机器学习之恶意流量检测的特征工程
传统的机器学习除了使用Tfidf-ngram的方式外还有其他做特征工程方式,还可以通过定义不同维度的特征来做特征工程,这种特征工程方式需要安全工程师对每一种攻击有良好特征提取能力。这种方法举个例子来说可以这样理解,我的输入是姚明,此时我在特征工程阶段需要将姚明转化为身高2.2米、体重400斤等等数值特征,再经过标准化等转化为机器可以识别的量纲单位进行学习预测。

机器学习流程&特征工程
传统的机器学习可以理解成是生产算法的算法。需要人来先做特征提取,然后再把特征向量化后交给机器去训练。为什么要做特征工程,有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。我们做特征工程的目的是为了让训练后的结果达到最优的状态。

本例中我们的目的是从流量中识别恶意流量,首先需要在所有的负例样本中筛选出最具代表的特征,在所有的负例样本中筛选出最具代表的特征,我们先从简单关键词特征开始。观察正例样本基本没有类似information_schema.table、 sleep() 、alert(/1/)这种的特殊字符。
format=xml&platform=ppap&channel=withoutchannelfilename=sgim_eng.zip&h=B2EF665558623D671FC19AC78CA2F0F3&v=8.0.0.8381&ifauto=1
md5=d10015a0eb30bd33bb917e1d527c649num=8&PaperCode=600054daid=41&clientuin=1264523260
clientkey=00015947C124007000F19A1CB5D10832A25TAG=ieg.qqpenguin.desktopdaid=41&clientuin=1264523260
观察负例样本可以将如下负例样本看作是请求的value部分如http://x.x.x/path?key1=value1&key2=value2,可以观察到同类型攻击具有很多相同的特征,比如xss来说具有很多JAVAscript、alert、onerror=等特征,sql注入具有informationschema、informationschema.table、select、from、where等关键词特征
<form id="test" /><button form="test"formaction="JavaScript:alert(123)">TESThtml5FORMACTION<scriptitworksinallbrowsers>/<script */alert(1)</script<metahttp-equiv="refresh" content="0;url=javascript:confirm(1)"></textarea><script>alert(/xss/)</script>'><script>alert(document.cookie)</script><form><isindexformaction="javascript:confirm(1)"alert(String.fromCharCode(88,83,83));'))"><inputtype="text" value=``<div/onmouseover='alert(1)'>X</div><BODY ONLOAD=alert('helloxworldss')><![><img src="]><img src=x onerror=alert(XSS)//"><inputonblur=write(XSS) autofocus><input autofocus>
本例抽取部分的xss负例样本,从中可以抽取的特征规则大致可以这样表示

即便如此仍然会存在很多变形特征,比如<script/**/>、console.log()、<Script>,所以进行一步完善特征工程这一次我们将特征分为两个维度,第一个维度是词特征,第二是符号维度,同时对所有的大小写进行统一转换为小写,对于请求的value是url这种可能会存在很多特殊符号的链接特征,在本例中可以进行统一降噪转换为"x"避免受到此类特征等影响学习结果

这里特别说明一下特征除此之外的纬度还有很多,playload的长度、请求响应时间、该ip或该开源指纹请求次数等等,这里我们只用了2个维度来简单说明。我们继续将特征进行进行量化,可以大致得到如下每条playload内容对应的特征向量

在处理请求的过程中难免会出现特质编码[8,40],[9,35]类似这样具有奇异性的特征编码,在机器学习领域中我们需要将量纲和量纲单位限定在一个空间同样的数量级范围内,经过处理后的数据会消除奇异值带来的影响,以便我们进行综合对比评判。
min-max标准化
这里简单说一下标准化,min-Max就是把数据按比例缩放,使之落入一个小的空间里。同时不改变原有的正态分布,特征数据的取值范围并不在[ 0,1 ]之间,这点跟归一化不同。如下其中X代表要转换的对象,[Newmax,Newmin]代表范围区间。

收入范围最低收入12000,最高收入98000,标准化映射到[0,1]之间,现在要将一个人收入是73600进行标准化,映射后的结果如下
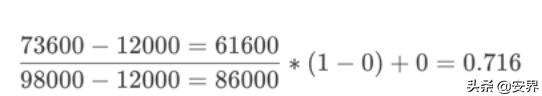
代码示例
数据预处理,这里正负样本数据结构就不再重复了,保证一个都是恶意样本,一个是正常样本即可。
def loadFile():
badXss = "./badx.txt"
goodXss = "./goox.txt"
bf = [x.strip().lower() for x inopen(badXss, "r").readlines()]
gf = [x.strip().lower() for x inopen(goodXss, "r").readlines()]
return bf, gf
特征工程阶段,一条playload或者正常样本后进行特征提取,特征拆分成两个维度,一个维度是关键词特征,一个维度是关键符号特征
def MakeFeature(x):
charList = ["onmouseover=","onload=", "onerror=", "javascript","alert", "src=", "confirm", "onblur"]
markList = ["=", ":",">", "<", '"', "'", ")","(", "."]
featureList = []
for i in x:
char_count, mark_count = 0, 0
payload =urllib.parse.unquote(i.lower().strip())
for charts in charList:
char_count = payload.count(charts)+ char_count
for marks in markList:
mark_count = payload.count(marks) +mark_count
featureList.Append([char_count,mark_count])
return featureList
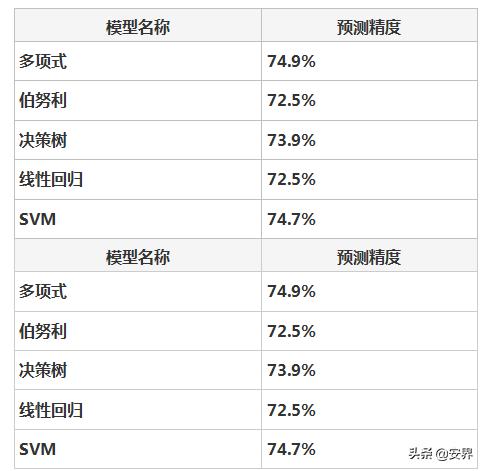
训练阶段拆分40%测试集,这里笔者使用了多个算法分别进行训练,目的是想看一下几个算法在相同数据集下的训练时间和效果
def train(x, y):
x_train, x_test, y_train, y_test =train_test_split(x, y, test_size=0.4, random_state=666)
param = {'n_estimators': 200, 'max_depth':200, 'min_samples_split': 2, 'learning_rate': 0.01}
NBM = [MultinomialNB(alpha=0.01), # 多项式模型-朴素贝叶斯
BernoulliNB(alpha=0.01),
DecisionTreeClassifier(max_depth=100),
RandomForestClassifier(criterion='gini', max_depth=100,n_estimators=200),
LogisticRegression(random_state=40,solver='lbfgs', max_iter=10000, penalty='l2',multi_class='multinomial',class_weight='balanced', C=100),
LinearSVC(class_weight='balanced',random_state=100, penalty='l2',loss='squared_hinge', C=0.92, dual=False),
SVC(kernel='rbf', gamma=0.7, C=1),
# GradientBoostingClassifier(param)
]
NAME = ["多项式", "伯努利", "决策树", "随机森林", "线性回归", "linerSVC", "svc-rbf"]
for model, modelName in zip(NBM, NAME):
model.fit(x_train, y_train)
pred = model.predict(x_test)
dts = len(np.where(pred == y_test)[0])/ len(y_test)
print("{} 精度:{:.5f} ".format(modelName, dts * 100))
joblib.dump(model, './model.pkl')
预测概率,加载模型进行精度预测
def predicts(x):
clf = joblib.load('./model.pkl')
return clf.predict(x)
def run():
badx, goodx = loadFile()
goodx = MakeFeature(goodx)
badx = MakeFeature(badx)
goody = [0] * len(goodx)
bady = [1] * len(badx)
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax =min_max_scaler.fit_transform(bady)
x = np.array(goodx + badx).reshape(-1, 2)
y = np.array(goody + bady).reshape(-1, 1)
train(x, y)
testX =["<script>alert(1)</script>", "123123sadas","onloads2s", "scriptsad23asdasczxc","onload=alert(1)"]
x =MakeFeature(testX)
forres, req in zip(predicts(x), testX):
print("XSS==>" if res == 1else "None==>", req)
预测结果
XSS==>alert(1)
None==> 123123sadas
None==> onloads2s
None==>scriptsad23asdasczxc
XSS==>onload=alert(1)“””
结果
可以看到由于特征工程阶段做的特征维度不够多特征保留的不够充分,在白样本中存在大量的干扰特征,导致最后准确率召回率都不是很高,精度大约只有74%左右,使用这种特征工程的方法笔者不是很推荐,虽然有监督方式的机器学习具有良好的可解释性,但是维护特征是一个永无止尽的过程,难度你真的想有多少智能就有多少人工吗。
原文地址:freebuf.com/articles/web/223481.html




















