线上内存泄漏!如何破案
作者:rangobai,腾讯CSIG数据工程师
| 导语要有性能意识,量变引起质变,简单如一行日志都会在高并发的情况引发血案,考验着研发的技术功底
一 案件背景
9月的某个上午,业务侧突然反馈线上数据服务响应慢,造成任务积压,正常情况下耗时5ms的服务,单次响应达到了5s量级. 收到反馈后我们马上开始排查服务状况,但发现各项指标很健康,接口平均耗时3ms,p99约为1s,和经验值比无太大差别. 业务侧随后补充反馈是某些请求很慢,感觉是若干pod有问题,当流量打到这几台机器时就会变慢.
开始怀疑是网络问题,但没有证据.随后小库网关的一台机器突然宕机,这个现象引起了我们注意.在上次迭代中,我们服务有一次重大升级,所有请求均会经过网关服务转发,以实现Server/DB单元化绑定,问题可能出在转发环节.
为了验证猜想,我们重启了网关,随后业务侧积压现象迅速消失,排查范围锁定网关服务.
二 调查过程
小库网关本身无太多业务逻辑,依赖项非常少,为了实现时间最小损耗,技术框架采用spring cloud gateway,底层WebFlux 则使用了高性能的 Reactor 模式.在上线前的多次压测中,网关服务表现非常优秀,时间损耗基本在毫秒级别.万万没想到上线没几天就挖了个大坑,必须要刨根问底调查清楚
2.1 第一次定位
由于刚迁移到新私密机房,可用于问题还原的监控手段不多,刚开始只能从查看pod云监控以及日志着手.
首先查看日志异常 :可以看到确实有大量PT5S超时存在,但是根据traceId追踪大多数超时请求在服务侧均为毫秒级响应.
其次查看业务侧请求量变化:虽然我们服务有过qps破万的表现,但是问题时间段请求量异常的平稳,甚至略有降低.
最后查看问题时间段性能表现:cpu在40%左右,无突增现象.Pod内存监控由于JVM提前分配,无太大参考价值.I/O流量在问题时间段没有波动.
磁盘满了
此时没有清晰的调查方向,就在我们黔驴技穷的时候,又一台网关pod重启了,我们同学迅速登录机器,查看案发现场-磁盘爆满, 200G的云硬盘在上线的两天内就被打满,请求block.线上请求量其实大大超出我们的预估,生产日志量接近10G/小时/台, 日志保留7天的策略顿时显得不合时宜.
随后我们清理了所有pod的日志,并采取了两个策略:
- 日志清理策略设为保留1天,因为有日志本身上报cls,保留太久日志没有必要
- 清理无效日志,打印要有技巧性,不是越多越好,高并发下对服务伤害性越大.
修改上线后,服务运行平稳,再也没出现上午的问题,调查小组愉快的度过了第一天.
2.2 第二次定位
就在以为我们万事大吉的时候,现实光速打脸,第二天早上8点半,生命线里出现大量异常警告,随后网关服务陆续重启,登录机器,磁盘利用率10%,尴了个尬.
CPU问题三板斧
因为自动重启没有保留案发现场,所以只能在昨天的基础上继续调查.
第一个合理怀疑的方向是CPU,虽然CPU利用率40%不能算很高, 但网关和业务机器比达到了1:2,对于仅转发请求的网关来说仍然是不正常的高了.排查此类问题就要启动CPU问题三板斧了
第一板斧: jps查看JAVA进程ID 46
第二板斧: top -Hp 46 查看进程所有线程的活动
可以看出仍然是log4j2的101线程占用了最多的CPU能力,
最后一板斧: jstack pid 查看线程活动,以定位线程堆栈
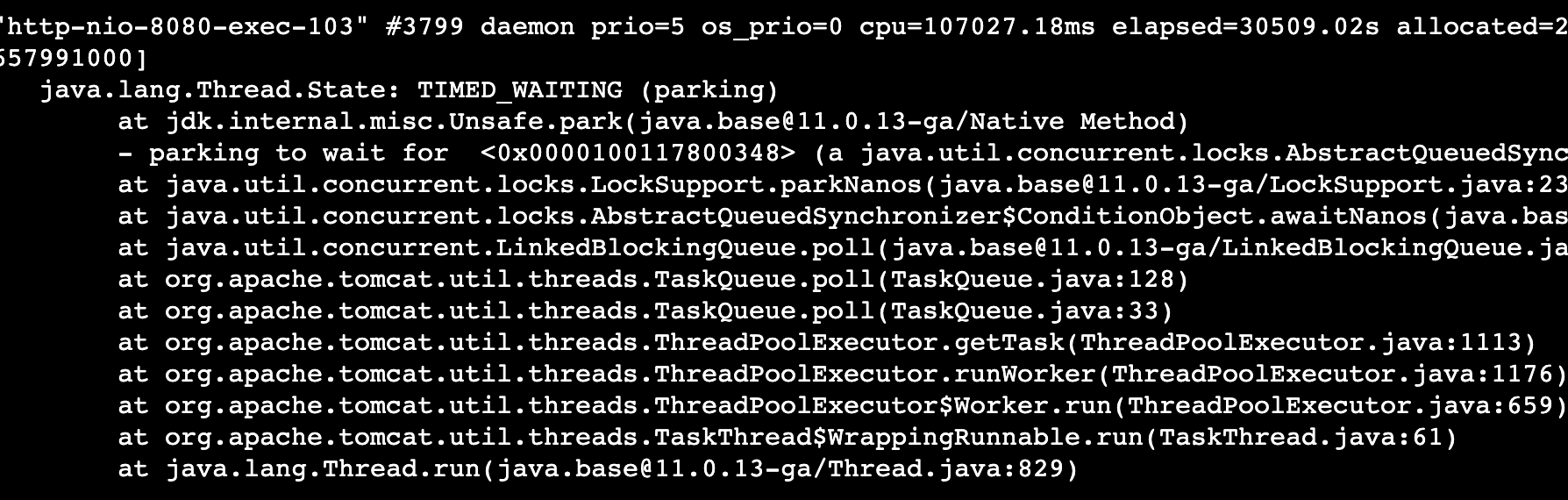
这个时候,日志打印占用了最多cpu已经一目了然.
最大利器Arthas
但是作为成熟的研发,我们当然不满足于三板斧调查问题,这时候就要请出线上另一大杀器arthas :profiler | arthas,以下介绍来自官网:
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率Arthas(阿尔萨斯)能为你做什么?这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!是否有一个全局视角来查看系统的运行状况?有什么办法可以监控到 JVM 的实时运行状态?怎么快速定位应用的热点,生成火焰图?怎样直接从 JVM 内查找某个类的实例?
不得不说,阿里在java技术积淀远超我司.因为之前已在镜像里面集成了阿尔萨斯,我们立即启动cpu profiler采样生成火焰图.

果然除了日志打印以外,我们又发现了一处CPU热点

这两个地方合计占掉了60%以上的性能.
CPU高的原因
首先分析一下日志占用过高,这是一个使用log4j2的问题,涉及日志打印参数调优,我们之前已经优化过一轮的参数
#RingBuffer大小 AsyncLogger.RingBufferSize=524288#日志等待策略sleepAsyncLogger.WaitStrategy=SLEEP#Ringbuffer满了后直接丢弃log4j2.AsyncQueueFullPolicy=Discard
理论上这已经是性能最好的日志策略,为什么会出现占用CPU负载的问题?
问题出在LockSupport.parkNanos上,简单来说当日志消费速度赶不上生产速度的时候,日志线程会调用这个方法自旋等待若干纳秒,在线程数少的时候性能影响不明显,但是在高并发的情况下会造成大量线程在短时间内频繁唤醒/等待,从而影响业务性能.解决方案:是把自旋的时间间隔调大,如下
AsyncLogger.RingBufferSize=524288AsyncLogger.WaitStrategy=SLEEPlog4j2.AsyncQueueFullPolicy=DiscardAsyncLogger.SleepTimeNs=500
分析下第二个CPU热点,这个问题没那么复杂

是一个对象深拷贝的性能问题,每次请求来的时候都会将一个大对象先序列化在反序列化,这个在请求量低的时候影响较小,但是在我们每天几千万的请求量冲击下,性能瓶颈非常明显.
讲一下对象拷贝的四种解决方案:
JSON : 非常规,吃CPU
Apache BeanUtils :性能最差,不建议使用
Spring BeanUtils: 性能稍好
MapStruct MapStruct – Java bean mAppings, the easy way!,性能无损,推荐!!
具体各自的拷贝原理不再深入分析,大家可以搜资料查看
热点问题解决了
给一下优化前后的CPU对比,以下优化结果是在请求量翻倍同时pod数减半的CPU表现:
优化前: 45%+
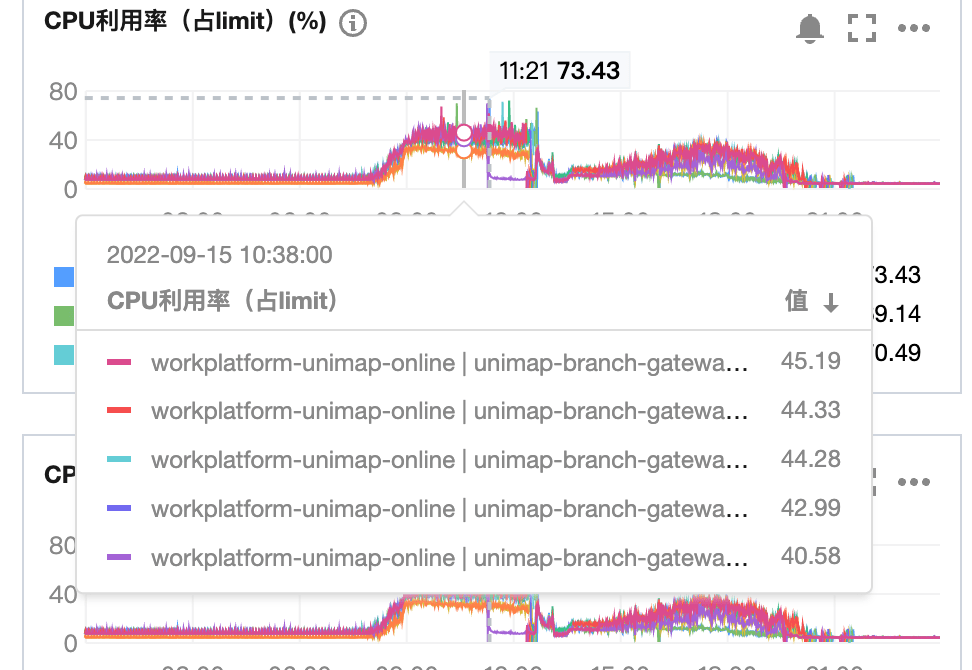
优化后: 11%

2.3 最终定位
随着一步步的分析,我们也越来越接近问题的真相: CPU虽然有点高,但仍不足以解释缓慢和重启的现象,另外问题是在线上请求量增大以及随时间推移逐渐暴漏的,几乎可以断定网关存在内存泄漏.于是我们把调查重点投向JVM内存,布下天罗地网,静等凶手再次犯案.
功夫不负有心人,在部署约一天后,几台服务器又开始重启,我们迅速登录还未重启的机器,执行以下操作
- 首先查看jvm内存已经逼近100%
- GC非常活跃且无效,大量的内存无法回收
- 通过火焰图查看的CPU绝大部分在执行GC
- jmap -dump:format=b,file=heapdump.phrof pid 生成内存dump并上传cos
这个时候就要请出排查内存问题的另一大杀器Jprofile,具体资料可以在网上搜,这里主要介绍定位过程.
首先查看内存分布,有1000W+的ImmutableTag,不是我们的业务对象...非常意外
其次查看大对象,SimpleMeterRegistry占用了80%的内存空间!!!
这两个类均属于io.micrometer的核心组件,用来暴漏服务参数供监控使用.Micrometer中包含的SimpleMeterRegistry,它在内存中维护每个meter的最新值.
再一次分析内存中保留的对象内容
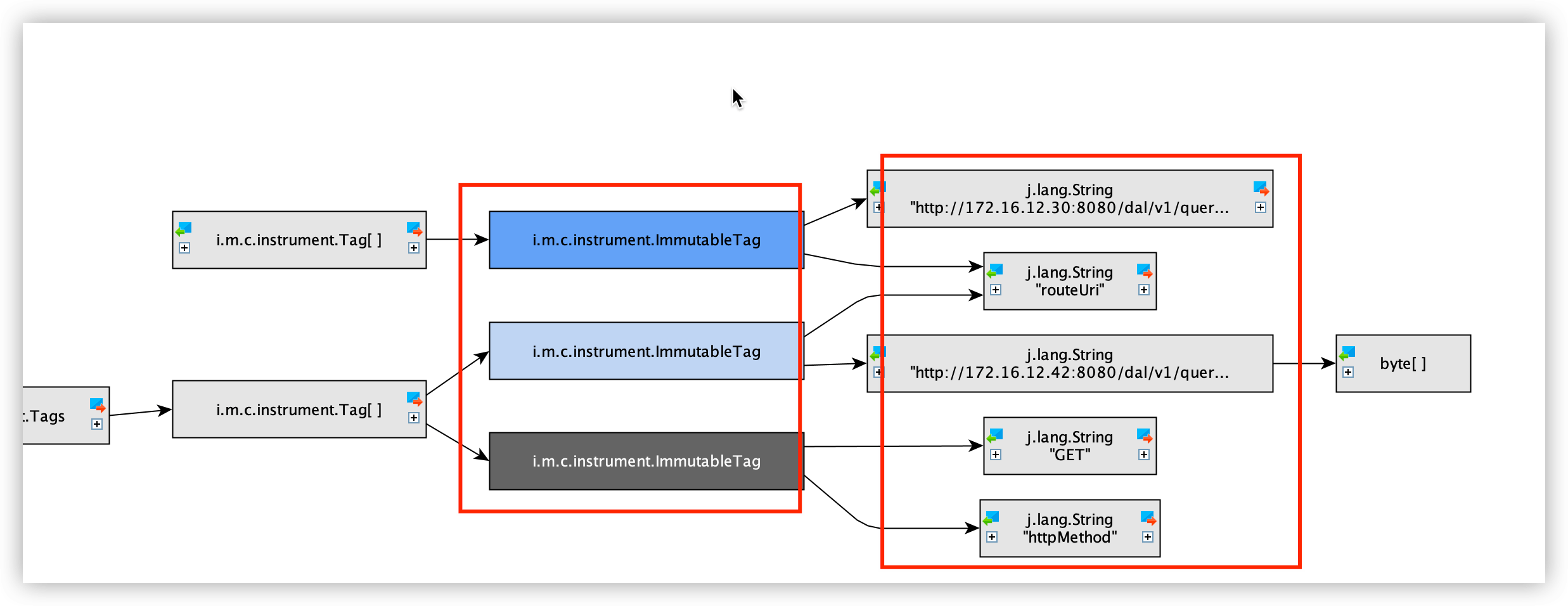
可以看出1000W+的对象中,全部记录的是我们每次请求的RouteUri Method 耗时等信息,通过关键字定位,这些对象生产的源头是GateWay的 GatewayMetricsFilter组件,这里会记录所有路由请求的信息apply到micrometer中.而这个GatewayMetricsFilter的启用条件是存在Spring Boot Actuator组件.我们业务中刚好引用了该组件.
至此凶手归案,我们下线Actuator,并手动将GatewayMetricsFilter启动设置为False后,问题彻底解决.
三 内存泄漏原因
但是为什么呢?一个Spring官方提供的监控组件会导致内存泄漏?为什么对象持续无法回收?直觉告诉我们一定是哪个地方不太对劲.珍贵的食材往往需要最简单的烹饪方式,最复杂的场景往往用最朴素的手段抽丝剥茧
3.1 DEBUG过程
幸好我们有一套完整可用的开发环境,足够做场景复现,打好断点触发请求.经过几轮分析,犯案原因也随之浮出水面.
首先还是从SimpleMeterRegistry的引用链开始,(过程比较无聊,不再赘述)
这里存在一条清晰的引用关系,查看MeterRegistry源码,有一个ConcurrentHashMap全局变量
就是这个全局的Hashmap保存了到ImmutableTag的引用关系,导致GC Roots判定引用路径存在,对象存活无法回收.关键代码:
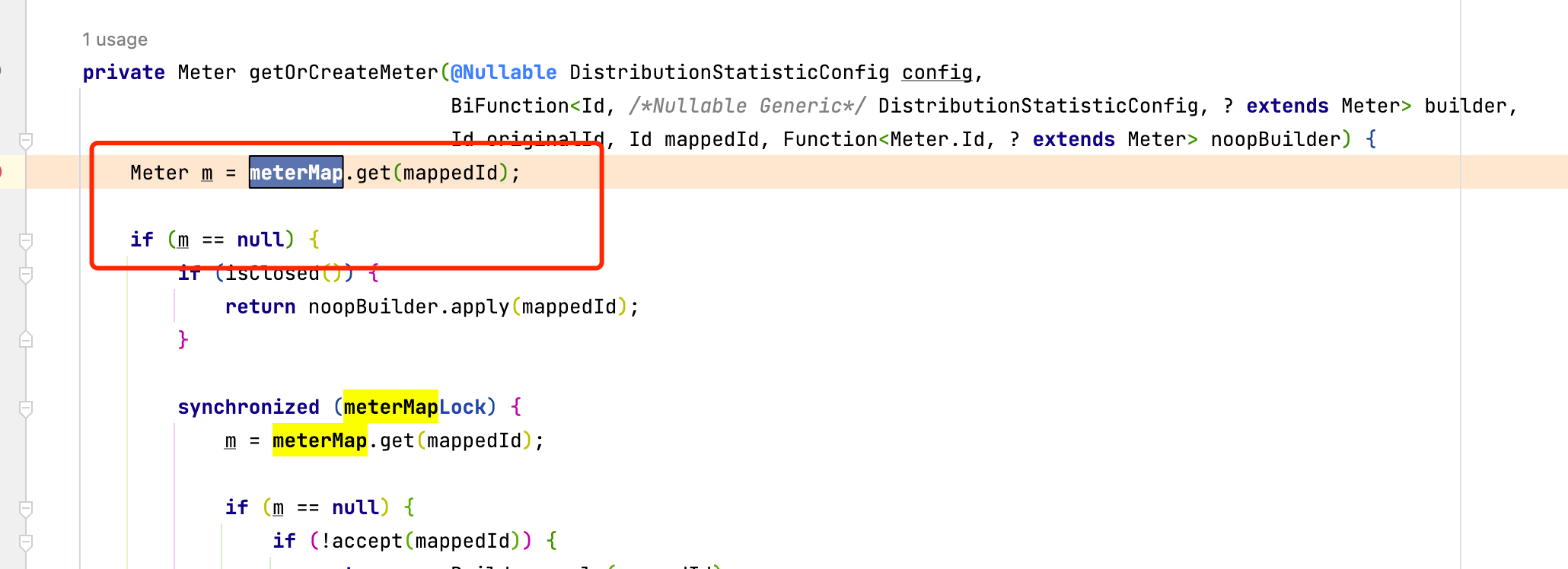
这里判定如果meterMap中不存在mappedId就创建,mappedId是一个DefaultMeter对象,针对我们的业务场景,这个Meter根据Route对象生成.看一下我们的使用方法,为了做到动态路由效果,我们使用了一个全局的filter拦截请求,然后根据算法确定需要转发的目标IP,每次请求都会生成一个新的Route对象

3.2 水落石出
坏就坏在这个newRoute上,因为每次请求的参数不一样,导致我们生成的Route对象也不一样.我们认为Route是请求级别的动态的,每次请求后自然消亡,实际上也是如此.但是万万没想到,站在SpringCloud GateWay或者说站在GatewayMetricsFilter的视角,这个Route是全局的静态,由此引发内存泄漏.
四 经验总结
第一, 要有性能意识,量变引起质变,简单如一行日志都会在高并发的情况引发一起血案,考验着研发的技术功底.
第二,工欲善其事,必先利其器,一款好的工具能够极大提升研发生产力