用膨胀卷积进行命名实体识别 NER
BiLSTM+CRF 是命名实体识别中最为流行的模型,但是 LSTM 需要按顺序处理输入的序列,速度比较慢。而采用 CNN 可以更高效的处理输入序列,本文介绍一种使用膨胀卷积进行命名实体识别的方法 IDCNN,通过膨胀卷积可以使模型接收更长的上下文信息。
1.膨胀卷积
膨胀卷积 (Dilated Convolution) 是指卷积核中存在空洞,下图展示了膨胀卷积和传统卷积的区别。之前的文章《膨胀卷积 dilated convolution》 有关于膨胀卷积的介绍,不熟悉的童鞋可以参考一下。
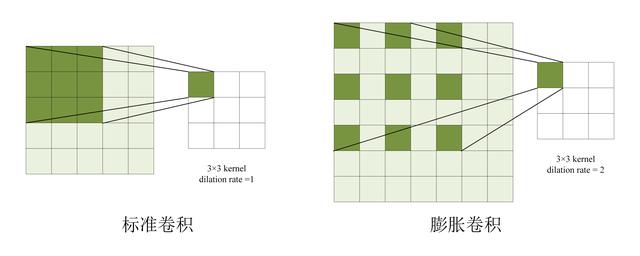
膨胀卷积和传统卷积的区别
膨胀卷积通过在卷积核中增加空洞,可以扩大模型的感受野 (即句子中的上下文),从下图可以看到,同样是尺寸为 3 的卷积核,同样是两层卷积层,膨胀卷积的上下文大小为 7,而传统卷积上下文大小为 5。

膨胀卷积和传统卷积上下文大小
卷积核的膨胀系数 (即空洞的大小) 每一层是不同的,一般可以取 (1, 2, 4, 8, ...),即前一层的两倍。
对于尺寸为 3 的传统卷积核,第 L 层的上下文大小为 2L+1;而对于尺寸为 3 的膨胀卷积核,第 L 层上下文的大小是 2^(L+1) -1。因此膨胀卷积的上下文大小和层数是指数相关的,可以通过比较少的卷积层得到更大的上下文。
2.用膨胀卷积进行命名实体识别
论文《Fast and Accurate Entity Recognition with Iterated Dilated Convolutions》中提出了一种使用膨胀卷积的方法进行命名实体识别,IDCNN (Iterated Dilated Convolutions)。
作者认为直接堆叠膨胀卷积层,可以获得很长距离的上下文信息,例如有 9 层膨胀卷积层,则上下文的宽度超过 1000。但是简单的堆叠多层膨胀卷积,容易导致过拟合。
为了避免过拟合,作者先构造一个层数不多的膨胀 block,block 包含几个膨胀卷积层,例如 4 个。然后把数据重复传到同一个 block 中,即 block 输出的结果又重复传入 block 中,作者称为 Iterated Dilated Convolutions,IDCNN。通过重复使用相同的 block,可以让模型接收更宽的上下文信息,同时有比较好的泛化能力。
IDCNN 的膨胀卷积 block 包含多个膨胀卷积层,用 D 表示膨胀卷积层,如下面公式所示:

膨胀卷积层表示
IDCNN 网络的第一层对输入数据进行转换,使用标准的卷积:

IDCNN 第一层对输入进行转换
后 IDCNN 会使用 Lc 个膨胀卷积层构造出 block,block 用 B() 表示,block 包含的膨胀卷积如下:
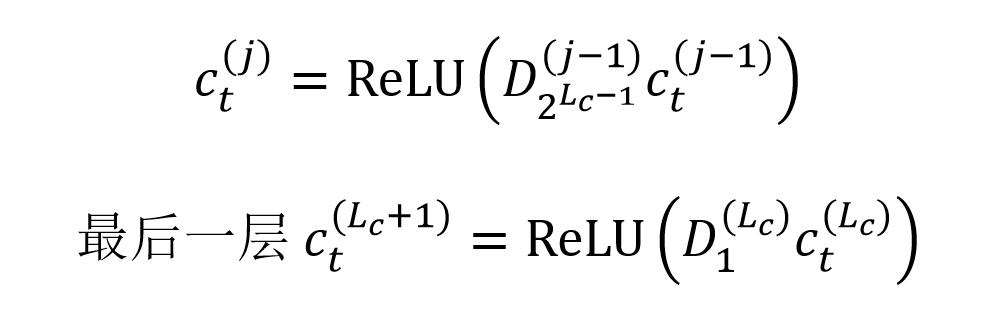
block 中包含 Lc 个膨胀卷积
IDCNN 会重复使用 Lb 次相同的 block,对数据进行处理,如下:
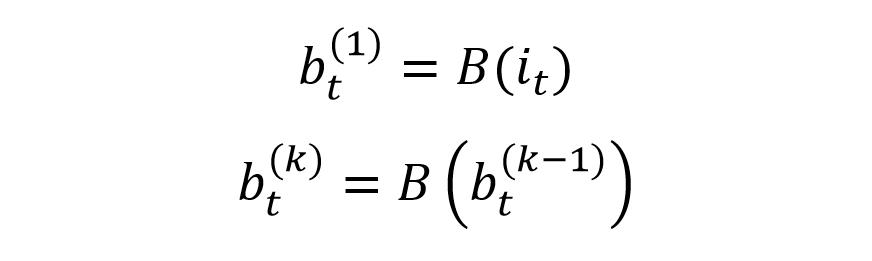
IDCNN 重复使用 Lb 次 block
最后一层的输出再经过线性变换,可以得到序列每一个时刻 t 属于不同类别的分数:
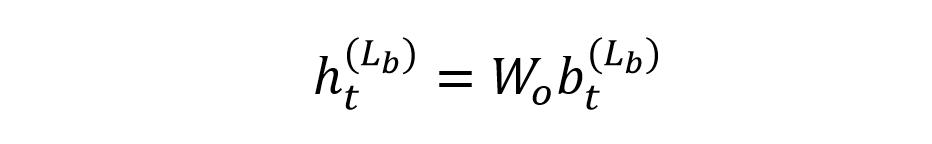
最后一层输出线性变换
3.IDCNN 训练
IDCNN 可以使用两种训练方式,第一种是利用最后一次 block 的输出,预测每一时刻的类别,如下:

IDCNN 用最后一层 block 输出进行预测
这种方法可以结合 CRF 进行训练,类似 BiLSTM+CRF,因为 IDCNN 也可以输出每一时刻属于不同类别的概率。
第二种训练方法是对于每一次 block 的输出都预测序列的类标,作者认为这种方式可以起到类似 CRF 的效果,能够把输出结果之间的关系编码到 IDCNN 中。例如假设执行两次 block,则第一次 block 可以预测每一时刻对应不同类别的概率。而第二次 block 接收第一次 block 的输出,可以预测每一时刻输出之间的关系,类似 CRF。公式如下:
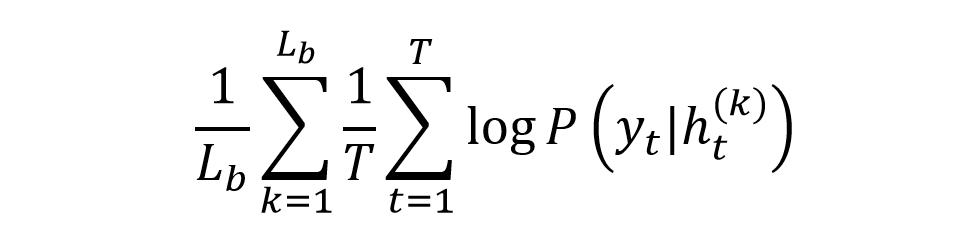
IDCNN 使用每一层 block 输出进行预测
4.参考文献
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions




















