分析数据库的问题的数据与思路
分析数据库的问题,需要手头有足够的数据来做支撑。不过很多朋友不知道什么情况下需要什么样的数据来做分析,也有些朋友手头有不少数据,但是不知道该如何去分析。
今天我用一个前几天一个微信群里大家讨论的案例来做个分析,因为当时正好在参加一个活动,因此有一搭没一搭的看群里大家在聊这个CASE,具体需要分析什么问题不太清楚,不过这个案例的数据还挺有代表性的。
这是一个Oracle的例子,分析依据是两份awr报告,简单的从awr报告入手,可能看不出特别明显的问题。此类案例普遍存在,分析起来其实不难,不过如果不掌握方法,就不知道该如何入手了。另外,如果我们要分析其他数据库,可能没有Oracle这么强大的AWR数据,能够获得的数据与这个案例差不多,因此这个案例的分析思路对于分析国产数据库也有一定的参考价值。
如果有朋友缺乏用于国产或者开源数据库分析的数据和工具,老白在这里做个广告。可以到“DBAIOPS社区”下载一份D-SMART社区版,1元钱激活,就可以用来监控与分析你的数据库了。D-SMART能够以2-3分钟的频率采集数据库的各种指标,每种数据库都会有数百个到上千个指标可供分析,目前对MySQL/PG/达梦/人大金仓/瀚高/海量/openGauss等数据库的支持还是不错的。近期还将推出支持OceanBase/GaussDB等分布式数据库的专版。
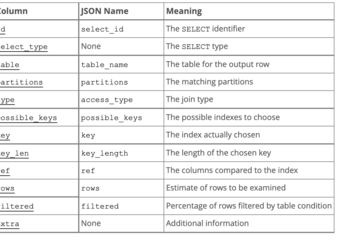
因为我前几天没有仔细看群里的讨论,因此不知道用户到底出了什么问题,只能根据数据来进行分析。从DB TIME这个指标上,我看到两个AWR报告中存在明显的不同。从上面可以看出,8-9点的DB TIME明显要高于5-6点的。不过这种比较一般来说也不大有代表性,因为8-9点可能业务负载要远高于5-6点。分析一个数据库是否存在问题,DB TIME是一个十分重要的分析元素,目前绝大多数国产数据库和开源数据库中也都有这个指标。DB TIME与持续时间的比值,对于本案例来说就是每分钟DB TIME这个指标是有对比价值的,当日如果采样时间是相同的,直接比较这个值就可以了。日常做数据库运维的时候可以关注这个指标,通过这个指标虽然不能定位数据库的问题在哪,不过可以大体判断数据库是否存在异常。
如果数据库支持等待事件,通过等待事件可以对数据库在宏观上是否存在问题做一个初步的判断。看上面的案例,8-9点的TOP EVENT中的等待事件,似乎没有明显的宏观问题。DB CPU排在第一位是大多数系统的常态,因为系统中一般都会存在一些CPU开销较大的SQL。单块读平均响应时间6毫秒,占比16.11%,不知道存储是什么,如果中低端存储这个指标也还可以,如果是高端存储,那么就偏低了。在看TOP EVENTS的时候,我们要注意,11.2.0.3只列出TOP 5,这对于发现系统中存在的问题不一定有效。在这个案例中第五位的等待事件只占1.63,说明其他的等待事件已经对数据库的影响不大了。虽然如此,查看完整的前台进程和后台进程的等待事件的完整数据还是十分必要的。
在这个案例中,和负载略低时的指标相比较,就一眼可以看出问题了,这个案例里,出问题时段的单块读延时慢了1倍,这是一个明显的疑点。在分析这个指标的时候,一定要看waits这个值,如果这个值很小,那么一倍的差异也不一定能说明问题,因为可能存在统计误差。89万和292万次的等待,这种统计值相对来说还是靠谱的,因此这个问题可能真的存在。
除此之外,等待事件是十分正常的,在故障时间段里存在library cache:mutex x等待,不过占比2.46%,在这个案例中可以先作为次要因素来看待。
接下来我们需要看看负载数据,对于Oracle AWR来说,Load Profile是能够完全反映出负载的。其他数据库也存在类似的负载数据。
比如上面是D-SMART采集的部分PG数据库的负载数据。上面的AWR数据中,可以看出数据库的负载并不算高,物理读每秒大约50M左右,每秒执行数不到3000,硬解析10个。疑点是每秒20个的logon,5-6点的报告中,这个指标是1.3,不过8-9点很可能是大量用户正在登录的时候。因为对整个项目背景不了解,因此不清楚这么多LOGON是否是正常的。
CPU上看,CPU资源还是出现了轻微的瓶颈的,这个服务器的配置不高,不知道是老的服务器还是虚拟机,总共4 socket 16核。
接下来可以看看等待事件的明细情况。从总体的情况来看,还是没有太大问题的。Ksdxexeotherwait这个问题很可能是11.2.0.3的BUG导致,这也可能是引发共享池与CURSOR相关等待的主因,从上面的等待事件看,确实是这些指标存在一些问题。其他指标还算合理。Log file sync 7毫秒是有点高的,在5点的报告里是2毫秒。看一下后台进程的log file parallel write指标是4毫秒,而5点时是2毫秒。从这些指标上看,业务高峰期,存储的性能是存在一定的问题的。因为这份报告是不全的,因此我无法去通过数据文件IO去分析是否文件IO存在性能问题。同时通过分析TOP SEGMENTS的数据来查看哪些表或者索引上物理读较高。
对于Oracle数据库,如果发现数据库层面的IO性能问题,是可以通过osw数据来进行验证的,看看OS层面是否也存在IO性能问题,并判断问题是出在OS本身还是后端存储系统上。不过11.2.0.4以后的Oracle 才会在GI里自带OSWBB,11.2.03里并没有自动安装,因此如果需要进一步分析IO的问题,需要安装一个OSW。
在国产数据库中,可能也没有更多的数据可以供分析。这种情况下我们也不是束手无策的,可以通过TOP SQL来继续分析。
因为从上面发现的问题CPU使用率较高、IO延时异常,所以在分析TOP SQL的时候我们重点要看CPU开销较高的、物理读、逻辑读较高的SQL。同时执行时间较长的SQL也是值得我们去分析的。
如果能对某些关键SQL做趋势分析或者比对分析,那么是很容易找到问题点的。不过AWR报告不具备这个能力。不过我们也可以通过执行效率存在差别的SQL的awrsqrpt报告来分析其中的差别。
比如我们看这个例子中的执行时间最长的这条SQL。平均执行时间2.98秒。一小时内执行了6566次。
在5-6点的报告中,执行次数198次,平均每次执行1.71秒,慢了1.2秒多。对比CPU消耗来看,在两份报告中分别是1.58秒和1.42秒,从这个数据上看,执行计划大概率没有恶化。
在平均UIO上差得比CPU要高得多,倍率与单块读延时增加的倍率是同样数量级的。因为数据的问题,今天无法更为深入的去解析这个问题。主要疑点是IO延时的问题和LOGON的问题。
不过如果我们面对的是国产数据库,那么也有可能只有这些数据可以供我们分析。我们该如何来分析呢?首先从宏观上分析,这个分析可以通过负载数据、主要缓冲池命中率、TOP 等待事件等方面来分析。就本案例而言,从总体上看,没有特别明显的问题,因此和相类似负载时段正常的指标数据进行比对就十分关键了。
比如对比IO延时指标时,如果能把负载类似时段的数据叠加在一起分析,那么就会有很好的参考。本案例中的对比分析数据并不太有代表性,不过也能从中发现了IO方面的延时变坏的问题。
如果从宏观层面能够发现的问题不多,那么就需要通过微观层面去分析了。AWR报告特别适合宏观层面的分析,如果问题很严重,成为系统的主要问题,那么很容易从AWR中发现问题。而如果AWR中看似较为正常,那么Oracle就提供了ASH工具,用于做微观分析。目前也有部分国产数据库,比如openGauss/Polardb等提供了类似ASH的工具,那么我们也可以通过ASH进行分析,发现潜在问题。
如果没有ASH可以用于分析,那么TOP SQL分析可能就变成了唯一有效的工具了。因此我们需要对自己生产系统采集TOP SQL指标,并对SQL在某个时间段内的执行情况进行分析。比如针对同一条SQL语句,在逻辑读、物理读、执行数量、执行延时等维度进行时段对比分析,一般来说就能够看出其中可能存在的问题了。
声明:本站部分内容来自互联网,如有版权侵犯或其他问题请与我们联系,我们将立即删除或处理。
▍相关推荐
更多数据库相关>>>