MNIST 这里就不多展开了,我们上几期的文章都是使用此数据集进行的分享。
手写字母识别
EMNIST数据集
Extended MNIST (EMNIST), 因为 MNIST 被大家熟知,所以这里就推出了 EMNIST ,一个在手写字体分类任务中更有挑战的 Benchmark 。此数据集当然也包含了手写数字的数据集
在数据集接口上,此数据集的处理方式跟 MNIST 保持一致,也是为了方便已经熟悉 MNIST 的我们去使用,这里着重介绍一下 EMNIST 的分类方式。
分类方式
EMNIST 主要分为以下 6 类:
By_Class : 共 814255 张,62 类,与 NIST 相比重新划分类训练集与测试机的图片数
By_Merge: 共 814255 张,47 类, 与 NIST 相比重新划分类训练集与测试机的图片数
Balanced : 共 131600 张,47 类, 每一类都包含了相同的数据,每一类训练集 2400 张,测试集 400 张
Digits :共 28000 张,10 类,每一类包含相同数量数据,每一类训练集 24000 张,测试集 4000 张
Letters : 共 103600 张,37 类,每一类包含相同数据,每一类训练集 2400 张,测试集 400 张
MNIST : 共 70000 张,10 类,每一类包含相同数量数据(注:这里虽然数目和分类都一样,但是图片的处理方式不一样,EMNIST 的 MNIST 子集数字占的比重更大)
这里为什么后面的分类不是26+26?其主要原因是一些大小写字母比较类似的字母就合并了,比如C等等
代码实现手写字母训练神经网络
由于EMNIST数据集与MNIST类似,我们直接使用MNIST的训练代码进行此神经网络的训练
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision # 数据库模块
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
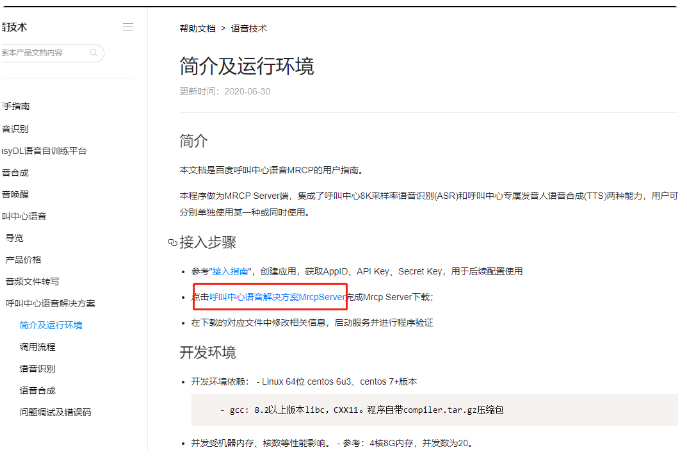
EPOCH = 1 # 训练整批数据次数,训练次数越多,精度越高,为了演示,我们训练5次
BATCH_SIZE = 50 # 每次训练的数据集个数
LR = 0.001 # 学习效率
DOWNLOAD_MNIST = Ture # 如果你已经下载好了EMNIST数据就设置 False
# EMNIST 手写字母 训练集
train_data = torchvision.datasets.EMNIST(
root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download = DOWNLOAD_MNIST,
split = 'letters'
)
# EMNIST 手写字母 测试集
test_data = torchvision.datasets.EMNIST(
root='./data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=False,
split = 'letters'
)
# 批训练 50samples, 1 channel, 28x28 (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 每一步 loader 释放50个数据用来学习
# 为了演示, 我们测试时提取2000个数据先
# shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000] / 255.
test_y = test_data.targets[:2000]
#test_x = test_x.cuda() # 若有cuda环境,取消注释
#test_y = test_y.cuda() # 若有cuda环境,取消注释
首先,我们下载EMNIST数据集,这里由于我们分享过手写数字的部分,这里我们按照手写字母的部分进行神经网络的训练,其split为letters,这里跟MNIST数据集不一样的地方便是多了一个split标签,备注我们需要那个分类的数据
torchvision.datasets.EMNIST(root: str, split: str, **kwargs: Any)
root ( string ) –
数据集所在EMNIST/processed/training.pt 和 EMNIST/processed/test.pt存在的根目录。
split(字符串)
-该数据集具有6个不同的拆分:byclass,bymerge, balanced,letters,digits和mnist。此参数指定使用哪一个。
train ( bool , optional )
– 如果为 True,则从 中创建数据集training.pt,否则从test.pt.
download ( bool , optional )
– 如果为 true,则从 Inte.NET 下载数据集并将其放在根目录中。如果数据集已经下载,则不会再次下载。
transform ( callable , optional )
– 一个函数/转换,它接收一个 PIL 图像并返回一个转换后的版本。例如,transforms.RandomCrop
target_transform ( callable , optional )
– 一个接收目标并对其进行转换的函数/转换。
可视化数据集
然后我们可视化一下此数据集,看看此数据集什么样子
def get_mApping(num, with_type='letters'):
"""
根据 mapping,由传入的 num 计算 UTF8 字符
"""
if with_type == 'byclass':
if num <= 9:
return chr(num + 48) # 数字
elif num <= 35:
return chr(num + 55) # 大写字母
else:
return chr(num + 61) # 小写字母
elif with_type == 'letters':
return chr(num + 64) + " / " + chr(num + 96) # 大写/小写字母
elif with_type == 'digits':
return chr(num + 96)
else:
return num
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(train_data), size=(1,)).item()
img, label = train_data[sample_idx]
print(label)
figure.add_subplot(rows, cols, i)
plt.title(get_mapping(label))
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
字符编码表(UTF-8)
字符编码表
首先我们建立一个字符编码表的规则,这是由于此数据集的label,是反馈一个字母的字符编码,我们只有通过此字符编码表才能对应起来神经网络识别的是那个字母
通过观察其数据集,此字母总是感觉怪,这是由于EMNIST数据集左右翻转图片后,又进行了图片的逆时针旋转90度,小编认为是进行图片数据的特征增强,目前没有一个文件来介绍为什么这样做,大家可以讨论
搭建神经网络
神经网络的搭建,我们直接使用MNIST神经网络
# 定义神经网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # 输入通道数
out_channels=16, # 输出通道数
kernel_size=5, # 卷积核大小
stride=1, #卷积步数
padding=2, # 如果想要 con2d 出来的图片长宽没有变化,
# padding=(kernel_size-1)/2 当 stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # 在 2x2 空间里向下采样, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 37) # 全连接层,A/Z,a/z一共37个类
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平多维的卷积图成 (batch_size, 32 * 7 * 7)
output = self.out(x)
return output
以上代码在介绍手写数字时有详细的介绍,大家可以参考文章开头的文章链接,这里不再详细介绍了,这里需要注意的是神经网络有37个分类
神经网络的训练
cnn = CNN() # 创建CNN
# cnn = cnn.cuda() # 若有cuda环境,取消注释
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # 每一步 loader 释放50个数据用来学习
#b_x = b_x.cuda() # 若有cuda环境,取消注释
#b_y = b_y.cuda() # 若有cuda环境,取消注释
output = cnn(b_x) # 输入一张图片进行神经网络训练
loss = loss_func(output, b_y) # 计算神经网络的预测值与实际的误差
optimizer.zero_grad() #将所有优化的torch.Tensors的梯度设置为零
loss.backward() # 反向传播的梯度计算
optimizer.step() # 执行单个优化步骤
if step % 50 == 0: # 我们每50步来查看一下神经网络训练的结果
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
# 若有cuda环境,使用84行,注释82行
# pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze()
accuracy = float((pred_y == test_y).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data,
'| test accuracy: %.2f' % accuracy)
神经网络的训练部分也是往期代码,这里建议大家训练的EPOCH设置的大点,毕竟37个分类若只是训练一两次,其精度也很难保证
测试神经网络与保存模型
# test 神经网络
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.squeeze()
# 若有cuda环境,使用92行,注释90行
#pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze()
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')
# save CNN
# 仅保存CNN参数,速度较快
torch.save(cnn.state_dict(), './model/CNN_letter.pk')
# 保存CNN整个结构
#torch.save(cnn(), './model/CNN.pkl')
训练完成后,我们可以检测一下神经网络的训练结果,这里需要注意的是,pred_y与test_y只是字母的编码,并不是真实的字母,最后我们保存一下神经网络的模型,方便下期进行手写字母的识别篇