Apache Spark 的新编程语言
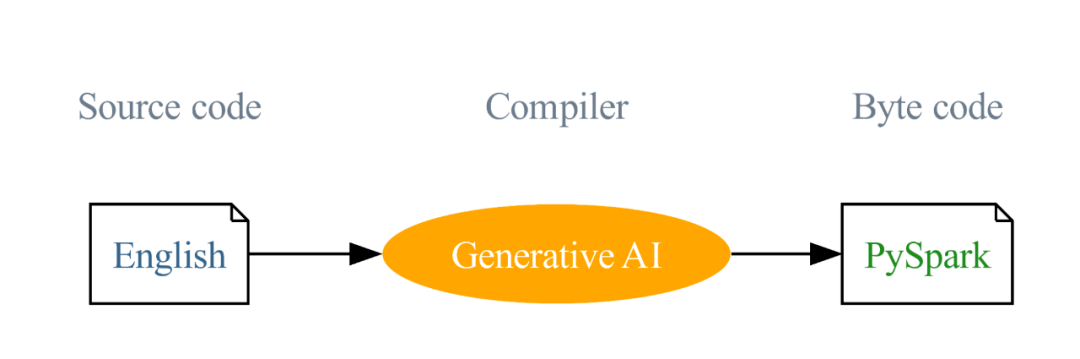
English SDK for Spark : 将英语作为一种新的编程语言,将生成式 AI 当做编译器, 将 Python/ target=_blank class=infotextkey>Python 视作字节码!
本文主要介绍了 Apache Spark 的英语软件开发套件(SDK)的重要性和目标,以及它采用生成式 AI 技术来丰富Spark 的使用体验。它还提到了Github Copilot 对 AI 辅助代码开发的影响,以及其存在的限制和问题。本文还绍了英语 SDK 的特性,包括数据获取、DataFrame 操作、自定义函数(UDFs)和缓存等。最后,鼓励读者积极参与英语 SDK 的开发和探索,为扩大 Apache Spark 的影响力贡献一份力量。
原文链接:https://www.databricks.com/blog/introducing-english-new-programming-language-apache-spark
作者 | Gengliang Wang,Xiangrui Meng,Reynold Xin,Allison Wang,Amanda Liu和Denny Lee
译者 | 明明如月
责编 | 夏萌
出品 | CSDN(ID:CSDNnews)
导言
我们非常激动地向大家介绍 Apache Spark 的英语软件开发套件(SDK)。这是一个革命性的工具,旨在丰富你的 Spark 使用体验。Apache Spark™ 在全球范围内,覆盖 208 个国家和地区,年下载量超过 10 亿次,已经在大规模数据分析领域取得了显著成绩。我们的英语 SDK 采用先进的生成型 AI 技术,旨在扩大这个活跃的社区,使 Spark 在易用性和亲和度上达到前所未有的高度!
缘起
GitHub Copilot 对 AI 辅助的代码开发领域产生了深远的影响。虽然它功能强大,但用户需要理解生成的代码后才能提交。同时,审查者也需要理解代码才能进行审查。这可能会限制其广泛应用的一大阻碍。当处理 Spark 表和 DataFrames 时,它偶尔也会生成不正确或不符合预期的代码。下面的 GIF 动图展示了这一点,Copilot 提出了一个窗口规范,并引用了不存在的dept_id列,这需要一些专业知识才能理解。

与其将 AI 视为副驾驶,为何不让 AI 当做司机,我们坐在豪华的后座享受呢?这就是我们英语 SDK 所要扮演的角色。我们发现,尖端的大型语言模型对 Spark 非常了解,这得益于优秀的 Spark 社区,他们在过去十年中,贡献了大量的开放的、高质量的内容,比如 API 文档、开源项目、问题和答案、教程和书籍等。现在,我们将这些生成型 AI 对 Spark 的专业知识融入到英文 SDK 中。你不再需要理解复杂的生成代码,只需用简单的英文指令即可得到结果:
transformed_df = df.ai.transform('get 4 week moving average sales by dept')英语 SDK 通过理解 Spark 表和 DataFrames 来处理复杂性,并直接返回一个正确的 DataFrame !
我们的愿景是:将英文作为一种编程语言,并使用生成式 AI 将这些英文指令编译成 PySpark 和 SQL 代码。这种创新的方式旨在降低编程的门槛和简化学习曲线。这个愿景是推动英文 SDK 的主要驱动力,我们的目标是扩大 Spark 的影响力,让 Spark 从一个成功走向另一个成功。
英语 SDK 的特性
英语 SDK 通过实现以下关键特性,使 Spark 的开发过程变得更简单:
-
数据获取:根据你的描述,SDK 可以进行网络搜索,运用大型语言模型 (LLM) 确定最佳结果,然后顺利地将选定的网络数据集成到 Spark 中,这些操作都能在一个步骤中完成。
-
DataFrame 操作:SDK 对指定的 DataFrame 提供了功能,根据你的英文描述执行转换、绘图和解释操作。这些功能大大提升了代码的可读性和效率,使得对 DataFrames 的操作更加直接和直观。
-
自定义函数 (UDFs):SDK 提供了简洁的创建 UDFs 的流程。你只需要提供一段描述,AI 就可以负责代码的补全。这一特性简化了 UDF 的创建过程,让你可以专注于函数定义,而 AI 则会处理其余部分。
-
缓存:SDK 吸取了缓存的优点以提升执行速度,保证结果的可复用性,并节省成本。
示例
为了进一步说明如何使用英语 SDK,我们将通过一些例子进行演示:
数据获取
如果你是一名数据科学家,需要导入2022年美国全国汽车销售数据,您只需要两行代码即可完成:
spark_ai = SparkAI auto_df = spark_ai.create_df("2022 USA national auto sales by brand")DataFrame 操作
对于给定的 DataFrame 对象,SDK 允许你运行以 df.ai 开头的方法。这包括转换、绘图、DataFrame 解释等等。
要激活 PySpark DataFrame 的部分函数:
spark_ai.activate要预览 auto_df:
auto_df.ai.plot要查看各汽车公司的市场份额分布:
auto_df.ai.plot("pie chart for US sales market shares, show the top 5 brands and the sum of others")要获取增长最快的品牌:
auto_top_growth_df=auto_df.ai.transform("top brand with the highest growth") auto_top_growth_df.show要获取 DataFrame 的解释:
auto_top_growth_df.ai.explain总的来说,这个 DataFrame 正在查找销售增长最快的品牌。它将结果按销售增长率降序排列,并仅返回增长最快的结果。
自定义函数 (UDFs) SDK
支持通过简单而清晰的方式创建自定义函数。使用@spark_ai.udf装饰器,你只需定义一个带有文档字符串的函数,SDK 就会在后台自动完成代码生成:
@spark_ai.udf def convert_grades(grade_percent: float) -> str: """Convert the grade percent to a letter grade using standard cutoffs""" ...现在,你可以在 SQL 查询或 DataFrames 中使用这个自定义函数(UDF)
SELECT student_id, convert_grades(grade_percent) FROM grade总结
Apache Spark 的英语 SDK 是一个既简洁又强大的工具,能够显著提升你的开发效率。它的目标是简化复杂的任务,减少必需的代码量,使你可以专注于从数据中挖掘洞察。
虽然英语 SDK 还处于早期的开发阶段,但未来可期。我们鼓励你去尝试这个创新的工具,亲身感受其带来的便利,并考虑为此项目贡献自己的一份力量。不要在这场革命中袖手旁观,而应该积极参与其中。现在就去 pyspark.ai 上探索和体验英语 SDK 的强大功能吧。你的参与和洞见,将为扩大 Apache Spark 的影响力做出重要贡献。