谷歌发布搜索系统AVIS

新智元报道
编辑:LRS
【新智元导读】知识无法完全编入模型参数,学会搜索也是AI的必备技能!
在大型语言模型(LLM)的加持下,与视觉结合的多模态任务,如图像描述、视觉问答(VQA)和开放词汇目标识别(open-vocabulary object detection)等都取得了重大进展。
不过目前视觉语言模型(VLM)基本都只是利用图像内的视觉信息来完成任务,在inforseek和OK-VQA等需要外部知识辅助问答的数据集上往往表现不佳。

最近谷歌发表了一个全新的自主视觉信息搜索方法AVIS,利用大型语言模型(LLM)来动态地制定外部工具的使用策略,包括调用API、分析输出结果、决策等操作为图像问答提供关键知识。

论文链接:https://arxiv.org/pdf/2306.08129.pdf
AVIS主要集成了三种类型的工具:
1. 从图像中提取视觉信息的工具
2. 检索开放世界知识和事实的网络搜索工具
3. 检索视觉上相似的图像搜索工具
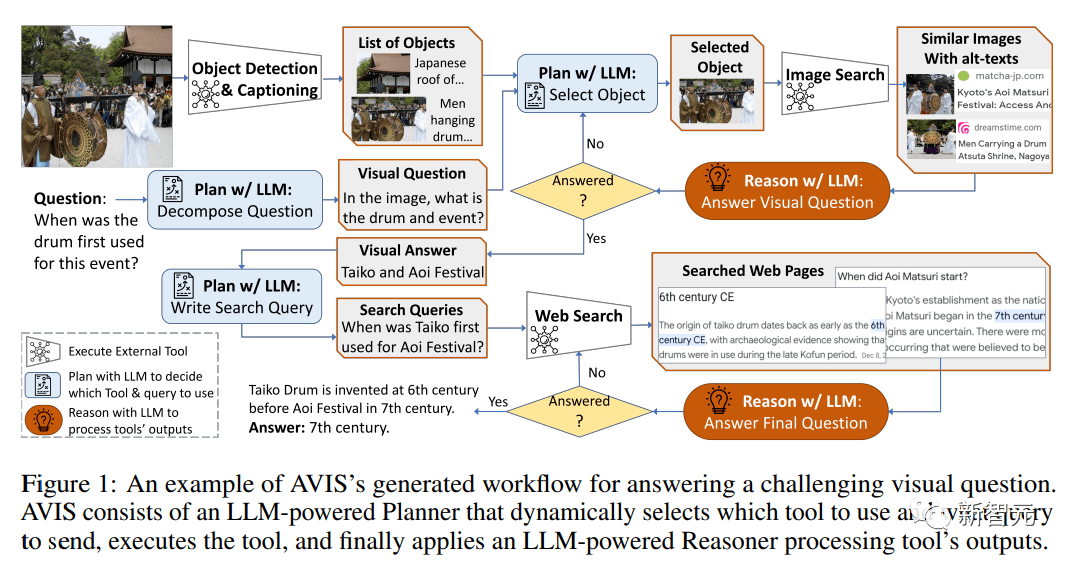
然后使用基于大型语言模型的规划器在每个步骤中选择一个工具和查询结果,动态地生成问题答案。
模拟人类决策
Infoseek和OK-VQA数据集中的许多视觉问题甚至对人类来说都相当难,通常需要各种外部工具的辅助,所以研究人员选择先进行一项用户调研,观察人类在解决复杂视觉问题时的解决方案。

首先为用户配备一组可用的工具集,包括PALI,PALM和网络搜索,然后展示输入图像、问题、检测到的物体裁剪图、图像搜索结果的链接知识图谱实体、相似的图像标题、相关的产品标题以及图像描述。
然后研究人员对用户的操作和输出进行记录,并通过两种方式来引导系统做出回答:
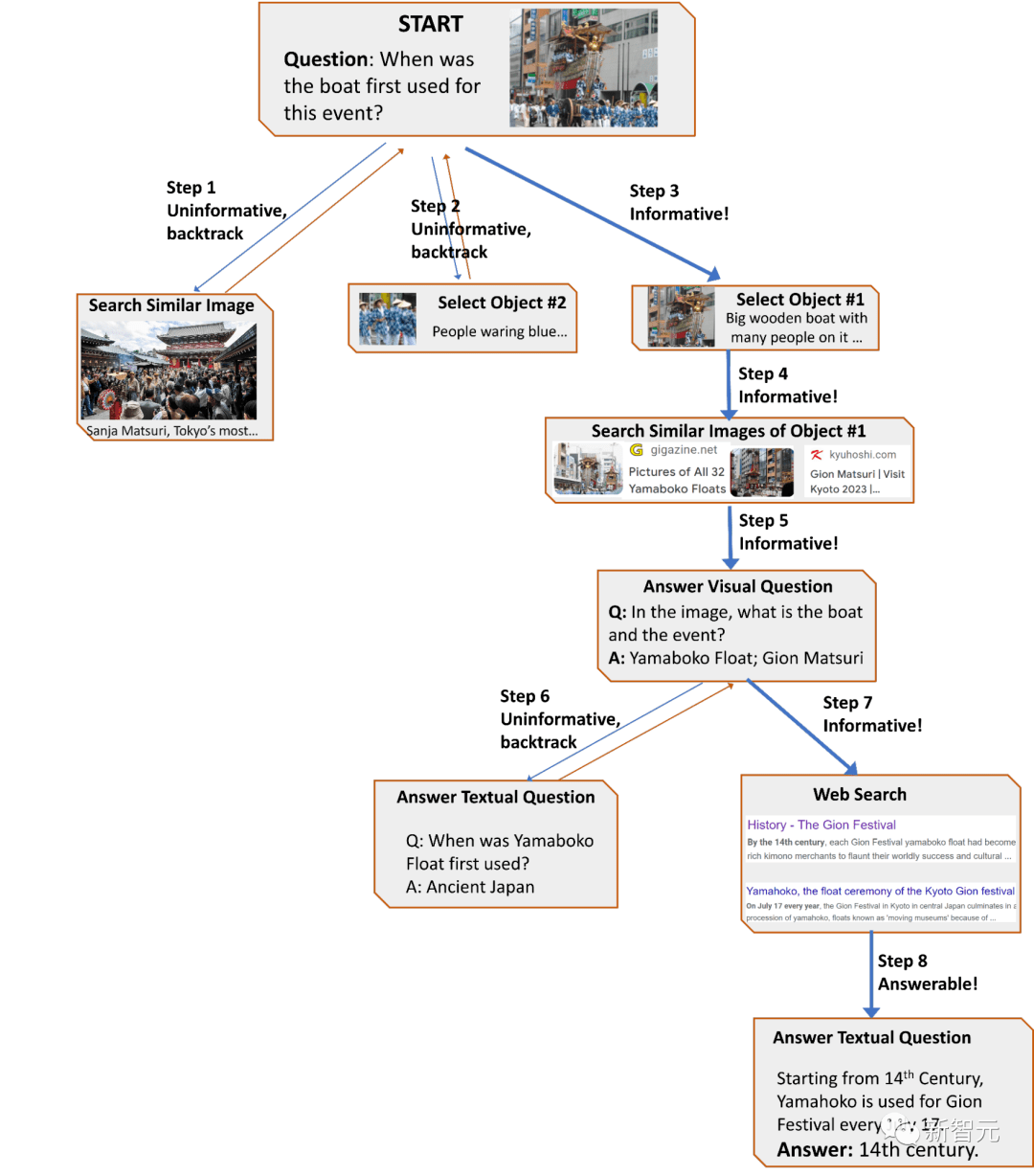
1. 通过分析用户做出的决策序列来构建转换图,其中包含不同的状态,每个状态下的可用操作集都不同。
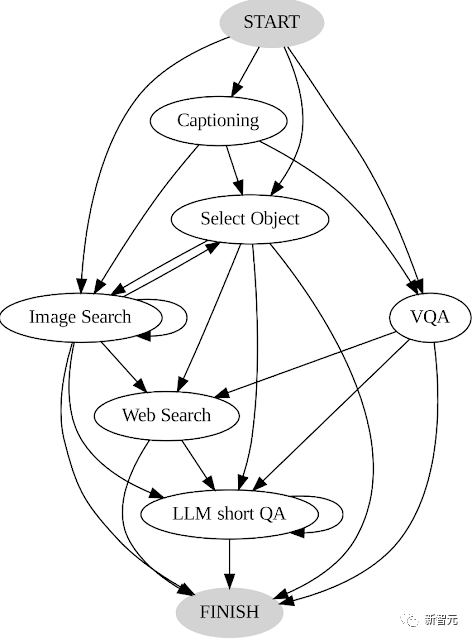
AVIS转换图
例如在开始状态下,系统只能执行三个操作:PALI描述、PALI VQA或目标检测。
2. 使用人类决策的样例来引导规划器(planner)和推理器(reasoner)与相关的上下文实例,来提高系统的性能和有效性。
总体框架
AVIS方法采用了一个动态的决策策略,旨在响应视觉信息寻求查询。
该系统有三个主要组成部分:
1. 规划器(planner),用来确定后续操作,包括适当的API调用以及需要处理的查询。
2. 运行记忆(working memory)工作内存,保留了从API执行中获得的结果信息。
3. 推理器(reasoner),用来处理API调用的输出,可以确定所获得的信息是否足以产生最终响应,或者是否需要额外的数据检索。
每次需要决定使用哪个工具以及向系统发送哪些查询时,规划器都要执行一系列操作;基于当前状态,规划器还会提供潜在的后续动作。
为了解决由于潜在的动作空间可能过多,导致搜索空间过大的问题,规划器需要参考转换图来消除不相关的动作,排除之前已经采取并存储在工作记忆中的动作。
然后由规划器从用户研究数据中组装出一套上下文示例,结合之前工具交互的记录,由规划器制定提示后输入到语言模型中,LLM再返回一个结构化的答案,确定要激活的下一个工具以及派发的查询。
整个设计流程可以多次调用规划器,从而促进动态决策,逐步生成答案。

研究人员使用推理器来分析工具执行的输出,提取有用的信息,并决定工具输出哪个类别:提供信息的、不提供信息的或最终答案。
如果推理器返回结果是「提供答案」,则直接输出作为最终结果,结束任务;如果结果是无信息,则退回规划器,并基于当前状态选择另一个动作;如果推理器认为工具输出是有用的,则修改状态并将控制权转移回规划器,以在新状态下做出新的决定。
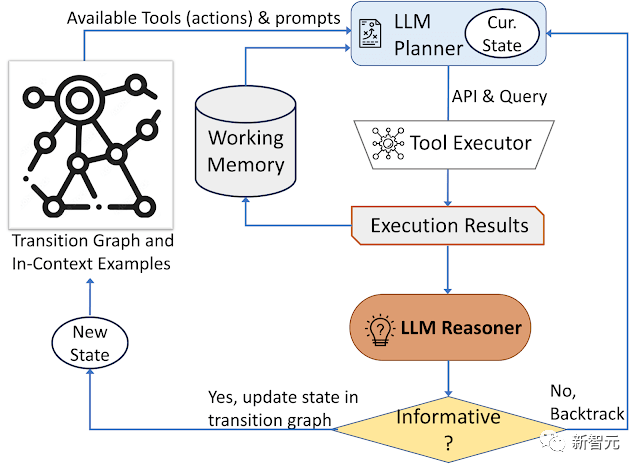
AVIS采用动态决策策略来响应视觉信息搜索查询
实验结果
工具集合
图像描述模型,使用PALI 17B模型为输入图像和检测到的物体裁剪图像生成描述。
视觉问题回答模型,使用 PALI 17B VQA 模型,将图像和问题作为输入,并将基于文本的答案作为输出。
物体检测,使用在Open Images数据集的超集上训练的物体检测器,具体类别google Lens API提供;使用高置信度阈值,只保留 输入图像中排名靠前的检测框。
图像搜索,利用Google Image Search来获取与检测到的方框的图像裁剪相关的信息。
在进行决策时,规划器将每条信息的利用都视为一项单独的操作,因为每条信息可能包含数百个token,需要进行复杂的处理和推理。
OCR,在某些情况下,图像可能包含文字内容,如街道名称或品牌名称,使用Google Lens API 中的光学字符识别(OCR)功能获取文本。
网络搜索,使用谷歌搜索API,输入为文本查询,输出包括相关文档链接和片段、提供直接答案的知识图谱面板、最多五个与输入查询相关的问题。
实验结果
研究人员在Infoseek和OK-VQA数据集上对AVIS框架进行了评估,从结果中可以看到,即使是健壮性非常好的视觉语言模型,如OFA和PALI模型,在Infoseek数据集上进行微调后也无法获得高准确性。
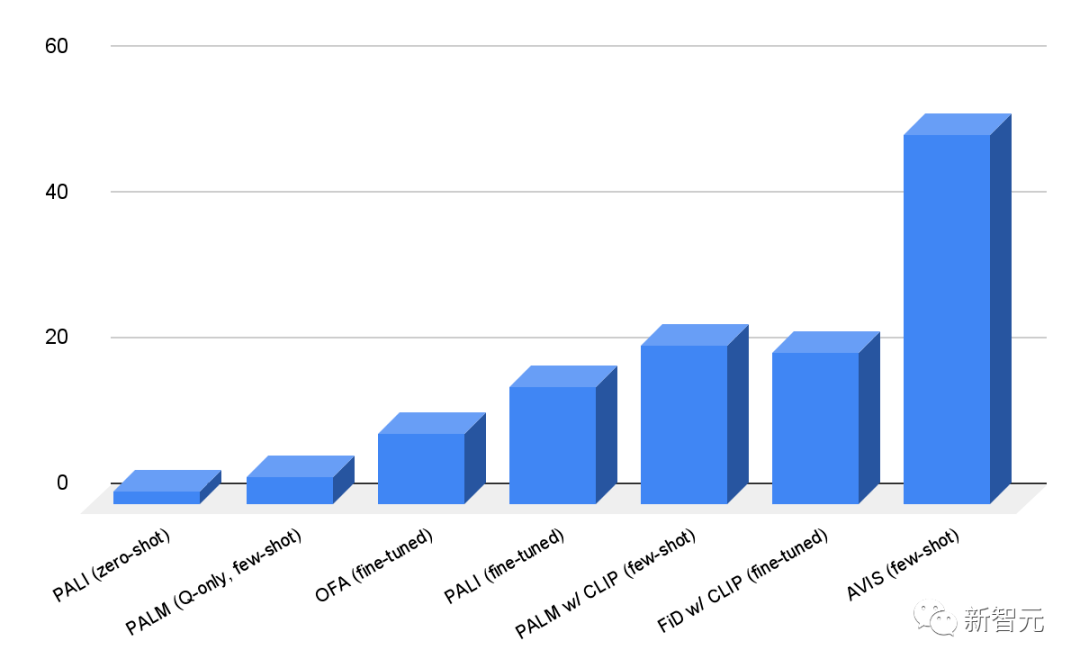
而AVIS方法在没有微调的情况下,就实现了50.7%的准确率。
在OK-VQA数据集上,AVIS系统在few-shot设置下实现了60.2%的准确率,仅次于微调后的PALI模型。

性能上的差异可能是由于OK-VQA中的大多数问答示例依赖于常识知识而非细粒度知识,所以PALI能够利用到在模型参数中编码的通用知识,不需要外部知识的辅助。
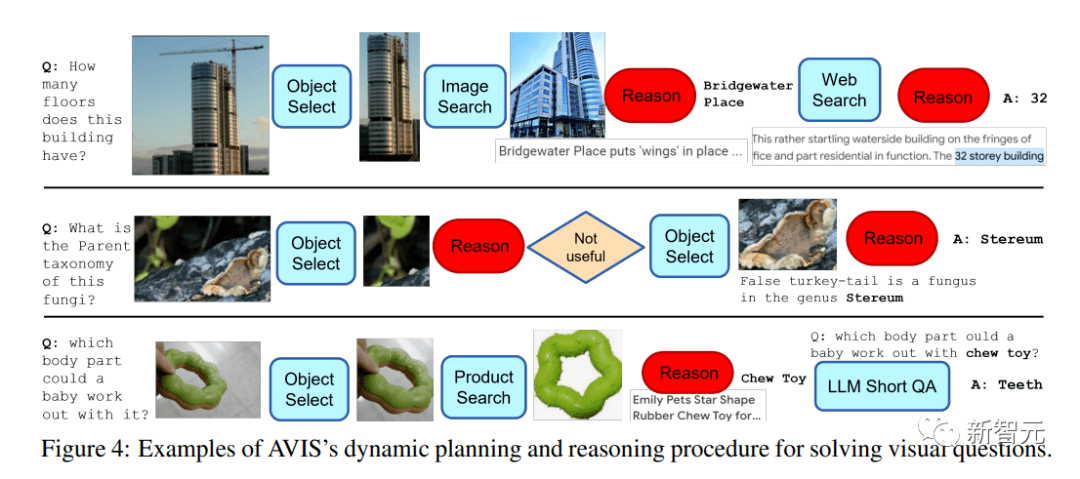
AVIS的一个关键特性是能够动态地做出决策,而非执行固定的序列,从上面的样例中可以看出AVIS在不同阶段使用不同工具的灵活性。
值得注意的是,文中推理器设计使AVIS能够识别不相关的信息,回溯到以前的状态,并重复搜索。
例如,在关于真菌分类学的第二个例子中,AVIS最初通过选择叶子对象做出了错误的决定;推理器发现与问题无关后,促使AVIS重新规划,然后成功地选择了与假火鸡尾真菌有关的对象,从而得出了正确的答案,Stereum
结论
研究人员提出了一种新的方法AVIS,将LLM作为装配中心,使用各种外部工具来回答知识密集型的视觉问题。
在该方法中,研究人员选择锚定在从用户研究中收集的人类决策数据,采用结构化的框架,使用一个基于LLM的规划器,动态地决定工具选择和查询形成。
LLM驱动的推理器可以从所选工具的输出中处理和提取关键信息,迭代地使用规划器和推理器来选择不同的工具,直到收集出回答视觉问题所需的所有必要信息。
参考资料:
https://the-decoder.com/googles-avis-aims-to-answer-tricky-questions-about-images-by-searching-the-web
https://ai.googleblog.com/2023/08/autonomous-visual-information-seeking.html