RDMA在典型场景下的技术应用分析与探索
当前OPPO的数据中心中已经有一定数量支持RDMA的网卡(包含IB及ROCEv2),除了机器学习场景以外,之前的文章ORPC[1]
也已经分享了OPPO在RPC over RDMA传输的实践,具体RDMA相关前置知识也可以参考此篇文章。为了充分发挥RDMA低延迟、远程内存访问、bypass cpu/os、及高带宽的优势,我们选取了一些业务程序进行传输方案的改造和测试,并总结探讨一般业务程序改造为RDMA传输的经验。
01
业务适配RDMA类型
RDMA传输的适配,从业务场景的使用角度来看,大致可分为如下几种类型。
场景一:机器学习、分布式存储等场景,使用社区成熟的方案,如在机器学习场景中使用的NCCL、Tensorflow等框架中都适配了多种传输方式(包含tcp、rdma等),块存储Ceph中也同时支持tcp及rdma两种通信模式,这种业务场景下业务侧更多关注的是配置及使用,在IAAS基础设施侧将RDMA环境准备好后,使能框架使用rdma的传输模式即可。
场景二:业务程序使用类似于RPC远程调用的通信方式,业务侧需要将原有使用的RPC(大部分是GRPC)调用改为ORPC调用,在这种场景下业务和传输更像是两个独立的模块,通过SDK的方式进行调用,所以适配起来改造的代码并不多,通常是业务层面修改调用RPC的接口方式。但由于业务方可能使用多种编程语言,RPC over RDMA需要进行编程语言进行适配。
场景三:业务程序通信是私有化通信,比如使用socket套接字结合epoll完全自有实现的一套通信机制。这种场景下其实改造也区分情况,即业务IO与网络IO是否耦合,若比较解耦,代码中抽象出一层类似于最新redis代码中ConnectionType这样的架构[2],那么只需要实现一套基于RDMA通信且符合Redis ConnectionType接口定义的新传输类型即可,改造量相对可控并且架构上也比较稳定;而若业务IO与网络IO结合的较为紧密的情况下,这种场景下往往改造起来会比较复杂,改造的时候需要抽丝剥茧的找出业务与网络之间的边界,再进行网络部分的改造。
02
Redis RDMA改造方案分析
首先,以Redis改造为RDMA传输为例,分析基于RDMA传输的应用程序改造逻辑与流程。
第一步是需要梳理出来Redis中与网络传输相关的逻辑,这部分有比较多的参考资料,这里简单总结一下。
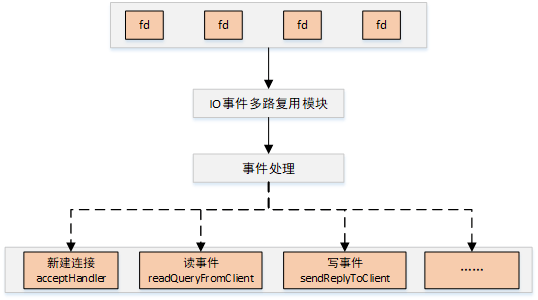
Redis中实现了一套Reactor模式的事件处理逻辑名为AE,其主要流程为:
1、使用epoll等机制监听各文件句柄,包括新建连接、以及已建立的连接等;
2、根据事件的不同调用对应的事件回调处理;
3、循环进行epoll loop并进行处理。
参考[2]中分析了当前redis的连接管理是围绕connection这个对象进行管理(可类比socket套接字的管理),抽象一层高于socket的connection layer,以便兼容不同的传输层,各个字段解释如下。
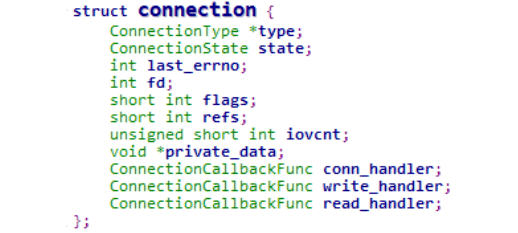
type:各种连接类型的回调接口,定义了诸如事件回调、listen、accept、read、write等接口,类比tcp socket实现的proto_ops。
state:当前连接的状态,如CONNECTING/ACCEPTING/CONNECTED/CLOSED等状态,类比TCP的状态管理。
fd:连接对应的文件句柄。
iovcnt:进行iov操作的最大值。
private_data:保存私有数据,当前存放的是redis中client的指针。
conn_handler/write_handler/read_handler:分别对应连接connect、write、read时的处理接口。
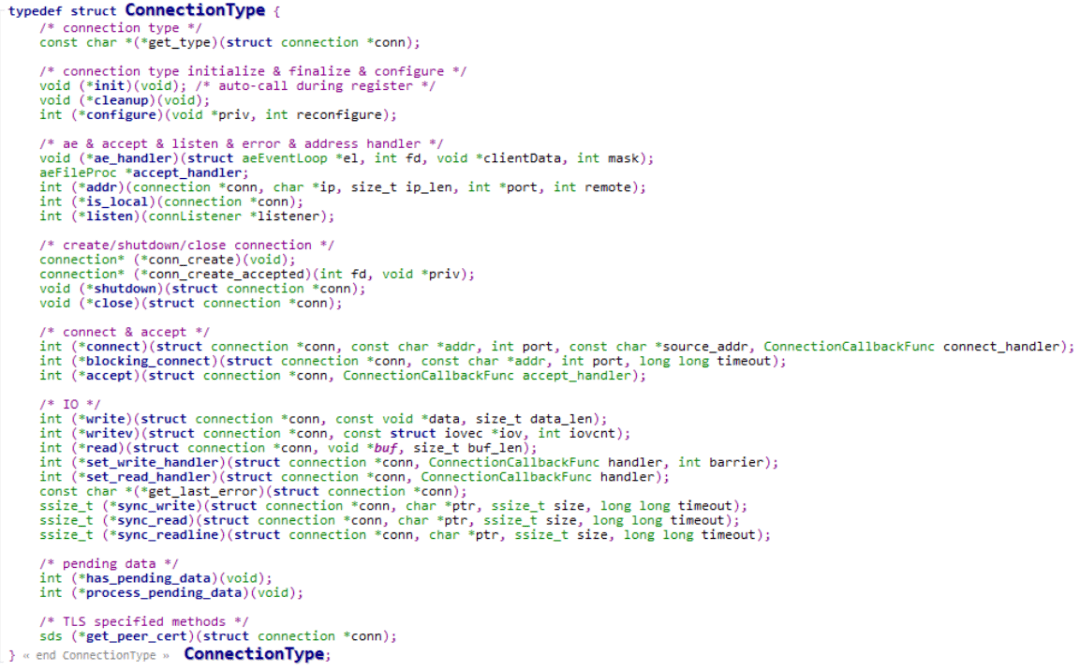
get_type: connection的连接类型,当前redis已支持tcp、unix、tls类型,返回字符串。
init:在每种网络连接模块注册时调用,各模块私有初始化,如tcp、unix类型当前未实现,tls注册时做了一些ssl初始化的前置工作。
ae_handler: redis中的网络事件处理回调函数,redis中使用aeCreateFileEvent为某个fd及事件注册处理函数为ae_handler,当redis的主循环aeMAIn中发现有响应的事件时会调用ae_handler进行处理,如在tcp连接类型中ae_handler为connSocketEventHandler,该函数分别处理了链接建立、链接可读、链接可写三种事件。
listen: 监听于某个IP地址和端口,在tcp连接类型中对应的函数为connSocketListen,该函数主要调用bind、listen。
accept_handler: redis作为一个服务端,当接收到客户端新建连接的请求时候的处理函数,一般会被.accept函数调用,比如在tcp连接类型中,connSocketAccept调用accept_handler,该方法被注册为connSocketAcceptHandler,主要是使用accept函数接收客户端请求,并调用acceptCommonHandler创建client。
addr: 返回连接的地址信息,主要用于一些连接信息的debug日志。
is_local:返回连接是否为本地连接,redis在protected模式下时,调用该接口判断是否为本地连接进行校验。
conn_create/conn_create_accepted:创建connection,对于tcp连接类型,主要是申请connection的内存,以及connection初始化工作。
shutdown/close:释放connection的资源,关闭连接,当某个redis客户端移除时调用。
connect/blocking_connect:实现connection的非阻塞和阻塞连接方法,在tcp连接类型中,非阻塞连接调用aeCreateFileEvent注册连接的可写事件,继而由后续的ae_handler进行处理,实现非阻塞的连接;而阻塞连接则在实现时会等待连接建立完成。
accept:该方法在redis源码中有明确的定义,可直接调用上述accept_handler,tcp连接类型中,该方法被注册为connScoketAccept。
write/writev/read:和linux下系统调用write、writev、read行为一致,将数据发送至connection中,或者从connection中读取数据至相应缓冲区。
set_write_handler:注册一个写处理函数,tcp连接类型中,该方法会注册connection可写事件,回调函数为tcp的ae_handler。
set_read_handler:注册一个读处理函数,tcp连接类型中,该方法会注册connection可读事件,回调函数为tcp的ae_handler。
sync_write/sync_read/sync_readline:同步读写接口,在tcp连接类型中实现逻辑是使用循环读写。
has_pending_data:检查connection中是否有尚未处理的数据,tcp连接类型中该方法未实现,tls连接类型中该方法被注册为tlsHasPendingData,tls在处理connection读事件时,会调用SSL_read读取数据,但无法保证数据已经读取完成[3],所以在tlsHasPendingData函数中使用SSL_pending检查缓冲区是否有未处理数据,若有的话则交由下面的process_pending_data进行处理。has_pending_data方法主要在事件主循环beforesleep中调用,当有pending data时,事件主循环时不进行wait,以便快速进行下一次的循环处理。
process_pending_data:处理检查connection中是否有尚未处理的数据,tcp连接类型中该方法未实现,tls连接类型中该方法被注册为tlsProcessPendingData,主要是对ssl缓冲区里面的数据进行读取。process_pending_data方法主要在事件主循环beforesleep中调用。
get_peer_cert:TLS连接特殊方法。
结合当前代码中tcp及tls实现方法,梳理出和redis connection网络传输相关的流程:
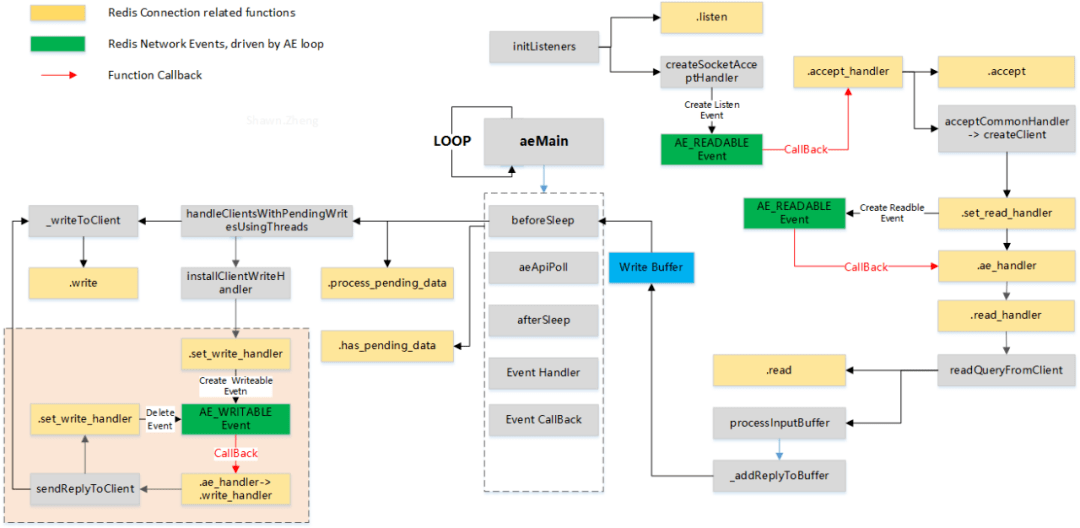
图:Redis Connection Call Graph
对于redis来说新增一个RDMA方式的传输方式,即是要将connection中的各种方法按照上述定义去使用RDMA编程接口去实现。RDMA编程一般采用CM管理连接加Verbs数据收发的模式,客户端与服务端的交互逻辑大致如下图所示,参考[16]。
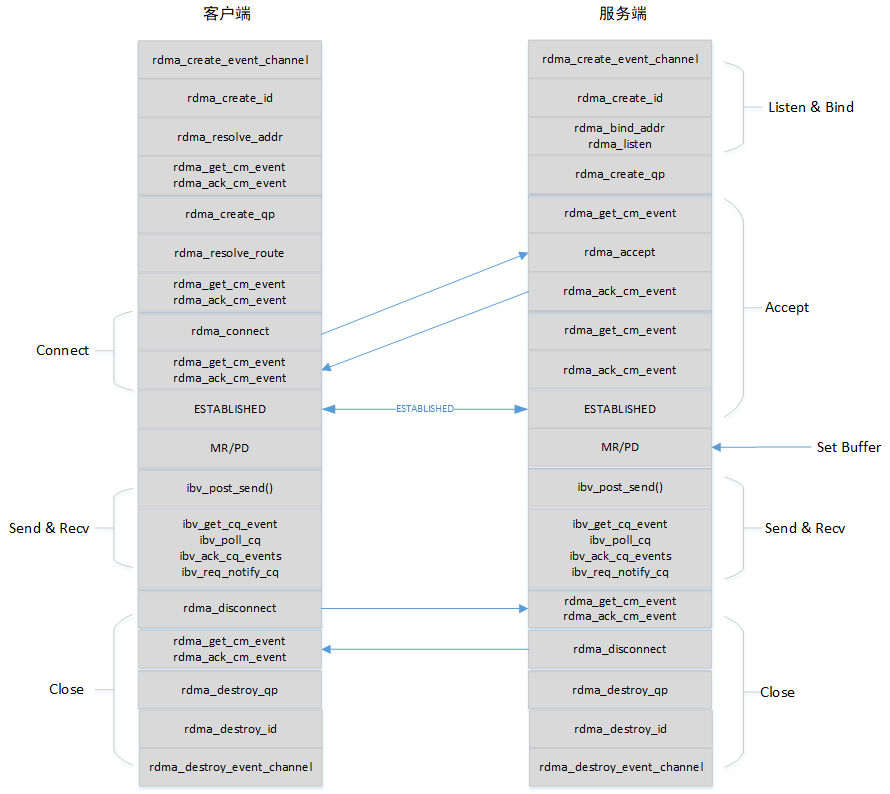
图:RDMA C/S Workflow
字节跳动的pizhenwei同学目前在redis社区中已经提交了redis over rdma的PR,参见[4],具体的代码均在rdma.c这一个文件中。由于RDMA在做远程内存访问时,需要使用对端的内存地址,所以作者实现了一套RDMA客户端与服务端的交互机制,用于通告对端进行远程内存写入的内存地址,参见[5]。

交互逻辑及说明如下:
1、增加了RedisRdmacmd,用于Redis客户端与服务端的控制面交互,如特性交换、Keepalive、内存地址交换等;
2、在客户端及服务端建立完成RDMA连接后,需要先进行控制面的交互,当内存地址交换完成后,方可以进行Redis实际数据的交互及处理;
3、控制面消息通过IBV_WR_SEND方式发送,Redis数据交互通过IBV_WR_RDMA_WRITE_WITH_IMM发送,通过方法的不同来区分是控制面消息还是Redis的实际数据;
4、客户端及服务端共享了一片内存,则需要对内存的使用管理,目前有三个变量用户协同读写双方的内存使用。
- tx.offset为RDMA发送侧已经对内存写入的偏移地址,从发送端角度看内存已经使用到了tx.offset位置,下次发送端再进行RDMA写入时,内存地址只能为tx.offset + 1;
- rx.offset为RDMA接收侧已经收到的内存偏移地址,虽然数据可能实际上已经到了tx.offset的位置,但由于接收侧需要去处理CQ的事件,才能获取到当前数据的位置,rx.offset是通过IMM中的立即数进行传递的,发送侧每次写入数据时,会将数据长度,所以rx.offset <= tx.offset;
- rx.pos 为接收方上层业务内存的偏移地址,rx.pos <= rx.offset。
5、当rx.pos等于memory.len时,说明接收侧内存已满,通过内存地址交换这个RedisRdmaCmd进行控制面交互,将tx.offset、rx.offset、rx.pos同时置零,重新对这片共享内存协同读写。
Connection各方法的主要实现逻辑及分析如下:
listen:主要涉及RDMA编程图示中listen、bind的流程,结合redis的.init相关调用流程,会将cm_channel中的fd返回给网络框架AE,当后续客户端连接该fd时,由AE进行事件回调,即后续的accepHandler。
accept_handler:该函数作为上述listen fd的事件回调函数,会处理客户端的连接事件,主要调用.accept方法进行接收请求,并使用acceptCommonHandler调用后续的.set_read_handler注册已连接的读事件,参见图Redis Connection Call Graph。
accept:要涉及RDMA编程图示中accept的流程,处理RDMA_CM_EVENT_CONNECT_REQUEST、RDMA_CM_EVENT_ESTABLISHED等cm event,并进行cm event的ack。
set_read_handler:设置连接可读事件的回调为.ae_handler。
read_handler:实际处理中会被设置为readQueryFromClient。
read:从本地缓冲区中读取数据,该数据是客户端通过远程DMA能力写入。
set_write_handler:将write_handler设置为回调处理函数,这里和tcp、tls实现的方式有所区别,并没有注册connection的可写事件回调,是因为RDMA中不会触发POLLOUT(可写)事件,connection的写由ae_handler实现。
write_handler:实际工作中被设置为sendReplyToClient。
write:将Redis的数据拷贝到RMDA的本地缓冲区中,通过ibv_post_send,这部分数据会通过远程DMA能力写入对端。
has_pending_data:检查内部的pending_list,在收到RDMA_CM_EVENT_DISCONNECTED等事件时,会将当前connection加入到pending_list中,由后续beforeSleep时调用process_pending_data进行处理。
process_pending_data:检查pending的connection,并调用read_handler读取connection中的数据。
ae_handler:该方法有三个处理流程,第一是处理RDMA CQ事件,包括接收处理RedisRdmaCmd控制面消息,接收RDMA IMM类事件增加rx.offset;第二是调用read_handler和write_handler,这部分是与tcp、tls流程一致;第三是检查rx.pos和rx.offset的值,若rx.pos == memory.len时,发送内存地址交换这个RedisRdmaCmd控制面消息。
03
Redis RDMA测试
Redis测试通常采取自带的redis-benchmark工具进行测试,该工具复用了redis中的ae处理逻辑,并调用hiredis进行redis数据的解析,在参考[6]中fork并改造了一份基于RDMA的redis-benchmark,可直接编译使用,接下来使用该工具进行tcp及RDMA方式的性能测试对比。
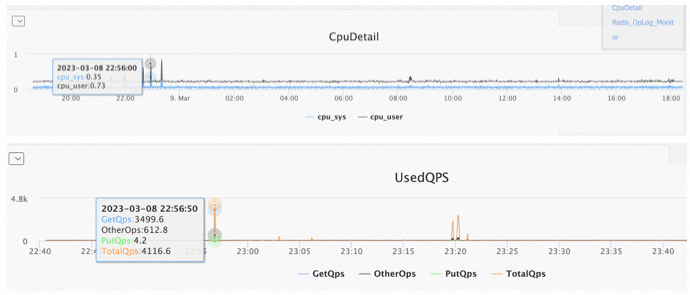
在实际测试中使用的是同一个交换机下的两台服务器,传输方式是rocev2,经过qperf的测试,tcp的latency为12us,rocev2的latency为4us。
▎3.1 单并发单线程
TCP方式
RedisServer:./src/redis-server --protected-mode no
RedisBenchmark:./src/redis-benchmark -h xx.xx.xx.xx -p 6379 -c 1 -n 500000 -t get
RDMA方式
RedisServer:./src/redis-server --loadmodule src/redis-rdma.so port=6379 bind=xx.xx.xx.xx --protected-mode no
RedisBenchmark:./src/redis-benchmark -h xx.xx.xx.xx -p 6379 -c 1 -n 500000 -t get --rdma
▎3.2 多并发多线程
Redisbenchmark单线程4连接:
Redisbenchmark单线程8连接:
Redisbenchmark单线程16/32连接:
注:在我们的测试环境中16个连接时,redis-benchmark已经100%,再进行增加连接数测试时,qps也不会再增加。
Redisbenchmark 4线程4连接:
Redisbenchmark 4线程16连接:
Redisbenchmark 4线程32/64连接:
注:在我们的测试环境中4线程32连接时,redis-server已经100%,再进行增加连接数测试时,qps也不会再增加。
更多的连接和线程:
▎3.3 测试总结
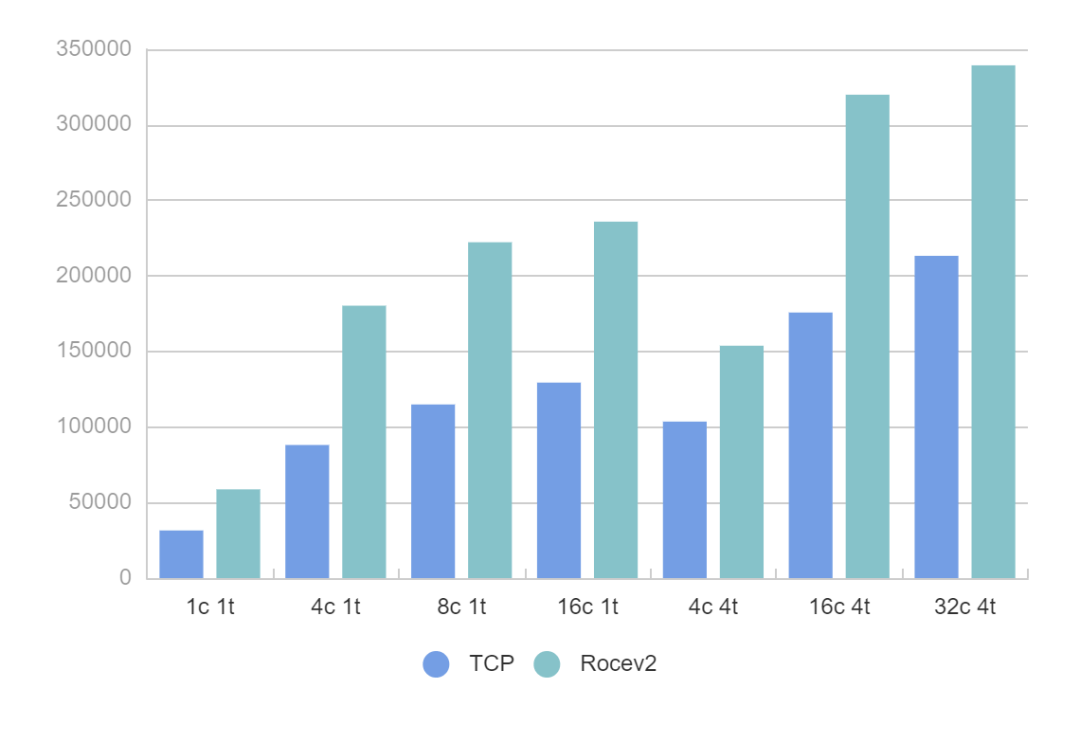
- 整体而言,在我们的测试环境下,redis服务能力rocev2(rdma)的传输方式相较tcp,有~50% 到 ~100%左右的能力提升。
- 可以发现,由于rdma bypass了内核协议栈,相同物理拓扑下redis一次读取时延下降了16us左右(见3.1单并发测试数据),这里额外做了一个测试,选取了另外一组相隔较远的机器进行测试,发现读取时延仍然缩小的是这个数量级,见下图。
- rdma方式建链的时间较长,实际测试中连接数越多,redis-benchmark真正开始测试的时间越长。
04
开源程序基于RDMA方案
▎4.1 Tensorflow RDMA
Tensorflow是一个广泛使用的深度学习框架,在Tensorflow中数据通常表示为Tensor张量,Tensor是一个多为数据,可以在不同的设备之间进行传输,以便进行分布式计算。
在分布式系统中,Tensorflow可以通过网络传输将Tensor从一个节点传输到另一个节点,从1.1版本开始支持RDMA传输,以下为其基于RDMA传输的主要方案,参考[7][8]。
- 在RDMA传输通道建立之前,使用基于tcp的grpc通道传输传递RDMA的内存地址、MR key、服务地址等信息
- 内存拷贝方案:
a)对于可以DMA的Tensor(包括CPU上的内存或者GPU Direct的内存),采用直接从源Tensor写到目标Tensor中的方案,实现内存零拷贝
b)对于非DMA得Tensor,用protobuf序列化后,通过RDMA方式写到接收端预先注册的内存中
c)对于不支持GPU Direct的Tensor,通过RDMA方式写到接收端的CPU内存,再在接收端通过拷贝的方式到GPU中,发送与接收CPU之间不存在内存拷贝
- 内部使用RdmaBuffer用于RDMA读写的内存单元,RdmaBuffer有三个派生类,分别是RdmaAckBuffer、RdmaMessageBuffer和RdmaTensorBuffer,RdmaMessageBuffer负责发送 message ,比如请求一个tensor等等。一旦一个message被发送,message的接收方需要通过RdmaAckBuffer发送一个ack来释放发送方的message buffer。一个RdmaAckBuffer和唯一的RdmaMessageBuffer绑定。RdmaTensorBuffer负责发送tensor,tensor的接收方需要返回一个message来释放发送方的buffer
- 对于一个具体的recv和send流程如下:
a)接收侧发送RDMA_MESSAGE_TENSOR_REQUEST消息,其中包含目的Tensor的地址,以用于发送侧进行RDMA写入。
b)为避免在每个步骤中发送额外的元数据消息,为每个Tensor维护一个本地元数据缓存,仅在更改时才会更新,每个RDMA_MESSAGE_TENSOR_REQUEST将包含接收方从本地缓存中获取的元数据。发送方将比较消息中的元数据和Tensor的新元数据,如果元数据更改,发送侧发送包含新元数据的RDMA_MESSAGE_META_DATA_RESPONSE。
c)当接收方收到 RDMA_MESSAGE_META_DATA_RESPONSE 时,将更新本地元数据缓存,重新分配结果/代理Tensor,重新发送Tensor请求。为了可追溯性,新的消息具有不同的名称RDMA_MESSAGE_TENSOR_RE_REQUEST。
d)当发送方收到 RDMA_MESSAGE_TENSOR_RE_REQUEST 时,它将使用消息中指定的请求索引定位相关的 RdmaTensorResponse,并调用其 Resume方法,该方法将 RDMA 写入之前克隆的Tensor的内容,到重新请求中指定的新远程地址。
e)当接收方接收到 RDMA 写入时,它将使用立即值作为请求索引,找到相关的 RdmaTensorRequest,然后调用其 RecvTensorContent方法,包含可能存在的内存复制、反序列化等工作。
▎4.2 Brpc RDMA
百度的brpc当前的RDMA传输实现中,数据传输是使用RMDA_SEND_WITH_IMM进行操作,这就要求接收端在接收数据前要先准备好内存并预先POST RECV。为了实现高效的内存管理,brpc内部实现了静态内存池,且在RDMA数据传输实现中做了如下几点优化,参考[9][10]。
- 数据传输零拷贝,要发送的所有数据默认都存放在IOBuf的Block中,因此所发送的Block需要等到对端确认接收完成后才可以释放,这些Block的引用被存放于RdmaEndpoint::_sbuf中。而要实现接收零拷贝,则需要确保接受端所预提交的接收缓冲区必须直接在IOBuf的Block里面,被存放于RdmaEndpoint::_rbuf。注意,接收端预提交的每一段Block,有一个固定的大小(recv_block_size)。发送端发送时,一个请求最多只能有这么大,否则接收端则无法成功接收。
- 数据传输有滑动窗口流控,这一流控机制是为了避免发送端持续在发送,其速度超过了接收端处理的速度。TCP传输中也有类似的逻辑,但是是由内核协议栈来实现的,brpc内实现了这一流控机制,通过接收端显式回复ACK来确认接收端处理完毕。为了减少ACK本身的开销,让ACK以立即数形式返回,可以被附在数据消息里。
- 数据传输逻辑的第三个重要特性是事件聚合。每个消息的大小被限定在一个recv_block_size,默认为8KB。如果每个消息都触发事件进行处理,会导致性能退化严重,甚至不如TCP传输(TCP拥有GSO、GRO等诸多优化)。因此,brpc综合考虑数据大小、窗口与ACK的情况,对每个发送消息选择性设置solicited标志,来控制是否在发送端触发事件通知。
▎4.3 NCCL RDMA
NCCL的网络传输实现是插件式的,各种不同的网络传输只需要按照ncc.NET中定义的方法去具体实现即可。
其中最主要的是isend、irecv及test方法,在调用 isend 或 irecv 之前,NCCL 将在所有缓冲区上调用 regMr 函数,以便 RDMA NIC 准备缓冲区,deregMr 将用于注销缓冲区。
以下是NCCL RDMA的实现部分逻辑,基于当前NCCL最新版本https://Github.com/NVIDIA/nccl/tree/v2.18.3-1分析,主要参考[11]及参考[12]
(当前实现与参考中略有不同)。
- 在NCCL基于RDMA的传输实现中,目前的数据传输主要是通过RDMA_WRITE操作
- 由于发送端进行RDMA_WRITE时,需要预先知道对端的DMA地址,NCCL中发送/接收端是通过一个缓冲区ncclIbSendFifo进行交互
- ncclIbSendFifo是发送端申请的一块内存缓冲区,在connect与accept阶段通过传统tcp socket的方式携带给接收端
- 在接收端异步进行接收时,recvProxyProgress调用irecv接口进行接收,在RDMA的实现中对应的是将本端DMA的地址通过ncclIbSendFifo RDMA_WRITE至发送端
- 发送端进行发送时,sendProxyProgress调用isend接口进行发送,在RDMA中对应的是从ncclIbSendFifo中获取接收端的DMA地址,将上层的data直接RDMA_WRITE至接收端的DMA地址中
- 接收端维护本地的remFifoTail游标,每次接收时游标后移一位,接收端会将idx设置为一个自增的索引,同时将上层的DMA地址通过ncclIbSendFifo携带给发送端
- 发送端维护本地的fifoHead游标,每次发送后游标后移一位,发送端检查fifo中元素的idx值是否为预期索引来判断该fifo是否已经被接收端设置过,即接收端的DMA地址已经可以写入
// 发送端ncclIbIsend:uint64_tidx = comm->fifoHead+1;if(slots[0].idx != idx) { *request = NULL; returnncclSuccess; }comm->fifoHead++;
//接收端ncclIbIrecv -> ncclIbPostFifo :localElem[i].idx = comm->remFifo.fifoTail+1;comm->remFifo.fifoTail++;
▎4.4 Libvma及SMC-R方式
除了上述修改业务源码的方案,业内也有“零入侵”业务程序的方案,比如libvma及smc-r方式。
SMC-R:
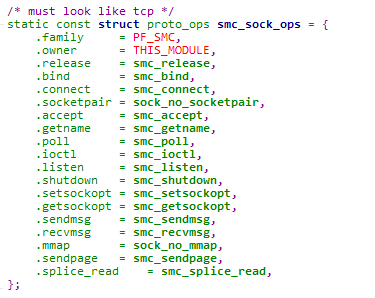
smc-r(SMC over RDMA)是IBM在2017提交至linux kernel的一种兼容socket层,使用共享内存技术、基于RDMA技术实现的高性能内核网络协议栈。smc-r的主要实现是在内核态实现了一个新的af_smc协议族,基于RDMA verbs接口实现内核proto_ops中的各方法。
smc-r支持fallback回退机制,在通信双方最开始建立连接时是使用tcp握手(特定的tcp选项)进行协商是否双方均支持SMC-R能力,当协商不成功时fallback为原始的tcp通信。完成协议协商并建立连接后,协议栈为SMC-R socket分配一块用于缓存待发送数据的环形缓冲区sndbuf和一块用于缓存待接收数据的环形缓冲区RMB(Remote Memory Buffer)。
- 发送端应用程序通过socket接口将待发送数据拷贝到本侧sndbuf中,由SMC-R协议栈通过RDMA WRITE操作直接高效地写入对侧节点的RMB中。同时伴随着使用RDMA SEND/RECV操作交互连接数据管理消息,用于更新、同步环形缓冲区中的数据游标。
- 接收端SMC-R协议栈感知到RMB中填入新数据后,通过epoll等方式告知接收端应用程序将RMB中的数据拷贝到用户态,完成数据传输。所以在SMC-R中,RMB充当传输过程中的共享内存。
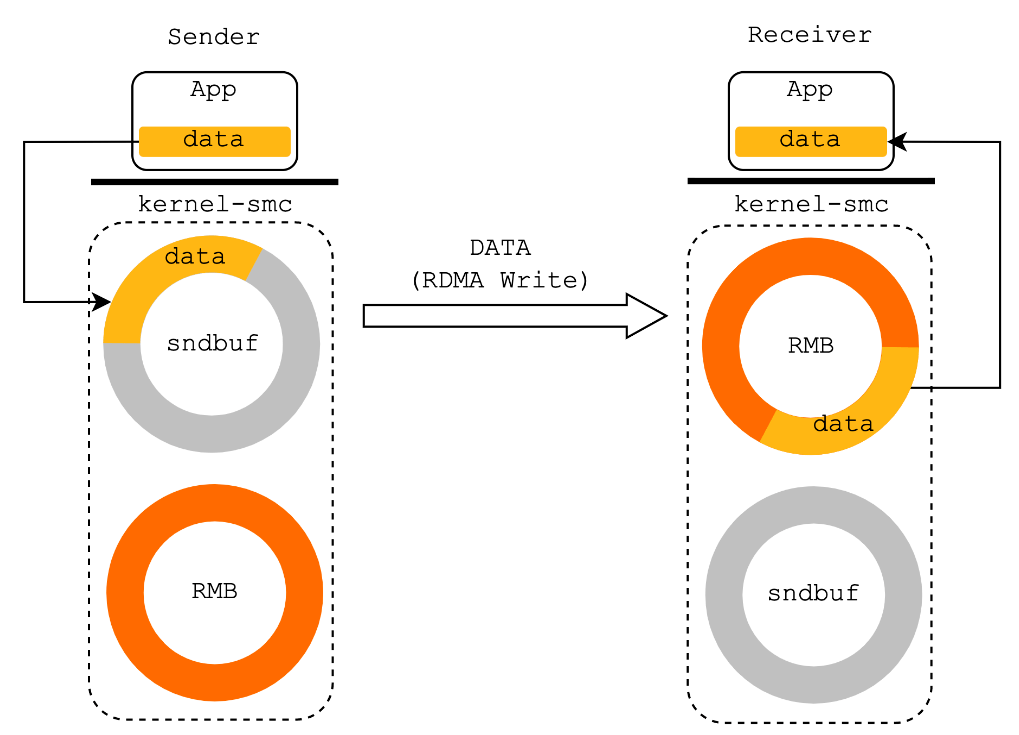
图 smc-r发送接收(转自阿里云)
下面是一个基于smc-r通信的实际测试场景的协商交互抓包:
Libvma:
Libvma是Mellanox公司开源的一款高性能的用户态网络协议栈,它将socket的相关接口全部在用户态空间实现,实现对内核的旁路,使用RDMA verbs接口直接调用网卡驱动,从而节省了大量的上下文数据拷贝,节省了 CPU 的资源降低了时延,业务在使用libvma时只需要使用LD_PRELOAD libvma.so替换原有的系统调用即可完成传输协议的替换。
Libvma内部在tcp协议栈的实现上使用了lwip方案,重写了epoll,使用了hugepage,内部使用单独的线程去轮询RDMA CQ事件等方案,相较于内核协议栈的实现,在主机侧的处理延迟有200%至500%的降低。
此外,在实际测试过程中发现libvma虽然使用的是RDMA verbs接口,但实际针对Mellanox mlx5系列驱动的网卡是直接用户态驱动网卡,发送的仍然是原始基于tcp的以太报文,并不是rocev2的报文,具体讨论可以见github上的issue参考[15]。
下面是基于libvma测试redis的场景,由于libvma bypass协议栈,并且重写了epoll等其它特性,性能提升大概3倍:
总结:
相较于业务使用raw verbs进行源码修改,libvma及smc-r方式可以提供“零入侵、零修改”源码的优势,但由于应用程序在将数据提供给socket接口时仍然存在一次拷贝,所以性能上对比verbs方案来说有一定的损耗,对于想快速验证RDMA能力的业务是一个不错的POC验证方式。
目前阿里云的Alibaba Cloud Linux3默认支持smc-r能力,结合阿里云的eRDMA能力网卡,可以使业务进行透明无损的RDMA传输替换,减少cpu的使用率,降低一定的通信延时。但目前该能力在阿里云上属于公测能力,生产稳定性待验证,参考[14]。
libvma方式没有linux社区的支持,并且更多的是针对Mellanox系列网卡的支持,在工业界使用的场景也不太多,目前在金融的高频交易领域有一些使用尝试。
05
总结与展望
前面主要分析和调研了一些开源应用在进行业务适配RDMA传输的方案,整体来看RDMA改造的方案是分为两部分,分别为通信接口的改造以及RDMA内存管理设计。
通信接口改造主要指将tcp socket的传输接口修改为ib verbs或者cm接口,这部分同时涉及到适配现有业务网络事件的处理模型。
由于RDMA传输数据时,需要预先将内存注册到HCA卡上,所以RDMA内存管理会比较复杂,同时也是性能高低与否的关键。
1)数据传输时申请内存,并进行内存注册,再进行RDMA操作。显然这种模式在代码实现上最为简单,但是性能及效率最低,现有方案中很少有在fast path中使用这种内存管理方案。
2)提前注册好一大块内存,在上层业务需要发送数据时,将数据拷贝至RDMA注册好的内存。这种模式性能相较第一种有提升,但存在一定的内存拷贝。
3)使用内存池,业务及RDMA的内存使用同一块。性能明显是最优的,但是实现逻辑较复杂,需要管理好内存的申请及释放、某些实现中通信双方也需要做内存使用量的协商。
结合前面应用的RDMA方案,汇总如下表:
| 应用名称 | 网络处理模型 | 内存方案 | 其他特性 |
|
Redis (pr stage) |
1.适配原有的单线程reactor非阻塞模式 2.rdma无pollout时间,在业务逻辑中额外处理 3.网络支持插件式,不同的传输模式实现相同的网络方法 |
1.预注册内存,RDMA Write模式 2.DMA地址通过控制消息交互 3.应用与RDMA之间存在拷贝 |
1.有控制面交互,如xferbuffer 2.控制面信息复用RDMA通道 |
|
Tensorflow |
异步发送、阻塞接收 |
1.RDMA Write模式 2.应用及RDMA共享内存池 3.通信双方通过消息交互DMA地址 |
1.使用基于TCP的GRPC通道进行RDMA链接的协商 2.有控制面消息交互,如metadata更新 3.控制面信息复用RDMA通道 |
|
BRPC |
reactor模式 |
1.内存池模式 2.使用RDMA Send模式 |
1.额外的流控机制 2.事件聚合 |
|
NCCL |
1.reactor模式 2.网络支持插件式,不同的传输模式实现相同的网络方法 |
1.RDMA Write模式 2.通信双方通过一个共享fifo来交互具体的DMA地址 3.DMA地址是预先注册的内存 |
1.RDMA建立阶段使用TCP链接进行协商 |
随着AI的火热,国产DPU、GPU的高速发展,数据中心内在高性能计算、机器学习、分布式存储等场景下的业务也需要随着硬件能力的提升去适配使用这些能力,RDMA因其诸多优点目前已经广泛被应用。调研学习现有的方案是为了更好地适配及修改自研的业务,相信随着越来越多业务场景下RDMA的使用,其相关生态及应用方案也会越来越成熟。
▎以上内容基于网上资料及源码分析整理,欢迎讨论及批评指正。
参考
[1]orpc
https://mp.weixin.qq.com/s/7UC_1SmcKcyRA2xA5q-AEQ
[2]redis网络连接层
https://cloud.tencent.com/developer/article/2185514
[3]openssl pending:
https://blog.csdn.net/weixin_33816300/article/details/89869149
[4]redis over rdma :
https://github.com/pizhenwei/redis/tree/feature-rdma
[5]redis over rdma protocol:
https://github.com/pizhenwei/redis/blob/feature-rdma/RDMA.md
[6]redis over rdma test:
https://github.com/forsakening/rdma-redis-test
[7]tensorflow over rdma:
https://github.com/tensorflow/networking/blob/master/tensorflow_networking/verbs/README.md
[8]tensorflow rdma源码剖析:
https://github.com/chenpai/TensorFlow-RDMA/blob/master/TensorFlow%20RDMA%20%E6%BA%90%E7%A0%81%E5%89%96%E6%9E%90.md
[9]brpc的rdma特性
https://github.com/Apache/brpc/blob/master/docs/cn/rdma.md
[10]brpc的rdma实现
https://blog.csdn.net/KIDGIN7439/article/details/124408432
[11]nccl多机通信流程
https://blog.csdn.net/KIDGIN7439/article/details/130936177
[12]nccl net plugin
https://github.com/NVIDIA/nccl/blob/master/ext-net/README.md
[13]libvma
https://github.com/Mellanox/libvma
[14]阿里云smc-r
https://help.aliyun.com/document_detail/327118.htm
[15]libvma packet type issue
https://github.com/Mellanox/libvma/issues/1036
[16]RDMA CM交互流程
https://www.ibm.com/docs/zh-tw/aix/7.1?topic=cm-client-operation
作者介绍
Xiang Zheng
OPPO高级后端工程师
负责OPPO云虚拟化网络的架构设计与实现,关注数据中心网络的各种问题、技术演进与创新实践。