Apache Iceberg 在严选批流一体的实践
Iceberg是数据湖解决方案中比较热门的方案之一,通常用于批流一体中数据存储的组织实现,希望通过本文让大家了解到严选是如何从老的Lambda架构升级到基于Iceberg的批流一体架构,并在落地过程中解决的一系列问题和做了哪些改进优化。
一、 前言
Iceberg是数据湖解决方案中比较热门的方案之一,通常用于批流一体中数据存储的组织实现,希望通过本文让大家了解到网易严选是如何从老的Lambda架构升级到基于Iceberg的批流一体架构,并在落地过程中解决的一系列问题和做了哪些改进优化。本文主要围绕下面四个方面展开:
- 网易严选数据架构
- 基于Iceberg的批流一体实现
- Iceberg表治理
- 在严选的落地情况&未来规划
二、 严选数据架构
1、数据架构现状
在严选,线上数据的来源主要包括MySQL binlog数据和日志数据,这些数据被收集到kafka后有两个去向,一部分是用于离线批计算,一部分用户实时流计算。离线批处理我们主要使用spark计算引擎,而实时计算则主要使用flink流式计算引擎。
原始数据被同步至ODS层后,数据开发团队基于ODS层数据进行输出建模,并将最终结果数据同步至Doris、redis、ElasticSearch等其他存储,然后给更上层的产品提供服务。
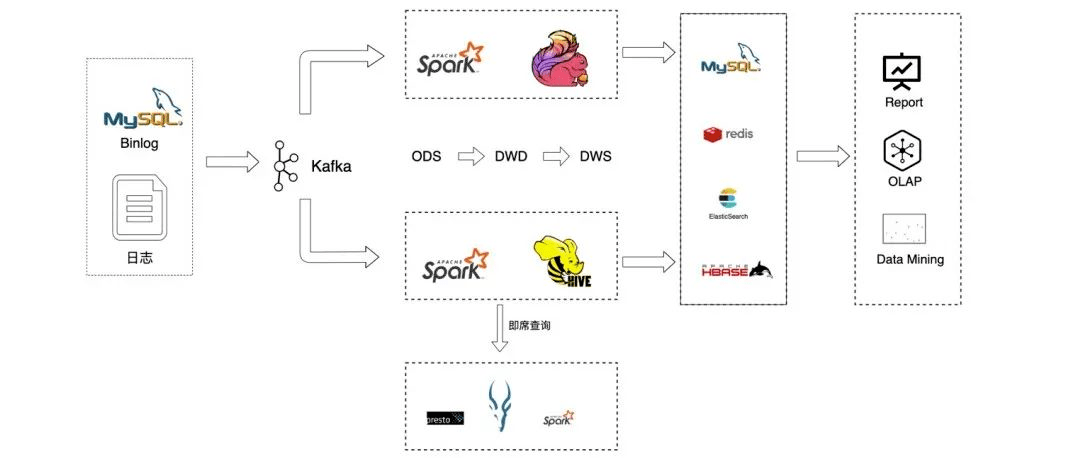 图1 严选数据链路
图1 严选数据链路
数据集成是数据平台的重要组成部分,如图1所示是严选数据入仓的整个流程。主要细分为日志入仓和binlog入仓:
- 日志数据入仓的过程是通过Flume收集然后发给kafka消息队列,基于flink实现hound任务会提取原始日志信息,把非结构化的信息结构化之后落到ODS层;
- Mysql数据入仓是通过数据集成平台dataX完成全量的数据同步,然后通过canal收集增量的binlog数据推送到kafka消息队列,再通过自研的Datahub Streaming任务将原始binlog数据落地到hive,再基于这些原始binlog数据通过按天的spark任务生成T+1的快照数据,然后提供给离线数仓使用。
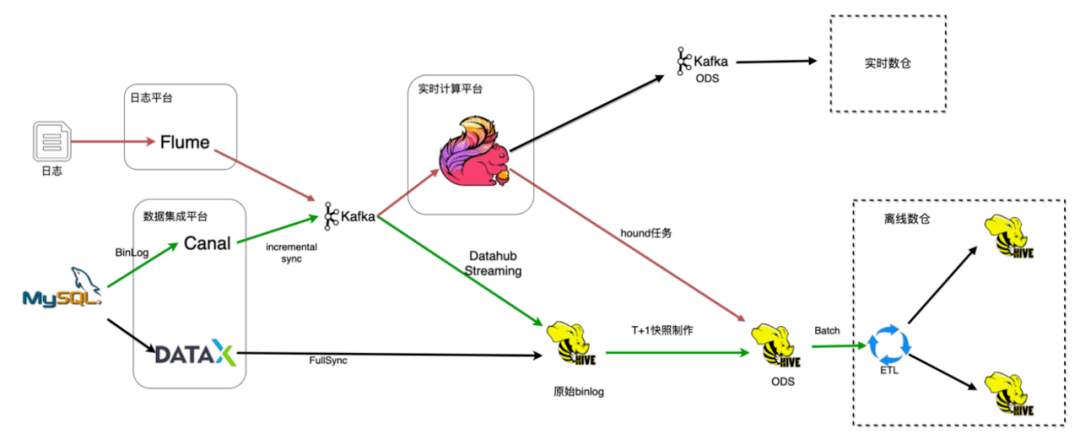 图2 数据集成流程
图2 数据集成流程
2、存在的问题
现有的架构存在如下几个问题:
- 两套架构开发成本高:Lambda架构,实时和离线是两套处理逻辑,需要实现两套代码,引入两种不同的计算引擎,数据开发成本高。
- 离线时效性低:时效性依赖快照的制作频率,但频率越高,占用的存储计算资源越高。
- 维护成本高:两套架构,组件多,链路长,带来更大的组件维护成本。
3、方案选择
针对上面的问题,社区有很多解决方案,比较热门的是Iceberg、Hudi、DeltaLake三剑客,都支持upsert、事务、TimeTravel,并且hudi的索引可以支持快速查询,而且这三种方案都提供了文件合并文件清理等丰富的管理工具。
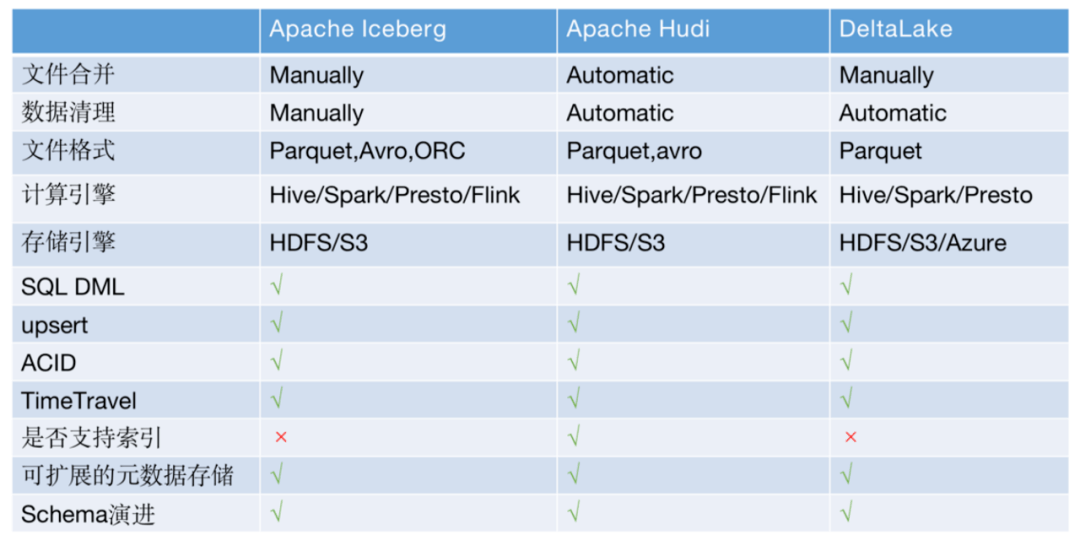 图3 解决方案对比
图3 解决方案对比
严选根据当时社区发展情况和严选当时的需求场景最终选择了Iceberg,主要考虑因素如下:
- Hudi在严选方案调研期间和spark是强绑定,同期与同样依赖spark的Deltalake相比功能并不是很完善(hudi现在已经不强依赖spark)。
- DeltaLake功能完善,merge功能也非常简单易用,非常适合严选的binlog同步场景。但是它需要用spark streaming来做数据同步,而在严选流式计算主要是flink计算引擎,两者在长期发展路线上并不匹配。
- Iceberg定位是一种表格式,其在设计上做了很好的抽象,没有强绑定计算引擎和存储组件,并且当时社区版本也支持upsert等功能。
三、基于Iceberg的批流一体实现
1、流批一体架构
数据入仓架构变化如图4所示,日志收集没有变,依然通过Flume收集到kafka,新增了一个kafka2kafka的AutoETL,用于对kafka的原始消息进行解析转换,并且配置了清洗算子做一些轻量的数据清洗工作,例如字段提取和时间转换等操作。
之后把结构化的数据写到kafka的ODS层,得到了实时的ODS数据,再把ODS数据实时落到Iceberg。
Iceberg的upsert功能可以很友好的处理数据库的变更,但它的数据延迟依赖flink的checkpoint,在一些毫秒级的场景Iceberg并不适用,所以严选部分的实时场景依然通过kafka消息队列来实现。
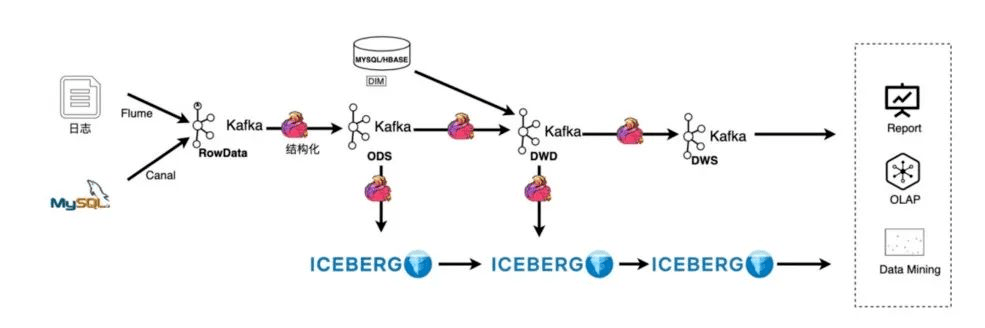 图4 数据入仓(流批一体)架构
图4 数据入仓(流批一体)架构
2、新的问题
架构演进过程不是一蹴而就的,上游修改后,会影响下游使用,所以让下游业务无感知或较少感知的切换是架构升级带来的挑战。在落地过程中主要面临如下2个问题:
- Kafka消息乱序和重复:原方案是拿到所有的快照通过排序去重,在实时写入时,这么做的成本非常高。
- 离线数仓数据没有T+1快照:落到Iceberg的数据是准实时的,需要基于Iceberg的数据制作T+1的快照。
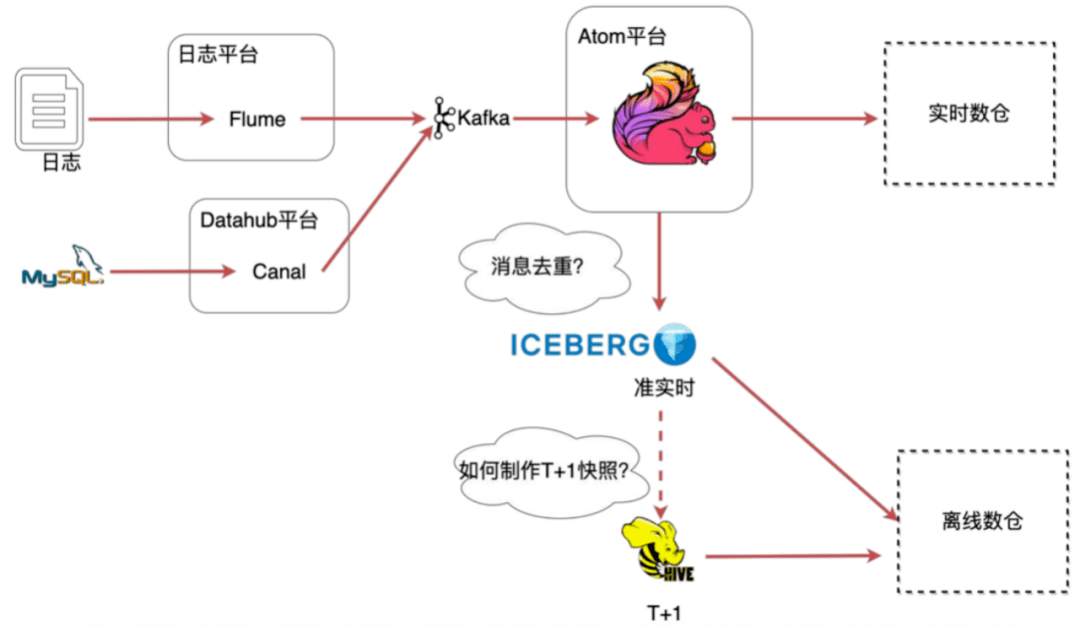 图5 新的问题
图5 新的问题
1)消息乱序和重复问题
在消息传输过程中很有可能出现消息乱序和消息重复等问题,例如图6所示的传输场景,00:13分的数据在00:14分被消费,直接更新00:14分的表会让id为1的数据被晚到的旧数据覆盖导致最终数据错误。
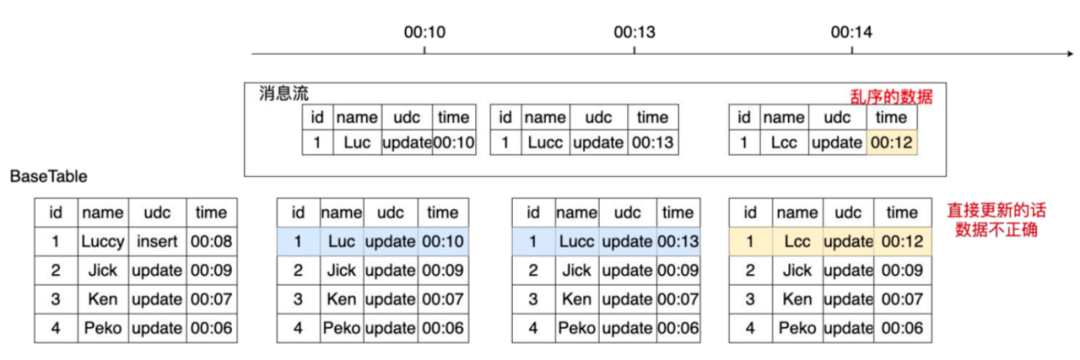 图6 数据传输(乱序)
图6 数据传输(乱序)
对于消息乱序问题有两种方式解决:
- 方式1:如图7,先回查底表,查询当前记录的时间,当前记录的时间比新消息的时间更晚的话就会把消息丢弃,来达到去重的效果。
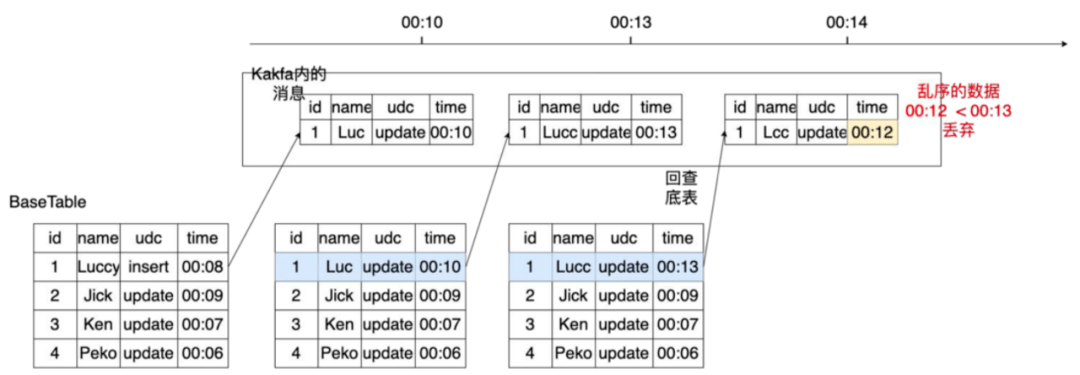 图7 数据去重(丢弃)
图7 数据去重(丢弃)
- 方式2:如图8,还是回查底表,如果底表的数据时间比新消息时间晚,那么先写晚到的消息,然后再补一条之前的数据,来保证最终数据是正确的,即最终一致性。
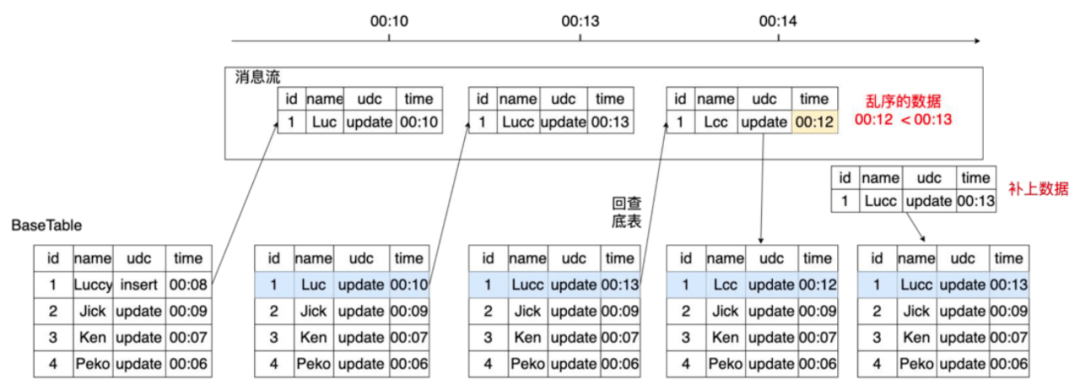 图8 数据去重(回补)
图8 数据去重(回补)
虽然有两个方式,严选最终选择了第二种处理方式,因为这种方式保留了所有消息,如果选择第一种方式把数据丢弃,当后续需要制作某一时间的快照就会因为丢失了数据而无法制作出正确的快照,例如当需要制作00:12的快照时,用第一种方式制作的快照数据是缺失的。
不管是哪种方式都需要回查底表,而在底表非常大的场景下,每个消息都回查,查询频繁并且查询性能较差。所以为了降低查询频率,提升查询性能我们又做了一些改进:
- 通过写入时增加缓存和统计信息,通过这部分信息增加过滤逻辑减少查询频率;
- 通过表治理,加速查询速度,来解决查询效率慢的问题。
2)增加缓存及统计信息加速查询
通过加缓存和统计信息后过滤来减少查询频率,例如给定消息M,根据主键查缓存,如果命中在缓存中,就直接比较M消息与缓存中的时间,如果乱序就继续查底表;如果未命中缓存,会去查内存中的统计信息(统计信息保存了topic+partion+schema的一个key信息,包含了topic最大partion的处理时间),通过统计信息判断partion级别是否有乱序,如果有乱序也会直接查底表,未命中统计信息时也会查底表,其他情况视为正常就不做任何处理。
这两种方式可以把很多乱序的消息过滤出来,降低查询频率,但这两种优化的假设是大部分数据是顺序的而非乱序的,乱序会导致命中率低,为了解决乱序问题下面还会介绍排序的优化。
3、一致性快照
Iceberg数据更新是准实时的,直接查询最新的数据无法得到某一时刻的快照数据。
例如图9,我们想要00:03分的快照,直接查id为1的数据实际是00:04分的数据,显然是不正确的。
这里我们使用Iceberg的数据回溯功能,Iceberg每次提交都会产生新的版本快照,并在元数据中记录dataFile和deleteFile等元数据信息,我们在制作特定时间快照的话,可以通过回溯历史版本,找到符合条件的快照版本,在读的时候根据指定时间把不符合条件的记录过滤掉跟原始数据合并就可以得到该时间的快照。
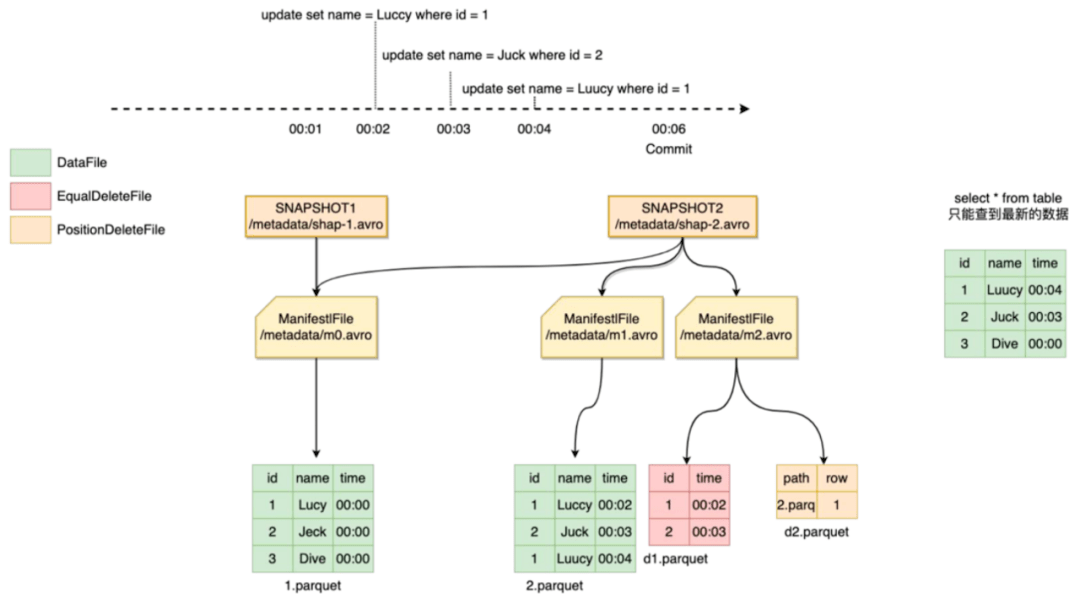 图9 一致性快照
图9 一致性快照
制作的具体过程为:
- 给定时间T0,查找最近一个满足max(eventTime)<=T0的snapshot s1;
- 查找s1之后所有新增的dataFile和deleteFAIle集合记为{F0};
- 从集合{F0}中剔除所有满足min(eventTime)>T0的文件得到文件集合{F1};
- 遍历{F1},过滤出所有满足eventTime<=T0的数据,记为集合{D};
- S1与{D}合并得到T0时间的一致性快照。
例如我们要做00:03分的快照,如图10、图11所示,最新的snapshot是snapshot2,比00:03分小的最近的snapshot是snapshot1,然后查找snapshot1之后的变更dataFile和deleteFaile并过滤掉00:03分之后的记录,snapshot1与过滤后的记录合并得到00:03的快照表。
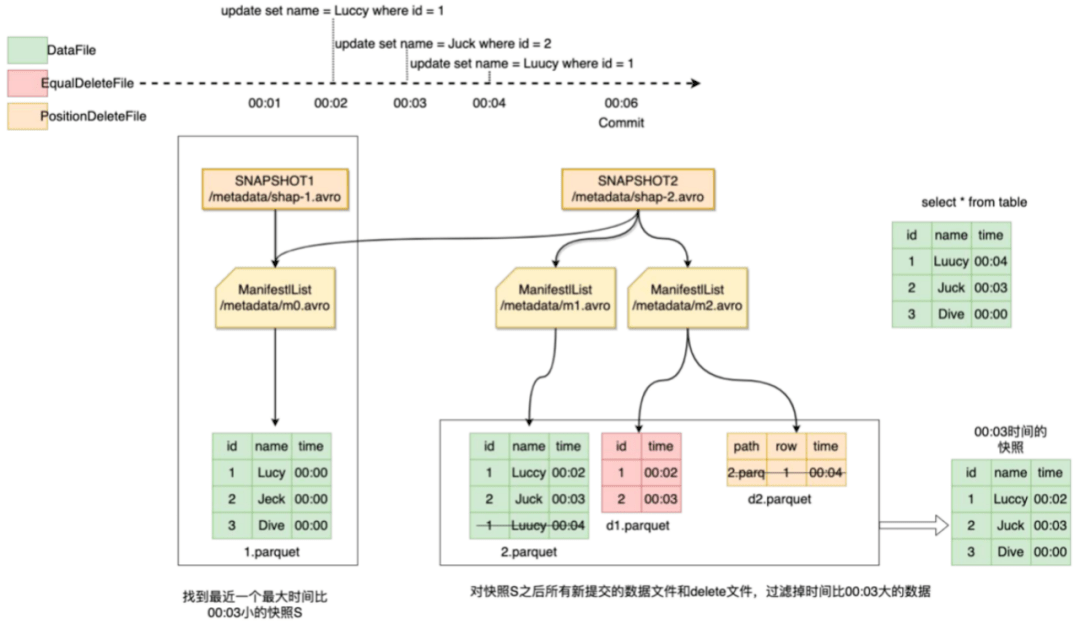 图10 一致性快照
图10 一致性快照
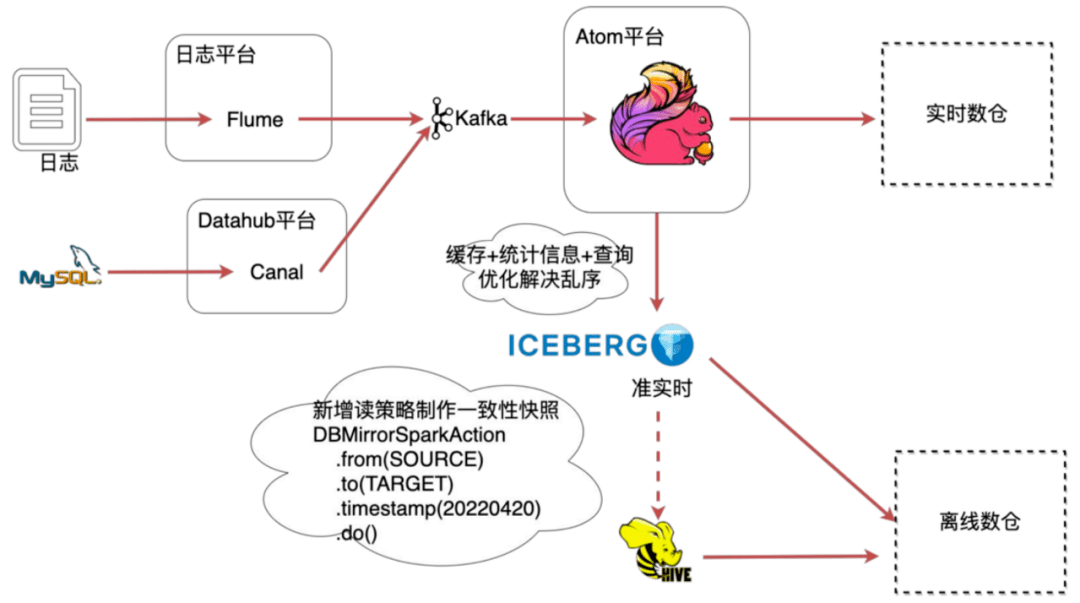 图11 一致性快照
图11 一致性快照
四、Iceberg表治理
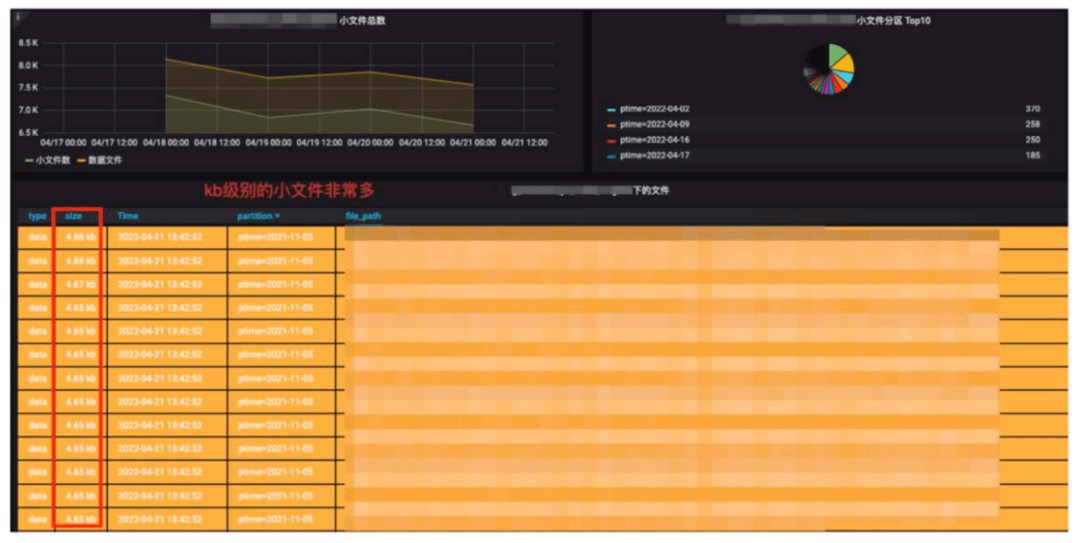 图12 Iceberg存储监控
图12 Iceberg存储监控
Iceberg每一次提交都会产生新的文件,文件大小跟提交频率和数据量有很大关系,我们在生产环境是10分钟一次Checkpoint做一次提交,我们发现有些数据量并不是很大的日志数据和数据库变更,会产生很多的百KB级别的小文件。
而小文件变多后会导致查询性能下降、存储效率低等很多问题,所以严选建立了表治理服务:DataCompactionService、DataRewriteService、DataCleanService。
- DataCompactionService服务主要用于合并dataFile、deleteFile、元数据;
- DataRewriteService主要用于dataFile的重排序和deleteFile重写(把EqualDeleteFile转化成了PositionDeleteFile);
- DataCleanService主要用于清理孤儿文件(异常情况下会导致存在一些不被表引用的临时文件)和历史过期快照。
下面着重介绍下DataRewriteService的deleteFile重写和重排序功能。
 图13 Iceberg数据治理服务
图13 Iceberg数据治理服务
1、重写&合并deleteFile
Iceberg文件组织分为deleteFile、EqualDeleteFile、PositionDeleteFile,如图14所示,EqualDeleteFile根据数据文件的主键删除重复的记录,PositionDeleteFile记录了要删除记录的文件索引,例如file_3的第一行,SeqNum的作用域只在比自己小的所有数据集里。
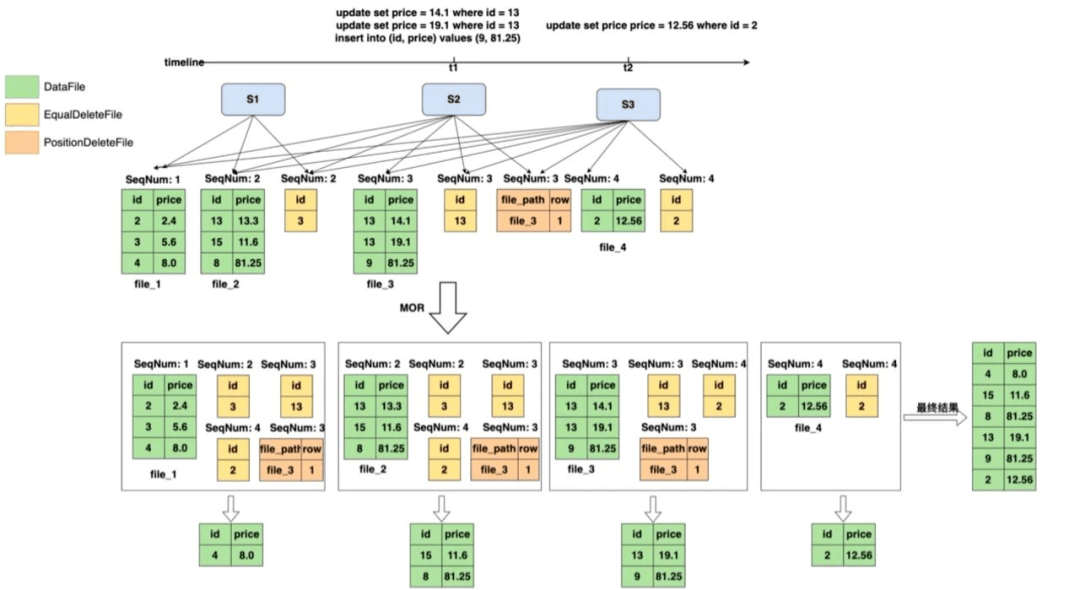 图14 重写deleteFile
图14 重写deleteFile
但当deleteFile非常多的时候,查询的性能会变得极差,因为他需要和每一个dataFile进行字段过滤,判断是否需要将记录从dataFile中删除过滤。而positionDeleteFile无需进行记录判断,只需要判断文件位置,效率相比于equalDeletFile好。
为了提升过滤性能,我们通过DataRewriteService把EqualDeleteFile转化成了PositionDeleteFile,为了解决PositionDeleteFile过多的问题,可以把多个小PositionDeleteFile合并为一个大的PositionDeleteFile,来减少文件数量,并且得到的结果是一样的,过程如图15、16所示。
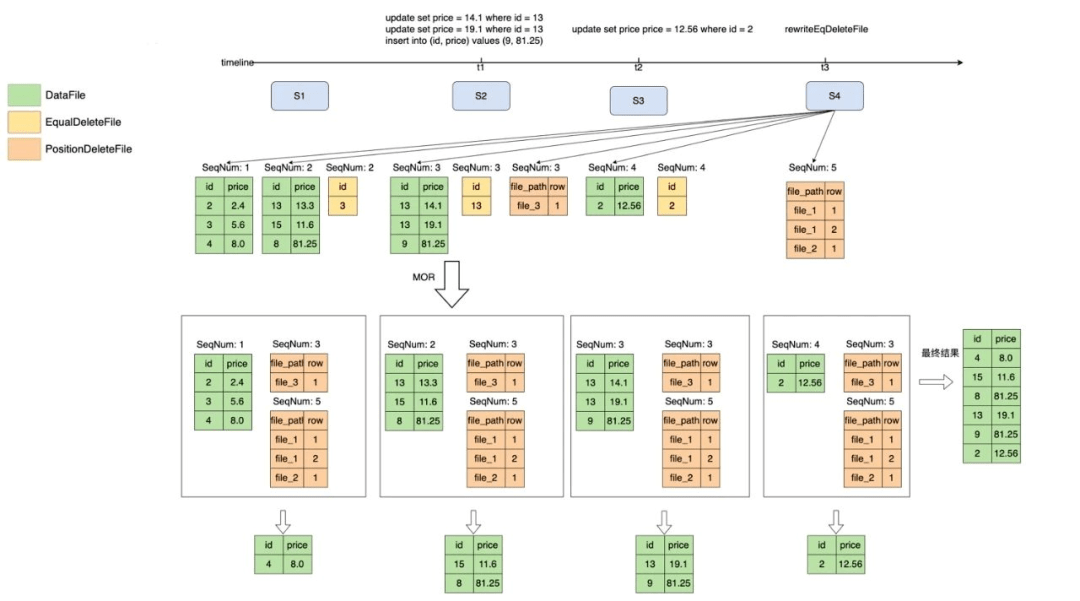 图15 重写deleteFile
图15 重写deleteFile
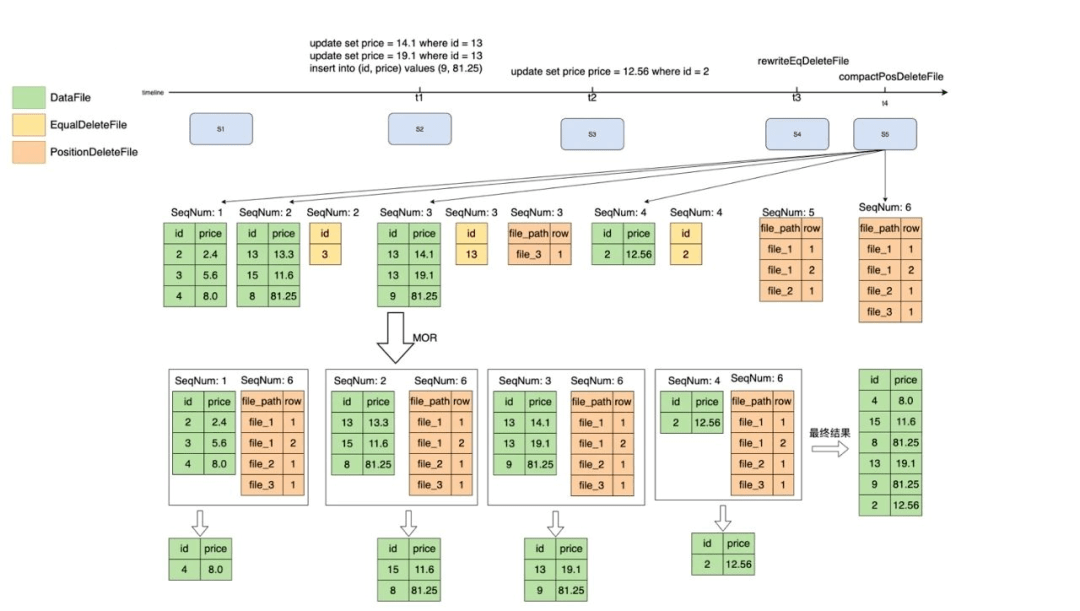 图16 合并deleteFile
图16 合并deleteFile
2、重排序
Iceberg在元数据中记录了每一个数据文件中的统计信息,包括每一列的最大值/最小值,在进行查询的时候,就可以根据where条件中的值和文件中min/max值进行比较来判断是否需要读取该数据文件。
如果在数据写入的时候不做任何处理,min/max的过滤效果是非常差的,因此在实践过程中我们会根据主键进行重排序,主要目的是为了提升在上文“增加缓存和统计信息的优化”中的命中率。
实现过程如图17所示,根据主键进行一个重新排序,让每个文件的数据是有序的,之后再根据主键查询的时候,根据min/max就可以过滤到很多没有用的dataFile。
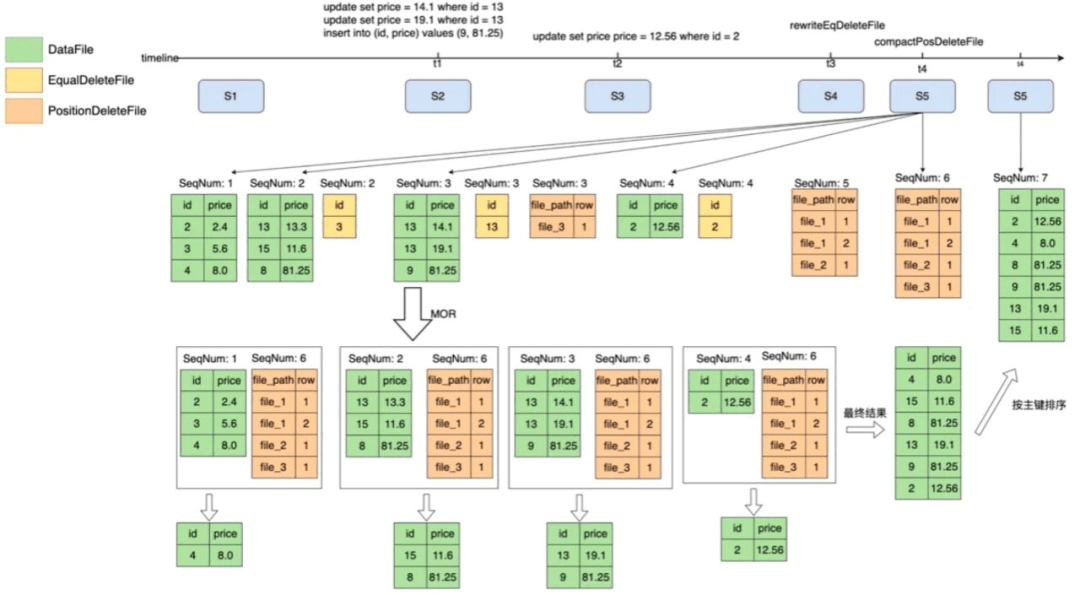 图17 重排序
图17 重排序
经过缓存统计信息过滤优化、小文件合并、重写deleteFile、重排序这一系列优化可以看到数据处理前后(绿色是处理前的和黄色是处理后的)的耗时对比差异,大部分查询效率可以提升10倍以上!
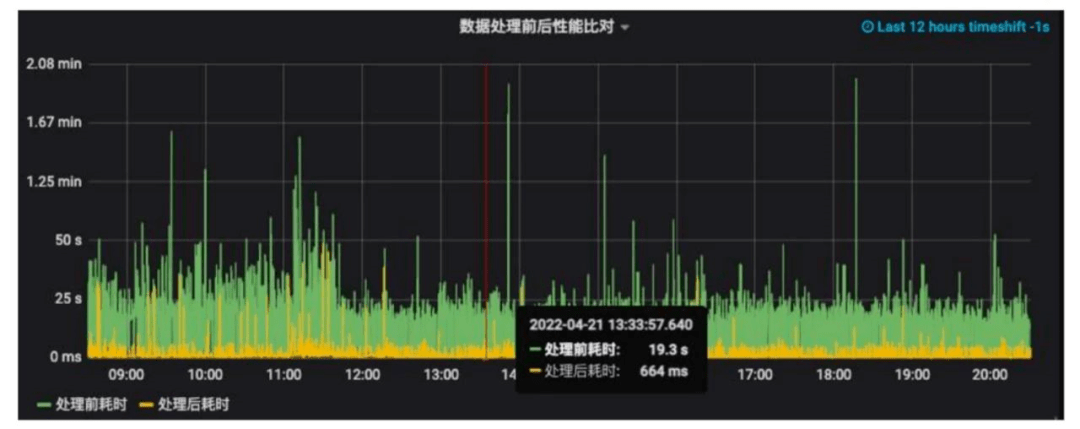 图18 治理效果
图18 治理效果
五、 落地情况&未来规划
落地情况如下:
- 完成ODS层数据产出的批流融合
- 离线数据延迟缩短至5分钟
- 所有ODS T+1快照的制作时间可提前半小时
- 已有500+任务稳定运行
在未来期望能探索更多的业务场景,例如在特征工程和数仓DWD加工场景也实现批流一体。在查询体验上,计划让presto也接入iceberg的支持,引入Alluxio缓存来加速元数据的加载和缓存数据,加入Z-order数据重排序和Bloom-Filter文件索引等功能提升查询效率。另外把文件监控、健康检查等功能产品化以提升易用性。
作者丨祝佳俊
来源丨严选技术团队(ID:YanxuanTechProd)