery (serverless云数据仓库),您可以定义一个培训应用程序基于TensorFlow或内置算法(例如XGBoost)。在处理重要的数据量时,Spark是一个流行的选择。Spark背后的Databricks公司也提供端到端平台。
或者,工作流的每一步都可以在不同的平台或不同的计算环境中运行。一种选择是在不同的Docker容器中执行这些步骤。Kubernetes是ML从业者中最流行的开源容器编排系统之一。Kubeflow和Seldon Core是开源工具,允许用户描述ML管道并将其转换为Kubernetes集群应用程序。这可以在本地环境中完成,并且应用程序可以运行在Kubernetes集群上,该集群可以安装在本地,也可以在云平台中提供——例如谷歌Kubernetes引擎,它被谷歌AI平台或Azure Kubernetes服务或Amazon EKS使用。Amazon还提供了一种与Kubernetes相对应的Fargate和ECS。Apache气流是另一个开源工作流管理工具,最初由Airbnb开发。气流已经成为协调一般IT任务(包括ML任务)执行的流行方式,它还与Kubernetes集成。
为更高级的工作流程的主动学习
正如前面所暗示的,可能需要领域专家访问一个数据标签器,在那里他们将被显示输入并被要求标记它们。这些标签将存储在数据库中,然后编配人员可以在培训/验证/测试数据中使用这些标签。提供标记的输入可以手动选择,也可以在协调器中进行编程。这可以通过观察模型正确但不确定的生产投入,或非常确定但不确定的生产投入——这是“主动学习”的基础。
# 7 模型构建器
模型构建器负责提供一个最佳的模型。为此,它在训练集上训练各种模型,并在验证集上评估它们,使用给定的度量,以评估最优性。注意,这与上一篇文章中探讨的OptiML示例相同:
$ curl https://bigml.io/optiml?$BIGML_AUTH -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'
BigML通过它的API自动使模型可用,但是对于其他ML开发平台,您可能希望打包模型,将其保存为文件,并让您的模型服务器加载该文件。

在Azure ML上进行的“自动化ML”实验的结果。您可以下载找到的最佳模型,或者在Azure上部署它。
如果您使用不同的ML开发平台,或者根本不使用平台,那么以一种由专用服务自动创建模型的方式来构建您的系统是值得的,该服务需要对训练集、验证集和性能度量进行优化。
# 8 模型服务器
模型服务器的角色是处理针对给定模型的预测的API请求。为此,它加载保存在文件中的模型表示,并通过模型解释器将其应用到API请求中的输入;然后在API响应中返回预测。服务器应该允许并行处理多个API请求和模型更新。
下面是一个情绪分析模型的请求和响应示例,它只接受一个文本特性作为输入:
$ curl https://mydomain.com/sentiment-H 'X-ApiKey: MY_API_KEY'-d '{"input": "I love this series of articles on ML platforms"}'{"prediction": 0.90827194878055087}
存在不同的模型表示,如ONNX和PMML。另一个标准实践是将模型作为计算环境中的对象保存在文件中。这还需要保存计算环境的表示,特别是它的依赖关系,这样就可以再次创建模型对象。在这种情况下,模型“解释器”仅仅由像model.predict(new_input)这样的东西组成。
# 9 前端
前端可以服务多种用途:
- 简化模型的输出,例如将一个类概率列表转换为最可能的类;
- 添加到模型的输出中,例如使用黑盒模型解释器并提供预测解释(与Indico的方法相同);
- 实现特定领域的逻辑,例如基于预测的决策,或接收到异常输入时的回退;
- 发送生产输入和模型预测,以便存储在生产数据库中;
- 测试新模型,通过查询预测(除了“实时”模型之外)并存储它们;这将允许监视器为这些新的候选模型绘制性能指标。
模型生命周期管理
如果一个新的候选模型在测试数据集中提供了比当前模型更好的性能,那么通过让前端返回这个模型对一小部分应用程序的最终用户的预测(金丝雀测试),就可以测试它对应用程序的实际影响。这要求评估者和监控器实现特定于应用程序的性能指标。测试用户可以从列表中选取,也可以通过他们的某个属性、地理位置选择,或者完全随机选择。在监视性能并确信新模型不会破坏任何东西时,开发人员可以逐步增加测试用户的比例,并执行A/B测试,进一步比较新模型和旧模型。如果新模型被证实更好,前端就会通过总是返回新模型的预测来“取代”旧模型。如果新模型最终破坏了系统,也可以通过前端实现回滚。
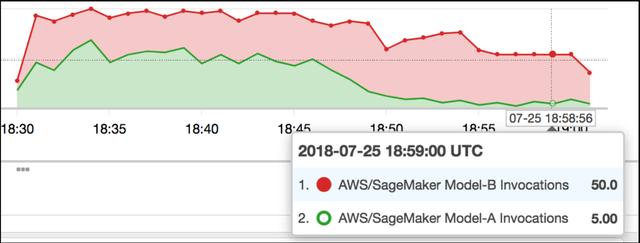
逐步将流量导向模型B,逐步淘汰模型A(来源)
结论
如果您对真实的ML感到好奇,那么我希望本文能够帮助您说明为什么ML开发平台和模型构建通常不足以创建对最终用户有实际影响的系统。




















