学了这些基础算法,人工智能就算入门了
说起人工智能,大家总把它和科幻电影中的机器人联系起来,而实际上这些科幻场景与现如今的人工智能没什么太大关系。
人工智能确实跟人类大脑很相似,但它们的显著差异在于人工智能是人造的——人工智能不必具备生物特性。
人工智能的目标是使计算机可以如人脑一样工作,但这并不意味着人工智能需要在方方面面都向人脑看齐。某个人工智能算法与人脑真实功能的匹配程度称为“生物似真性”。
艾伦脑科学研究所(Allen Institute of Brain Science)的首席科学官Christof Koch曾断言大脑“是已知宇宙中最复杂的东西”。而在人工智能的学科背景下,大脑本质上就是一种深奥、繁复的技术,我们有必要对它进行研究,通过逆向工程来解析它的工作原理和机制,从而模仿它的功能。
在进一步深入学习之前,还要介绍一些与人工智能算法交互的通用概念。人工智能算法也称为“模型”, 本质上是一种用以解决问题的技术。现在已经有很多特性各异的人工智能算法了,最常用的有神经网络、支持向量机、贝叶斯网络和隐马尔科夫模型等。
对于人工智能从业者来说,如何将问题建模为人工智能程序可处理的形式是至关重要的,因为这是与人工智能算法交互的主要方式。接下来我们将以人类大脑与现实世界的交互方式为引,展开关于问题建模基本知识的讲解。
01
对输入/输出建模
机器学习算法实际上就是给定输入,产生输出,而输出又受到算法本身的长短期记忆影响。下图展示了长短期记忆如何参与产生输出的过程。
机器学习算法抽象图示
如图所示,算法接受输入,产生输出。大多数机器学习算法的输入和输出是完全同步的,只有给定输入,才会产生输出,而不像人脑,既可以对输出做出响应,偶尔也能够在没有输入的情况下自行产生输出。
到目前为止,我们一直在抽象地谈论输入/输出模式,你一定很好奇输入/输出到底长什么样儿。实际上,输入和输出都是向量形式,而向量本质上就是一个如下所示的浮点数组:
Input:[-0.245,.283,0.0]
Output:[0.782,0.543]
绝大多数机器学习算法的输入和输出数目是固定的,就像计算机程序中的函数一样。输入数据可以被视作函数参数,而输出则是函数的返回值。就上例而言,算法会接受3个输入值,返回两个输出值,并且这些数目一般不会有什么变化,这也就导致对特定的算法而言,输入和输出模式的元素数量也不会改变。
要使用这种算法,就必须将特定问题的输入转化为浮点数数组,同样,问题的解也会是浮点数数组。说真的,这已经是大多数算法所能做的极限了,机器学习算法说穿了也就是把一个数组转换为另一个数组罢了。
在传统编程实践中,许多模式识别算法有点儿像用来映射键值对的哈希表,而哈希表在很大程度上与字典又有些相似之处,因为它们都是一个条目对应一个含义。哈希表一般长下面这样儿:
● “hear” ->“to perceive or Apprehend by the ear”;
● “run” ->“to go faster than a walk”;
● “write” ->“to form (as characters or symbols) on a surface with an instrument (as a pen)”。
上例这个哈希表是一些单词到定义的映射,其中将字符串形式的键映射为同样是字符串形式的值。你给出一个键(单词),哈希表就会返回一个值(对应单词的定义),这也是大多数机器学习算法的工作原理。
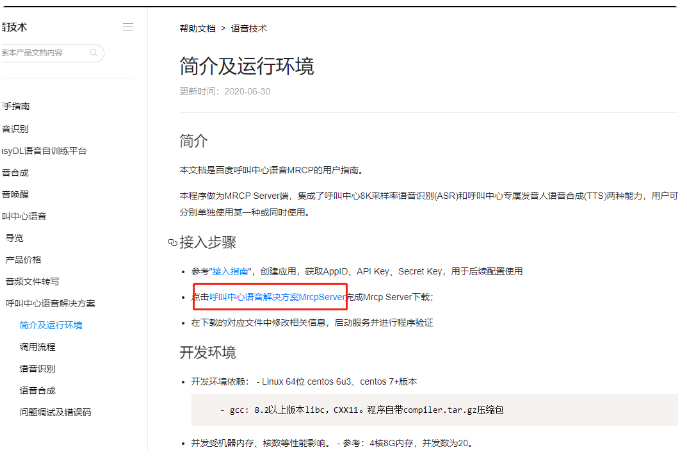
在所有程序中,哈希表都由键值对组成,机器学习算法输入层的输入模式可以类比为哈希表中的“键”,而输出层的返回模式也可以类比为哈希表中的“值”——唯一的不同在于机器学习算法比一个简单的哈希表更为复杂。
还有一个问题是,如果我们给上面这个哈希表传入一个不在映射中的键会怎么样呢?比如说传入一个名为“wrote”的键。其结果是哈希表会返回一个空值,或者会尝试指出找不到指定的键。而机器学习算法则不同,算法并不会返回空值,而是会返回最接近的匹配项或者匹配的概率。比如你要是给上面这个算法传入一个“wrote”,很可能就会得到你想要的“write”的值。
机器学习算法不仅会找最接近的匹配项,还会微调输出以适应缺失值。当然,上面这个例子中没有足够的数据给算法来调整输出,毕竟其中只有3个实例。在数据有限的情况下,“最接近的匹配项”没有什么实际意义。
上面这个映射关系也给我们提出了另一个关键问题:对于给定的接受一个浮点数组返回另一个浮点数组的算法来说,如何传入一个字符串形式的值呢?下面介绍一种方法,虽然这种方法更适合处理数值型数据,但也不失为一种解决办法。
词袋算法是一种编码字符串的常见方法。在这个算法模型中,每个输入值都代表一个特定单词出现的次数,整个输入向量就由这些值构成。以下面这个字符串为例:
Of Mice and Men
Three Blind Mice
Blind Man's Bluff
Mice and More Mice
由上例我们可以得到下面这些不重复的单词,这就是我们的一个“字典”:
Input 0 :and
Input 1 :blind
Input 2 :bluff
Input 3 :man's
Input 4 :men
Input 5 :mice
Input 6 :more
Input 7 :of
Input 8 :three
因此,例子中的4行字符串可以被编码如下:
Of Mice and Men [0 4 5 7]
Three Blind Mice [1 5 8]
Blind Man's Bluff [1 2 3]
Mice and More Mice [0 5 6]
我们还必须用0来填充字符串中不存在的单词,最终结果会是下面这样:
Of Mice and Men [1,0,0,0,1,1,0,1,0]
Three Blind Mice [0,1,0,0,0,1,0,0,1]
Blind Man's Bluff [0,1,1,1,0,0,0,0,0]
Mice and More Mice [1,0,0,0,0,2,1,0,0]
请注意,因为我们的“字典”中总共有9个单词,所以我们得到的是长度为9的定长向量。向量中每一个元素的值都代表着字典中对应单词出现的次数,而这些元素在向量中的编号则对应着字典中有效单词的索引。构成每个字符串的单词集合都仅仅是字典的一个子集,这就导致向量中大多数值是0。
如上例所示,机器学习程序最大的特征之一是会把问题建模为定长浮点数组。下面用一个例子来演示如何进行这种建模。
02
向算法传入图像
图像是算法的常见输入源。本节我们将介绍一种归一化图像的方法,这种方法虽然不太高级,但效果很不错却。
以一个300像素×300像素的全彩图像为例,90 000个像素点乘以3个RGB色彩通道数,总共有270 000个像素。要是我们把每个像素都作为输入,就会有270 000个输入——这对大多数算法来说都太多了。
因此,我们需要一个降采样的过程。下图是一幅全分辨率图像。
一幅全分辨率图像
我们要把它降采样为32像素×32像素的图像,如图所示。
降采样后的图像
在图片被压缩为32像素×32像素之后,其网格状模式使得我们可以按像素来生成算法的输入。如果算法只能分辨每个像素点的亮度的话,那么只需要1 024个输入就够了——只能分辨亮度意味着算法只能“看见”黑色和白色。
要是希望算法能够辨识色彩,还需要向算法提供每个像素点的红绿蓝3色(RGB)光强的值,这就意味着每个像素点有3个输入,一下子把输入数据的数目提升到了3 072个。
通常RGB值的范围在0~255,要为算法创建输入数据,就要先把光强除以255来得到一个“光强百分数”,比如光强度10经过计算就会变成0.039(10/255)。
你可能还想知道输出的处理办法。在这个例子中,输出应该表明算法认为图片内容是什么。通常的解决方案是为需要算法识别的每种图片创建一个输出通道,训练好的算法会在置信的图片种类对应的输出通道返回一个值1.0。
03
人工智能算法抢先读
欲建高楼,必重基础。算法是人工智能技术的核心。本书介绍了人工智能的基础算法,全书共10章,涉及维度法、距离度量算 法、K均值聚类算法、误差计算、爬山算法、模拟退火算法、Nelder-Mead算法和线性回归算法等。
本书使用你可以自己执行的、实际的数学计算,阐述了所有这些算法。本书的每一章都包含一个编程示例,这些示例提供了JAVA、C#、R、Python/ target=_blank class=infotextkey>Python和C的多个语言实现版本。
这些算法对应于数据中特定模式的处理和识别,同时也是像亚马逊 (Amazon)和网飞�.NETflix)这类网站中,各种推荐系统背后的逻辑。
书中所有算法均配以具体的数值计算来进行讲解,读者可以自行尝试。每章都配有程序示例,Github上有多种语言版 本的示例代码可供下载。
适合作为人工智能入门读者以及对人工智能算法感兴趣的读者阅读参考。
算法是人工智能技术的核心,大自然是人工智能算法的重要灵感来源。本书介绍了受到基因、鸟类、蚂蚁、细胞和树影响的算法,这些算法为多种类型的人工智能场景提供了实际解决方法。全书共10章,涉及种群、交叉和突变、遗传算法、物种形成、粒子群优化、蚁群优化、细胞自动机、人工生命和建模等问题。书中所有算法均配以具体的数值计算来进行讲解,每章都配有程序示例,读者可以自行尝试。
自早期以来,神经网络就一直是人工智能的支柱。现在,令人兴奋的新技术(例如深度学习和卷积)正在将神经网络带入一个全新的方向。在本书中,我们将演示各种现实世界任务中的神经网络,例如图像识别和数据科学。我们研究了当前的神经网络技术,包括ReLU 激活、随机梯度下降、交叉熵、正则化、Dropout 及可视化等。